JUC
本文是一篇围绕 Java 并发编程(JUC)的系统化学习笔记,覆盖进程线程、线程创建与状态、管程模型、Java 内存模型、无锁并发、不可变对象、并发工具类以及并发包等内容。原文保留了大量示例、源码片段与过程性分析,适合作为长期查阅的并发知识手册。
阅读导引
为了便于分段阅读和快速定位,建议按下面的顺序使用本文:
- 想先建立并发基础:先看「1. 进程与线程」和「2. 线程」,理解基本概念、线程创建方式、常见 API 和生命周期。
- 想重点掌握 synchronized / wait / notify / 锁协作:重点阅读「3. 共享模型之管程」。
- 想理解可见性、有序性、原子性:重点阅读「4. 共享模型之内存」。
- 想补充 CAS、原子类与无锁思想:重点阅读「5. 共享模型之无锁」。
- 想理解线程安全容器、线程池、并发辅助类:重点阅读「7. 共享模型之工具」和「8. 并发包」。
文章导航
使用说明
这篇文章属于“概念梳理 + 示例验证 + 源码补充”的笔记组织方式,因此局部会出现重复解释、不同角度的补充说明以及实验性代码片段。阅读时可以优先关注每个大章节前的导语,再进入具体小节。
1. 进程与线程
这一部分用于建立并发编程的最基础语境,重点是区分进程、线程、并发、并行等核心概念。后续所有关于锁、内存模型、线程池的问题,本质上都建立在这里的基本认识之上。
1.1 进程与线程
进程是系统进行资源分配和保护的基本单位,线程是处理器调度和分配的基本单位
进程
- 进程是操作系统进行资源分配和保护的基本单位,它是程序的一次执行过程,拥有独立的内存空间和系统资源。每个进程都运行在独立的虚拟地址空间中,一个进程崩溃通常不会影响其他进程的运行。
线程
-
线程有时也被称为轻量级的进程
-
一个线程就是一个指令流,将指令流中的一条条指令以一定的顺序交给 CPU 执行
-
一个进程可以包含多个线程,这些线程共享进程的资源
-
在 windows 中进程是不活动的,只是作为线程的容器
线程进程对比
-
进程基本上相互独立,而线程存在于进程内,是进程的一个子集
-
进程拥有共享的资源,如内存空间等,供其内部的线程共享
-
进程间通信较为复杂
同一台计算机的进程通信称为 IPC(Inter-process communication)
- 信号量:信号量是一个计数器,用于多进程对共享数据的访问,解决同步相关的问题并避免竞争条件
- 共享存储:多个进程可以访问同一块内存空间,需要使用信号量用来同步对共享存储的访问
- 管道通信:管道是用于连接一个读进程和一个写进程以实现它们之间通信的一个共享文件 pipe 文件,该文件同一时间只允许一个进程访问,所以只支持半双工通信
- 匿名管道(Pipes):用于具有亲缘关系的父子进程间或者兄弟进程之间的通信
- 命名管道(Names Pipes):以磁盘文件的方式存在,可以实现本机任意两个进程通信,遵循 FIFO
- 消息队列:内核中存储消息的链表,由消息队列标识符标识,能在不同进程之间提供全双工通信,对比管道:
- 匿名管道存在于内存中的文件;命名管道存在于实际的磁盘介质或者文件系统;消息队列存放在内核中,只有在内核重启(操作系统重启)或者显示地删除一个消息队列时,该消息队列才被真正删除
- 读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收
不同计算机之间的进程通信,需要通过网络,并遵守共同的协议,例如 HTTP
- 套接字:与其它通信机制不同的是,可用于不同机器间的互相通信
-
线程通信相对简单,因为线程之间共享进程内的内存,一个例子是多个线程可以访问同一个共享变量
- Java 中的通信机制:volatile、wait/notify机制、join 方式、InheritableThreadLocal、MappedByteBuffer
-
线程更轻量,线程上下文切换成本一般上要比进程上下文切换低
1.2 并发并行
单核cpu下,线程实际还是串行执行的。操作系统中有一个组件叫做任务调度器,将 cpu 的时间片(windows 下时间片最小约为 15 毫秒)分给不同的程序使用,只是由于 cpu 在线程间(时间片很短)的切换非常快,人类感觉是同时运行的。总结为一句话就是: 微观串行,宏观并行 。
一般会将这种线程轮流使用 CPU 的做法称为并发, concurrent
| CPU | 时间片 1 | 时间片 2 | 时间片 3 | 时间片 4 |
|---|---|---|---|---|
| core | 线程 1 | 线程 2 | 线程 3 | 线程 4 |
多核 cpu下,每个核(core) 都可以调度运行线程,这时候线程可以是并行的。
| CPU | 时间片 1 | 时间片 2 | 时间片 3 | 时间片 4 |
|---|---|---|---|---|
| core1 | 线程 1 | 线程 2 | 线程 3 | 线程 4 |
| core2 | 线程 4 | 线程 4 | 线程 2 | 线程 2 |
引用 Rob Pike 的一段描述:
并发(concurrent)是同一时间应对(dealing with)多件事情的能力 。[在同一时刻,有多条指令在单个 CPU 上交替执行]
并行(parallel)是同一时间动手做(doing)多件事情的能力。[在同一时刻,有多条指令在多个 CPU 上同时执行]
2. 线程
这一章主要解决“线程怎么创建、怎么运行、怎么观察、怎么控制”这类基础问题。建议把它当作 Java 并发编程的入门操作层,先熟悉 API 与行为,再继续阅读后面的线程安全问题。
2.1 创建和运行线程
Thread
1 | // 构造方法的参数是给线程指定名字,推荐 |
Runnable
把【线程】和【任务】(要执行的代码)分开
- Thread 代表线程
- Runnable 可运行的任务(线程要执行的代码)
1 | // 创建任务对象 |
可以使用 lambda 精简代码
1 | // 创建任务对象 |
Thread 与 Runnable 的关系
1 | //Runnable源码 |
1 | //Thread源码(部分) |
FutureTask
FutureTask 能够接收 Callable 类型的参数,用来处理有返回结果的情况
1 | // 创建任务对象 |
源码分析
1 | //FutureTask源码(部分) |
1 | public interface RunnableFuture<V> extends Runnable, Future<V> { |
1 | //Callable源码 |
- FutureTask内置了一个Callable对象,初始化方法将指定的Callable赋给这个对象。
- FutureTask实现了Runnable接口,并重写了run方法,在run方法中调用了Callable中的call方法,并将返回值赋值给outcome变量
- get方法就是取出outcome的值。
2.2 查看进程线程的方法
windows
- 任务管理器可以查看进程和线程数,也可以用来杀死进程
- tasklist 查看进程
- tasklist | findstr (查找关键字)
- taskkill 杀死进程
- taskkill /F(彻底杀死)/PID(进程PID)
Linux
- ps -fe 查看所有进程
- ps -fT -p 查看某个进程(PID)的所有线程
- kill 杀死进程
- top 按大写 H 切换是否显示线程
- top -H -p 查看某个进程(PID)的所有线程
Java
- jps 命令查看所有 Java 进程
- jstack 查看某个 Java 进程(PID)的所有线程状态
- jconsole 来查看某个 Java 进程中线程的运行情况(图形界面)
jconsole 远程监控配置
-
需要以如下方式运行你的 java 类
java -Djava.rmi.server.hostname=`ip地址` -Dcom.sun.management.jmxremote - Dcom.sun.management.jmxremote.port=`连接端口` -Dcom.sun.management.jmxremote.ssl=是否安全连接 - Dcom.sun.management.jmxremote.authenticate=是否认证 java类
-
关闭防火墙,允许端口
-
修改 /etc/hosts 文件将 127.0.0.1 映射至主机名
如果要认证访问,还需要做如下步骤
- 复制 jmxremote.password 文件
- 修改 jmxremote.password 和 jmxremote.access 文件的权限为 600 即文件所有者可读写
- 连接时填入 controlRole(用户名),R&D(密码)
2.3 线程运行原理
运行机制
Java Virtual Machine Stacks(Java 虚拟机栈)
每个线程启动后,虚拟机就会为其分配一块栈内存
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
线程上下文切换(Thread Context Switch)
一些原因导致 CPU 不再执行当前线程,转而执行另一个线程
- 线程的 CPU 时间片用完
- 垃圾回收
- 有更高优先级的线程需要运行
- 线程自己调用了 sleep、yield、wait、join、park 等方法
程序计数器(Program Counter Register)
记录下一条 JVM 指令的执行地址,是线程私有的
当 Context Switch 发生时,需要由操作系统保存当前线程的状态(PCB 中),并恢复另一个线程的状态,包括程序计数器、虚拟机栈中每个栈帧的信息,如局部变量、操作数栈、返回地址等
JVM 规范并没有限定线程模型,以 HotSopot 为例:
- Java 的线程是内核级线程(1:1 线程模型),每个 Java 线程都映射到一个操作系统原生线程,需要消耗一定的内核资源(堆栈)
- 线程的调度是在内核态运行的,而线程中的代码是在用户态运行,所以线程切换(状态改变)会导致用户与内核态转换进行系统调用,这非常消耗性能
Java 中 main 方法启动的是一个进程也是一个主线程,main 方法里面的其他线程均为子线程,main 线程是这些线程的父线程
线程调度
线程调度指系统为线程分配处理器使用权的过程,方式有两种:协同式线程调度、抢占式线程调度(Java 选择)
协同式线程调度:线程的执行时间由线程本身控制
- 优点:线程做完任务才通知系统切换到其他线程,相当于所有线程串行执行,不会出现线程同步问题
- 缺点:线程执行时间不可控,如果代码编写出现问题,可能导致程序一直阻塞,引起系统的奔溃
抢占式线程调度:线程的执行时间由系统分配
- 优点:线程执行时间可控,不会因为一个线程的问题而导致整体系统不可用
- 缺点:无法主动为某个线程多分配时间
Java 提供了线程优先级的机制,优先级会提示(hint)调度器优先调度该线程,但这仅仅是一个提示,调度器可以忽略它。在线程的就绪状态时,如果 CPU 比较忙,那么优先级高的线程会获得更多的时间片,但 CPU 闲时,优先级几乎没作用
说明:并不能通过优先级来判断线程执行的先后顺序
优化
内核级线程调度的成本较大,所以引入了更轻量级的协程。用户线程的调度由用户自己实现(多对一的线程模型,多个用户线程映射到一个内核级线程),被设计为协同式调度,所以叫协程
- 有栈协程:协程会完整的做调用栈的保护、恢复工作,所以叫有栈协程
- 无栈协程:本质上是一种有限状态机,状态保存在闭包里,比有栈协程更轻量,但是功能有限
有栈协程中有一种特例叫纤程,在新并发模型中,一段纤程的代码被分为两部分,执行过程和调度器:
- 执行过程:用于维护执行现场,保护、恢复上下文状态
- 调度器:负责编排所有要执行的代码顺序
2.4 线程方法
Thread 类 API:
| 方法 | 功能 | 说明 |
|---|---|---|
| start() | 启动一个新线程;Java虚拟机调用此线程的run方法 | start 方法只是让线程进入就绪,里面代码不一定立刻 运行(CPU 的时间片还没分给它)。每个线程对象的 start方法只能调用一次,如果调用了多次会出现 IllegalThreadStateException |
| run() | 线程启动后调用该方法 | 如果在构造 Thread 对象时传递了 Runnable 参数,则 线程启动后会调用 Runnable 中的 run 方法,否则默认不执行任何操作。但可以创建 Thread 的子类对象, 来覆盖默认行为 |
| setName(String name) | 给当前线程取名字 | |
| getName() | 获取当前线程的名字。线程存在默认名称:子线程是Thread-索引,主线程是main | |
| currentThread() | 获取当前线程对象,代码在哪个线程中执行 | |
| sleep(long time) | 让当前线程休眠多少毫秒再继续执行。Thread.sleep(0) : 让操作系统立刻重新进行一次cpu竞争 | |
| yield() | 提示线程调度器让出当前线程对CPU的使用 | 主要是为了测试和调试 |
| getPriority() | 返回此线程的优先级 | |
| setPriority(int priority) | 更改此线程的优先级,常用1、5、10 | java中规定线程优先级是1~10 的整数,较大的优先级 能提高该线程被 CPU 调度的机率 |
| interrupt() | 中断这个线程,异常处理机制 | |
| interrupted() | 判断当前线程是否被打断,清除打断标记 | |
| isInterrupted() | 判断当前线程是否被打断,不清除打断标记 | |
| join() | 等待这个线程结束 | |
| join(long millis) | 等待这个线程死亡millis毫秒,0意味着永远等待 | |
| isAlive() | 线程是否存活(还没有运行完毕) | |
| setDaemon(boolean on) | 将此线程标记为守护线程或用户线程 | |
| getId() | 获取线程长整型 的 id | id 唯一 |
| getState() | 获取线程状态 | Java 中线程状态是用 6 个 enum 表示,分别为: NEW, RUNNABLE, BLOCKED, WAITING, TIMED_WAITING, TERMINATED |
2.4.1 start与run
-
直接调用 run 是在主线程中执行了 run,没有启动新的线程
-
使用 start 是启动新的线程,通过新的线程间接执行 run 中的代码
1
2
3
4
5
6
7
8
9
10
11public static void main(String[] args) {
Thread t1 = new Thread("t1") {
public void run() {
log.debug("running...");
}
};
System.out.println(t1.getState());
t1.start();
System.out.println(t1.getState());
}可以看见,start方法创建了一个新线程,将线程从就绪状态切换为Runnable
NEW RUNNABLE 03:45:12.255 c.Test5 [t1] - running...
2.4.2 sleep与yield
sleep
- 调用 sleep 会让当前线程从
Running进入Timed Waiting状态(阻塞) - 其它线程可以使用 interrupt 方法打断正在睡眠的线程,这时 sleep 方法会抛出 InterruptedException
1 | public static void main(String[] args) throws InterruptedException { |
输出结果:
03:47:18.141 c.Test7 [t1] - enter sleep... 03:47:19.132 c.Test7 [main] - interrupt... 03:47:19.132 c.Test7 [t1] - wake up... java.lang.InterruptedException: sleep interrupted at java.lang.Thread.sleep(Native Method) at cn.itcast.test.Test7$1.run(Test7.java:14)
- 睡眠结束后的线程未必会立刻得到执行,需要抢占 CPU
- 建议用 TimeUnit 的 sleep 代替 Thread 的 sleep 来获得更好的可读性,其底层还是sleep方法。
1 |
|
- 在循环访问锁的过程中,可以加入sleep让线程阻塞时间,防止大量占用cpu资源。
yield
- 调用 yield 会让当前线程从 Running 进入 Runnable 就绪状态,然后调度执行其它线程
- 具体的实现依赖于操作系统的任务调度器
线程优先级
- 线程优先级会提示(hint)调度器优先调度该线程,但它仅仅是一个提示,调度器可以忽略它
- 如果 cpu 比较忙,那么优先级高的线程会获得更多的时间片,但 cpu 闲时,优先级几乎没作用
测试优先级和yield
1 |
|
测试结果:
#优先级 ---->1 283500 ---->2 374389 #yield ---->1 119199 ---->2 101074
可以看出,线程优先级和yield会对线程获取cpu时间片产生一定影响,但不会影响太大。
*应用之限制
1. sleep 实现
在没有利用 cpu 来计算时,不要让 while(true) 空转浪费 cpu,这时可以使用 yield 或 sleep 来让出 cpu 的使用权 给其他程序
1 | while(true) { |
- 可以用 wait 或 条件变量达到类似的效果
- 不同的是,后两种都需要加锁,并且需要相应的唤醒操作,一般适用于要进行同步的场景
- sleep 适用于无需锁同步的场景
2. wait 实现
1 | synchronized(锁对象) { |
3. 条件变量实现
1 | lock.lock(); |
2.4.3 join
下面的代码执行,打印 r 是什么?
1 | static int r = 0; |
分析
- 因为主线程和线程 t1 是并行执行的,t1 线程需要 1 秒之后才能算出 r=10
- 而主线程一开始就要打印 r 的结果,所以只能打印出 r=0
解决方法
- 用 join,加在 t1.start() 之后即可
*应用之同步
以调用方角度来讲,如果
- 需要等待结果返回,才能继续运行就是同步
- 不需要等待结果返回,就能继续运行就是异步
1. 等待多个结果
问,下面代码 cost 大约多少秒?
1 | static int r1 = 0; |
分析
- 第一个 join:等待 t1 时, t2 并没有停止, 而在运行
- 第二个 join:1s 后, 执行到此, t2 也运行了 1s, 因此也只需再等待 1s
如果颠倒两个 join 呢?
最终都是输出
20:45:43.239 [main] c.TestJoin - r1: 10 r2: 20 cost: 2005

2. 有时效的join
当线程执行时间没有超过join设定时间
1 | static int r1 = 0; |
输出
20:48:01.320 [main] c.TestJoin - r1: 10 r2: 0 cost: 1010
当执行时间超时
1 | static int r1 = 0; |
输出
20:52:15.623 [main] c.TestJoin - r1: 0 r2: 0 cost: 1502
3. 原理
public final void join():等待这个线程结束
原理:调用者轮询检查线程 alive 状态,t1.join() 等价于:
1 | // Thread类中的join()方法实现 |
- join 方法是被 synchronized 修饰的,本质上是一个对象锁,这意味着它使用对象的内置锁(monitor lock)来实现同步,调用join()方法时,当前线程会获取调用join()方法的那个线程对象的内置锁;join()方法内部会调用wait(),使当前线程等待,wait()释放的是当前线程对象的内置锁,而不是调用join()方法的线程所持有的任何其他锁
- 当调用某个线程(t1)的 join 方法后,该线程(t1)抢占到 CPU 资源,就不再释放,直到线程执行完毕
1 | // 伪代码说明 |
线程同步:
- join 实现线程同步,因为会阻塞等待另一个线程的结束,才能继续向下运行
- 需要外部共享变量,不符合面向对象封装的思想
- 必须等待线程结束,不能配合线程池使用
- Future 实现同步,get() 方法阻塞等待执行结果
- main 线程接收结果
- get 方法是让调用线程同步等待
2.4.4 interrupt
Interrupt说明
interrupt的本质是将线程的打断标记设为true,并调用线程的三个parker对象(C++实现级别)unpark该线程。
基于以上本质,有如下说明:
-
打断线程不等于中断线程,有以下两种情况:
- 打断正在运行中的线程并不会影响线程的运行,但如果线程监测到了打断标记为true,可以自行决定后续处理。
- 打断阻塞中的线程会让此线程产生一个
InterruptedException异常,结束线程的运行。但如果该异常被线程捕获住,该线程依然可以自行决定后续处理(终止运行,继续运行,做一些善后工作等等)
public void interrupt():打断这个线程,异常处理机制
public static boolean interrupted():判断当前线程是否被打断,打断返回 true,清除打断标记,连续调用两次一定返回 false
public boolean isInterrupted():判断当前线程是否被打断,不清除打断标记
打断的线程会发生上下文切换,操作系统会保存线程信息,抢占到 CPU 后会从中断的地方接着运行(打断不是停止)
1. 打断sleep,wait,join 的线程
这几个方法都会让线程进入阻塞状态,打断线程会清空打断状态(false),以 sleep 为例
1 | public static void main(String[] args) throws InterruptedException { |
2. 打断正常运行的线程
打断正常运行的线程, 不会清空打断状态(true)
1 | public static void main(String[] args) throws Exception { |
3. 打断 park 线程
park 作用类似 sleep,打断 park 线程,不会清空打断状态(true)
1 | private static void test3() throws InterruptedException { |
如果打断标记已经是 true, 则 park 会失效
1 | private static void test4()throws InterruptedException { |
输出
23:15:37.109 [Thread-0] INFO com.lxd.juc.TPTVolatile -- park... 23:15:38.110 [Thread-0] INFO com.lxd.juc.TPTVolatile -- 打断状态:true 23:15:38.114 [Thread-0] INFO com.lxd.juc.TPTVolatile -- park... 23:15:38.115 [Thread-0] INFO com.lxd.juc.TPTVolatile -- 打断状态:true 23:15:38.115 [Thread-0] INFO com.lxd.juc.TPTVolatile -- park... 23:15:38.115 [Thread-0] INFO com.lxd.juc.TPTVolatile -- 打断状态:true 23:15:38.115 [Thread-0] INFO com.lxd.juc.TPTVolatile -- park... 23:15:38.115 [Thread-0] INFO com.lxd.juc.TPTVolatile -- 打断状态:true 23:15:38.115 [Thread-0] INFO com.lxd.juc.TPTVolatile -- park... 23:15:38.115 [Thread-0] INFO com.lxd.juc.TPTVolatile -- 打断状态:true
可以修改获取打断状态方法,使用
Thread.interrupted(),清除打断标记
*模式之两阶段终止
终止模式之两阶段终止模式:Two Phase Termination
目标:在一个线程 T1 中如何优雅终止线程 T2?优雅指的是给 T2 一个料理后事的机会。
错误思想:
- 使用线程对象的 stop() 方法停止线程:stop 方法会真正杀死线程,如果这时线程锁住了共享资源,当它被杀死后就再也没有机会释放锁,其它线程将永远无法获取锁
- 使用 System.exit(int) 方法停止线程:目的仅是停止一个线程,但这种做法会让整个程序都停止
两阶段终止模式图示:
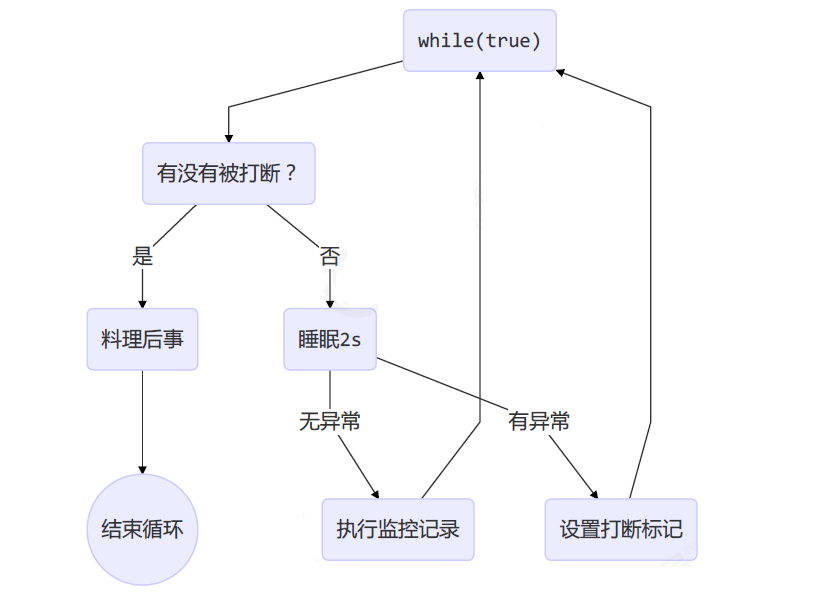
1. 利用 isInterrupted
interrupt 可以打断正在执行的线程,无论这个线程是在 sleep,wait,还是正常运行
1 |
|
调用
1 | public class Test { |
结果
23:06:45.164 [监控线程] INFO com.lxd.rbac.TwoPhaseTermination -- 执行监控记录 23:06:46.172 [监控线程] INFO com.lxd.rbac.TwoPhaseTermination -- 执行监控记录 23:06:47.176 [监控线程] INFO com.lxd.rbac.TwoPhaseTermination -- 执行监控记录 23:06:47.659 [main] INFO com.lxd.rbac.TwoPhaseTermination -- stop 23:06:47.660 [监控线程] INFO com.lxd.rbac.TwoPhaseTermination -- 料理后事
2. 利用停止标记
1 | // 停止标记用 volatile 是为了保证该变量在多个线程之间的可见性 |
调用
1 | public static void main(String[] args) throws InterruptedException { |
结果
23:09:29.477 [监控线程] INFO com.lxd.rbac.TPTVolatile -- 执行监控记录 23:09:30.484 [监控线程] INFO com.lxd.rbac.TPTVolatile -- 执行监控记录 23:09:31.488 [监控线程] INFO com.lxd.rbac.TPTVolatile -- 执行监控记录 23:09:31.973 [main] INFO com.lxd.rbac.TPTVolatile -- stop 23:09:31.973 [监控线程] INFO com.lxd.rbac.TPTVolatile -- 料理后事
2.4.5 不推荐使用的方法
这些方法已过时,容易破坏同步代码块,造成线程死锁:
-
public final void stop():停止线程运行废弃原因:方法粗暴,除非可能执行 finally 代码块以及释放 synchronized 外,线程将直接被终止,如果线程持有 JUC 的互斥锁可能导致锁来不及释放,造成其他线程永远等待的局面 -
public final void suspend():挂起(暂停)线程运行废弃原因:如果目标线程在暂停时对系统资源持有锁,则在目标线程恢复之前没有线程可以访问该资源,如果恢复目标线程的线程在调用 resume 之前会尝试访问此共享资源,则会导致死锁 -
public final void resume():恢复线程运行
2.4.6 主线程与守护线程
默认情况下,Java 进程需要等待所有线程都运行结束,才会结束。有一种特殊的线程叫做守护线程,只要其它非守护线程运行结束了,即使守护线程的代码没有执行完,也会强制结束。
用户线程:平常创建的普通线程
守护线程:服务于用户线程,只要其它非守护线程运行结束了,即使守护线程代码没有执行完,也会强制结束。守护进程是脱离于终端并且在后台运行的进程,脱离终端是为了避免在执行的过程中的信息在终端上显示
说明:当运行的线程都是守护线程,Java 虚拟机将退出,因为普通线程执行完后,JVM 是守护线程,不会继续运行下去
public final void setDaemon(boolean on):如果是 true ,将此线程标记为守护线程
1 |
|
结果
23:22:18.478 [main] INFO com.lxd.juc.TestDaemon -- 开始运行... 23:22:18.479 [daemon] INFO com.lxd.juc.TestDaemon -- 开始运行... 23:22:19.480 [main] INFO com.lxd.juc.TestDaemon -- 运行结束...
- 垃圾回收器线程就是一种守护线程
- Tomcat 中的 Acceptor 和 Poller 线程都是守护线程,所以 Tomcat 接收到 shutdown 命令后,不会等待它们处理完当前请求
2.5 线程状态
五种状态
这是从 操作系统 层面来描述的

- 【初始状态】仅是在语言层面创建了线程对象,还未与操作系统线程关联
- 【可运行状态】(就绪状态)指该线程已经被创建(与操作系统线程关联),可以由 CPU 调度执行
- 【运行状态】指获取了 CPU 时间片运行中的状态
- 当 CPU 时间片用完,会从【运行状态】转换至【可运行状态】,会导致线程的上下文切换
- 【阻塞状态】
- 如果调用了阻塞 API,如 BIO 读写文件,这时该线程实际不会用到 CPU,会导致线程上下文切换,进入 【阻塞状态】
- 等 BIO 操作完毕,会由操作系统唤醒阻塞的线程,转换至【可运行状态】
- 与【可运行状态】的区别是,对【阻塞状态】的线程来说只要它们一直不唤醒,调度器就一直不会考虑 调度它们
- 【终止状态】表示线程已经执行完毕,生命周期已经结束,不会再转换为其它状态
六种状态
这是从 Java API 层面来描述的
java.lang.Thread.State 这个枚举中给出了六种线程状态:
| 线程状态 | 导致状态发生条件 |
|---|---|
| NEW(新建) | 线程刚被创建,但是并未启动,还没调用 start 方法,只有线程对象,没有线程特征 |
| Runnable(可运行) | 线程可以在 Java 虚拟机中运行的状态,可能正在运行自己代码,也可能没有,这取决于操作系统处理器,调用了 t.start() 方法:就绪(经典叫法) |
| Blocked(阻塞) | 当一个线程试图获取一个对象锁,而该对象锁被其他的线程持有,则该线程进入 Blocked 状态;当该线程持有锁时,该线程将变成 Runnable 状态 |
| Waiting(无限等待) | 一个线程在等待另一个线程执行一个(唤醒)动作时,该线程进入 Waiting 状态,进入这个状态后不能自动唤醒,必须等待另一个线程调用 notify 或者 notifyAll 方法才能唤醒 |
| Timed Waiting (限期等待) | 有几个方法有超时参数,调用将进入 Timed Waiting 状态,这一状态将一直保持到超时期满或者接收到唤醒通知。带有超时参数的常用方法有 Thread.sleep 、Object.wait |
| Teminated(结束) | run 方法正常退出而死亡,或者因为没有捕获的异常终止了 run 方法而死亡 |
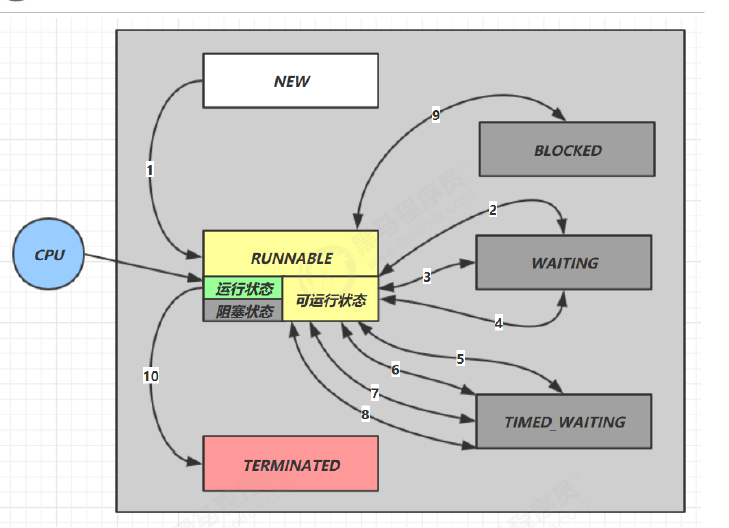
-
NEW 线程刚被创建,但是还没有调用 start() 方法
-
RUNNABLE 当调用了 start() 方法之后,注意,Java API 层面的 RUNNABLE 状态涵盖了 操作系统 层面的 【可运行状态】、【运行状态】和【阻塞状态】(由于 BIO 导致的线程阻塞,在 Java 里无法区分,仍然认为 是可运行)
-
BLOCKED , WAITING , TIMED_WAITING 都是 Java API 层面对【阻塞状态】的细分,后面会在状态转换一节 详述
-
TERMINATED 当线程代码运行结束
3. 共享模型之管程
这一章是理解 Java 线程协作与线程安全的核心部分,重点围绕
synchronized、对象监视器、wait/notify、保护性暂停、生产者消费者等经典模型展开。阅读时建议把“互斥”和“协作”分开理解。
3.1 共享带来的问题
两个线程对初始值为 0 的静态变量一个做自增,一个做自减,各做 5000 次,结果是 0 吗?
1 | static int counter = 0; |
问题分析
以上的结果可能是正数、负数、零。
因为 Java 中对静态变量的自增,自减并不是原子操作,要彻底理解,必须从字节码来进行分析
例如对于 i++ 而言(i 为静态变量),实际会产生如下的 JVM 字节码指令:
1 | getstatic i // 获取静态变量i的值 |
而对应 i-- 也是类似:
1 | getstatic i // 获取静态变量i的值 |
而 Java 的内存模型如下,完成静态变量的自增,自减需要在主存和工作内存中进行数据交换:
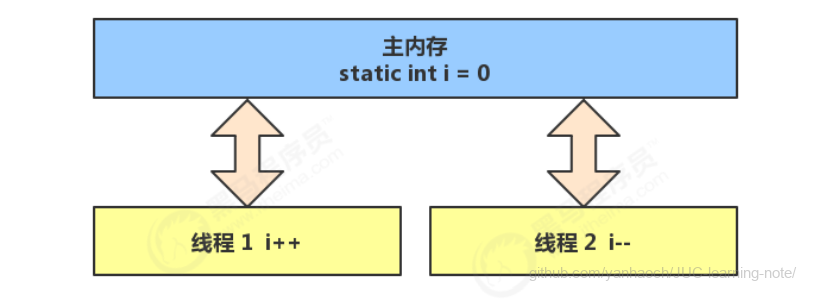
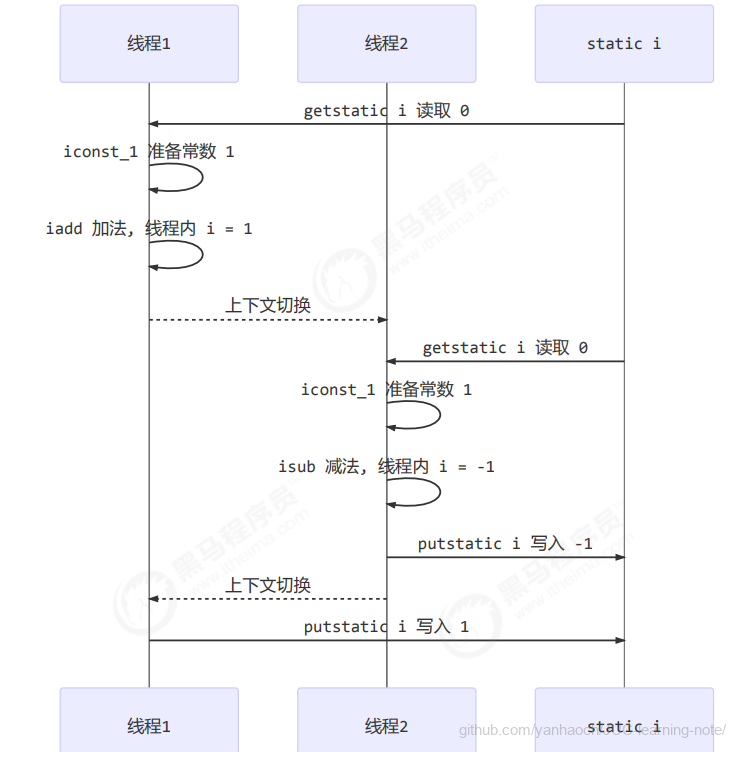
如果是单线程以上 8 行代码是顺序执行(不会交错)没有问题:
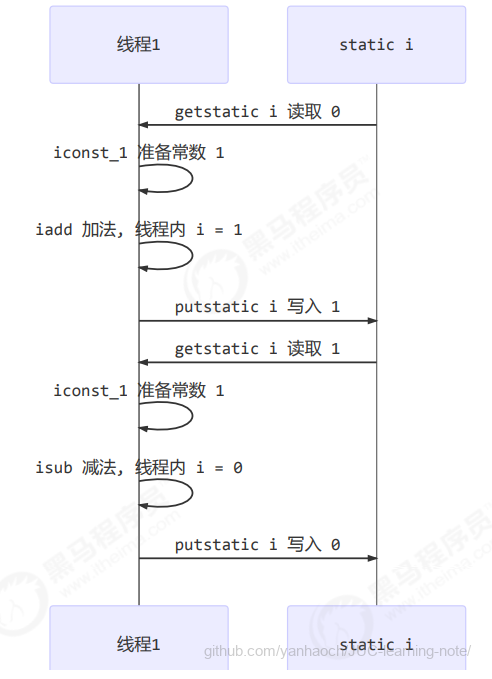
但多线程下这 8 行代码可能交错运行
出现负数的情况
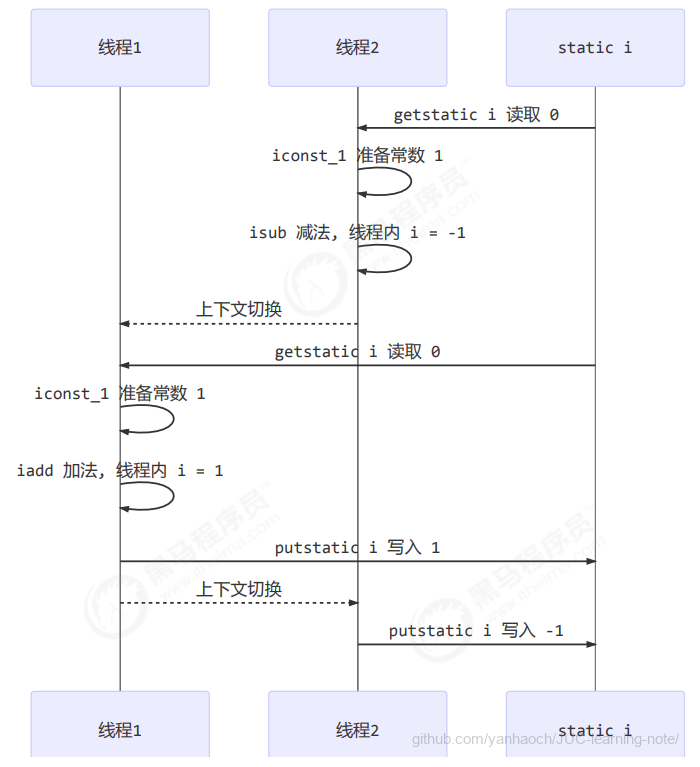
出现正数的情况
临界区 Critical Section
- 一段程序运行多个线程本身是没有问题的
- 问题出在多个线程访问**
共享资源**- 多个线程读**
共享资源**其实也没有问题 - 在多个线程对**
共享资源**读写操作时发生指令交错,就会出现问题
- 多个线程读**
- 一段代码块内如果存在对共享资源的多线程读写操作,称这段代码块为**
临界区**
1 | static int counter = 0; |
竞态条件 Race Condition
多个线程在临界区内执行,由于代码的**执行序列不同而导致结果无法预测,称之为发生了竞态条件**
3.2 synchronized解决方案
为了避免临界区的竞态条件发生,有多种手段可以达到目的。
- 阻塞式的解决方案:synchronized,Lock
- 非阻塞式的解决方案:原子变量
本次课使用阻塞式的解决方案:synchronized,来解决上述问题,即俗称的【对象锁】,它采用互斥的方式让同一时刻至多只有一个线程能持有【对象锁】,其它线程再想获取这个【对象锁】时就会阻塞住。这样就能保证拥有锁的线程可以安全的执行临界区内的代码,不用担心线程上下文切换
注意
虽然 java 中互斥和同步都可以采用 synchronized 关键字来完成,但它们还是有区别的:
- 互斥的核心目标是解决竞态条件问题,确保同一时刻只有一个线程能够访问共享资源或执行临界区代码。
- 同步关注的是线程间的执行顺序和协作,确保某些操作按照特定顺序执行。
3.2.1 synchronized
语法
1 | synchronized(对象) // 线程1, 线程2(blocked) |
解决
1 | static int counter = 0; |
图示流程
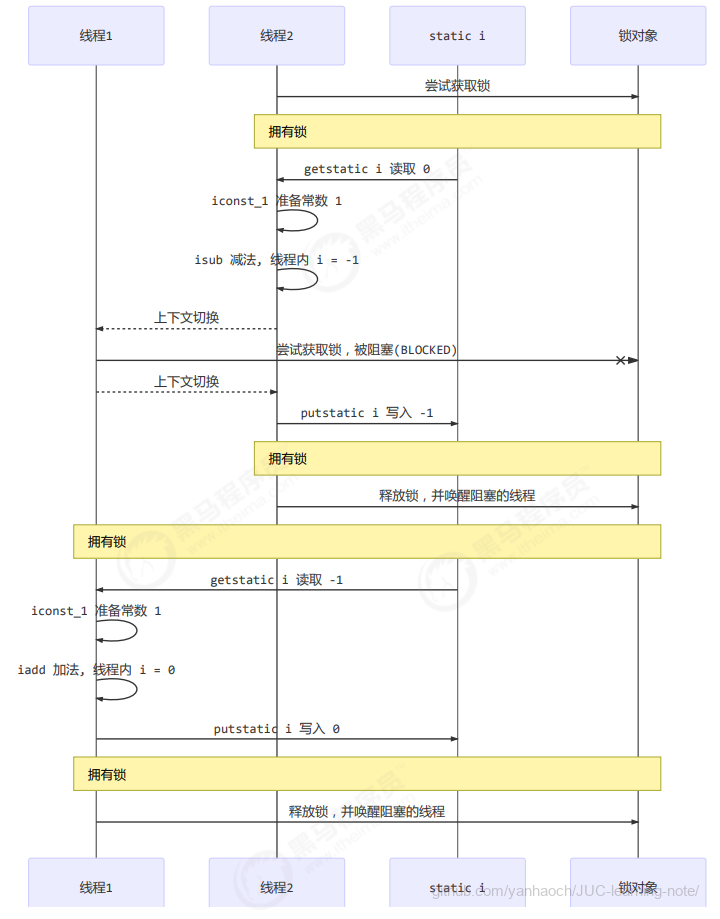
synchronized 实际是用对象锁保证了临界区内代码的原子性,临界区内的代码对外是不可分割的,不会被线程切换所打断。
面向对象改进
把需要保护的共享变量放入一个类
1 | class Room { |
3.2.2 方法上的 synchronized
把出现线程安全问题的核心方法锁起来,每次只能一个线程进入访问
synchronized 修饰的方法的不具备继承性
-
若父类方法被 synchronized 修饰,子类重写该方法时不会自动继承同步修饰符。子类方法需显式添加 synchronized 才能保证线程安全。
-
当子类重写父类同步方法并也添加 synchronized 时,两者的锁对象均为子类实例(即
this),因此是同一把锁。
用法:直接给方法加上一个修饰符 synchronized
同步方法底层也是有锁对象的:
-
如果方法是实例方法:同步方法默认用
this作为的锁对象1
2
3
4
5
6
7
8
9
10
11
12
13class Test{
public synchronized void test() {
}
}
//等价于
class Test{
public void test() {
synchronized(this) {
}
}
}反编译的结果如下图所示,可以看到 test 方法的 flag 包含
ACC_SYNCHRONIZED标志位public synchronized void test(); descriptor: ()V flags: (0x0021) ACC_PUBLIC, ACC_SYNCHRONIZED Code: stack=0, locals=1, args_size=1 0: return LineNumberTable: line 6: 0JVM 对于方法级别的同步是隐式的,是方法调用和返回值的一部分。同步方法在运行时常量池的 method_info 结构中由
ACC_SYNCHRONIZED标志来区分,它由方法调用指令来检查。当调用设置了 ACC_SYNCHRONIZED 标志位的方法时,调用线程会获取 monitor,调用方法本身,再退出 monitor。 -
如果方法是静态方法:同步方法默认用
类名.class作为的锁对象1
2
3
4
5
6
7
8
9
10
11
12class Test{
public synchronized static void test() {
}
}
等价于
class Test{
public static void test() {
synchronized(Test.class) {
}
}
}
3.2.3 线程八锁
线程八锁就是考察 synchronized 锁住的是哪个对象
说明:主要关注锁住的对象是不是同一个
- 锁住类对象,所有类的实例的方法都是安全的,类的所有实例都相当于同一把锁
- 锁住 this 对象,只有在当前实例对象的线程内是安全的,如果有多个实例就不安全
1️⃣ 12 或 21
1 | class Number{ |
2️⃣ 1s后12,或 2 1s后 1
1 | class Number{ |
3️⃣ 3 1s 12 或 23 1s 1 或 32 1s 1
1 | class Number{ |
4️⃣ 2 1s 后 1
1 | class Number{ |
5️⃣ 2 1s 后 1
1 | class Number{ |
6️⃣ 1s 后12,或 2 1s后 1
1 | class Number{ |
7️⃣ 2 1s 后 1
1 | class Number{ |
8️⃣ 1s 后12,或 2 1s后 1
1 | class Number{ |
3.3 变量的线程安全分析
成员变量和静态变量是否线程安全?
- 如果它们没有共享,则线程安全
- 如果它们被共享了,根据它们的状态是否能够改变,又分两种情况
- 如果只有读操作,则线程安全
- 如果有读写操作,则这段代码是临界区,需要考虑线程安全
3.3.1 成员变量线程安全分析
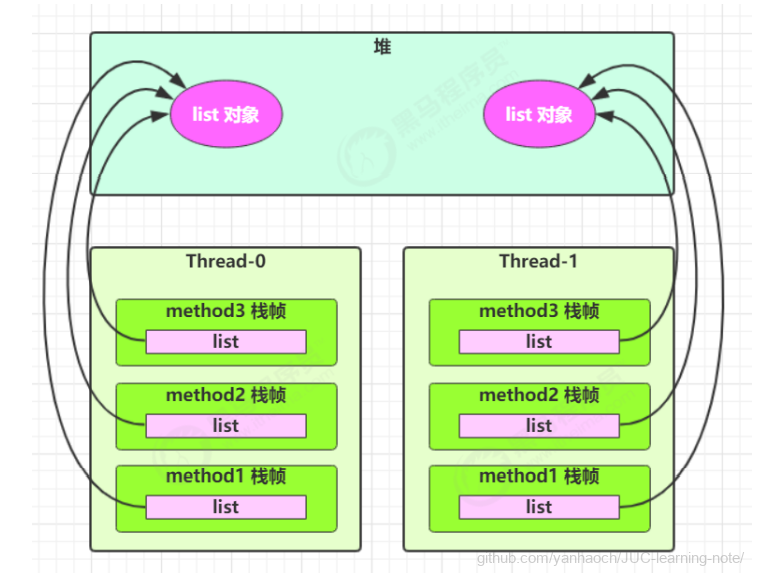
1 | class ThreadUnsafe { |
执行
1 | static final int THREAD_NUMBER = 2; |
其中一种情况是,如果线程2 还未 add,线程1 remove 就会报错:
Exception in thread "Thread1" java.lang.IndexOutOfBoundsException: Index: 0, Size: 0 at java.util.ArrayList.rangeCheck(ArrayList.java:657) at java.util.ArrayList.remove(ArrayList.java:496) at cn.itcast.n6.ThreadUnsafe.method3(TestThreadSafe.java:35) at cn.itcast.n6.ThreadUnsafe.method1(TestThreadSafe.java:26) at cn.itcast.n6.TestThreadSafe.lambda$main$0(TestThreadSafe.java:14) at java.lang.Thread.run(Thread.java:748)
分析:
- 无论在哪个线程中 method2 引用的都是同一个对象中的 list 成员变量
- method3 与 method2 分析相同
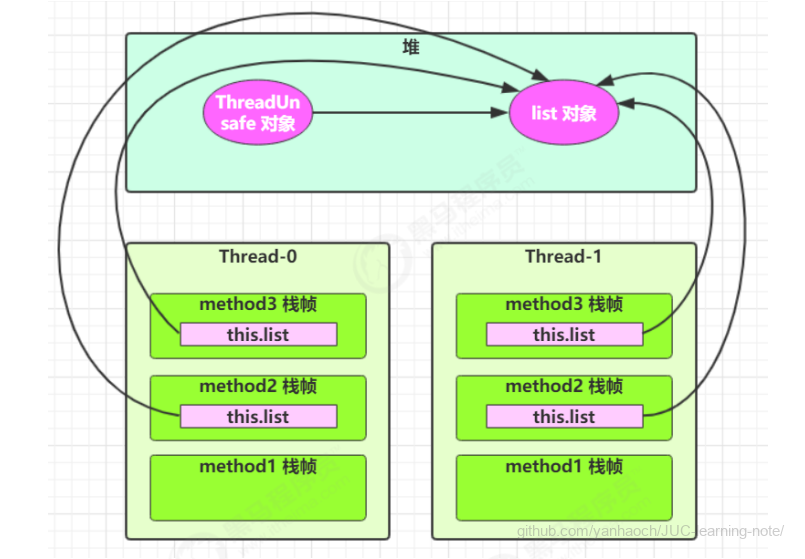
局部变量是否线程安全?
- 局部变量是线程安全的
- 但局部变量引用的对象则未必
- 如果该对象没有逃离方法的作用访问,它是线程安全的
- 如果该对象逃离方法的作用范围,需要考虑线程安全
3.3.2 局部变量线程安全分析
1 | public static void test1() { |
每个线程调用 test1() 方法时局部变量 i,会在每个线程的栈帧内存中被创建多份,因此不存在共享
1 | public static void test1(); |
如图
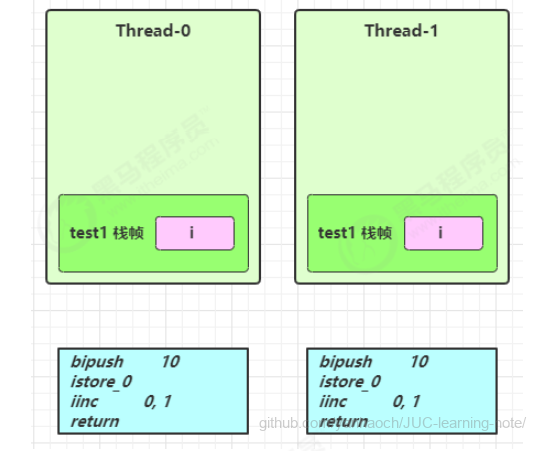
1 | class ThreadSafe { |
将 list 修改为局部变量,就不会有上述问题了
分析:
- list 是局部变量,每个线程调用时会创建其不同实例,没有共享
- 而 method2 的参数是从 method1 中传递过来的,与 method1 中引用同一个对象
- method3 的参数分析与 method2 相同
3.3.3 局部变量的引用
方法访问修饰符带来的思考,如果把 method2 和 method3 的方法修改为 public 会不会带来线程安全问题?
- 情况1:有其它线程调用 method2 和 method3
- 情况2:在 情况1 的基础上,为 ThreadSafe 类添加子类,子类覆盖 method2 或 method3 方法
1 | class ThreadSafe { |
从这个例子可以看出 private 或 final 提供【安全】的意义所在,请体会开闭原则中的【闭】
3.3.4 对象共享快速诊断指南
一、作用域追踪(核心法则)
-
局部变量:仅当前方法可见 → 不共享
1
2
3void method() {
Object localObj = new Object(); // 未逃逸 → 不共享
} -
类成员变量:实例/静态变量 → 默认共享
1
2
3
4class Shared {
Object instanceObj; // 实例共享
static Object staticObj; // 全局共享
}
二、引用传播分析(3种危险路径)
-
直接暴露:通过返回值或参数传递引用
1
2
3
4public Object leak() {
Object obj = new Object();
return obj; // 引用逃逸!
} -
间接注册:加入集合/注册回调
1
2
3
4void register() {
Object obj = new Object();
eventBus.register(obj); // 隐式共享
} -
跨线程传递:提交给线程池/异步任务
1
2
3
4void asyncTask() {
List data = new ArrayList();
executor.execute(() -> use(data)); // 线程共享
}
三、线程安全注解检测(开发规范)
@GuardedBy注解
-
作用
明确标识变量或方法的访问必须持有指定锁(显式锁/内置锁),用于防止并发访问冲突。 -
典型用法
1
2
3
4
5
6
7
8
private List<String> sharedList = new ArrayList<>();
public void addItem(String item) {
synchronized (lock) { // 必须与注解声明的锁一致
sharedList.add(item);
}
} -
检测要点
- 静态代码分析工具(如ErrorProne)会验证锁的实际使用是否与注解匹配。
- 锁类型支持:
this、Class对象、显式Lock实例或字符串指定的锁名。
@Immutable注解
-
作用
标记不可变类(所有字段final且无状态),保证线程安全无需同步。 -
验证条件
- 所有字段必须声明为
final。 - 字段类型本身不可变(如
String)或引用对象的内部状态不可变。 - 无方法能修改对象状态(无
setter方法)。
- 所有字段必须声明为
-
示例
1
2
3
4
5
6
7
8
9
10
11
public final class SafePoint {
private final int x;
private final int y; // 基本类型+final满足条件
public SafePoint(int x, int y) {
this.x = x;
this.y = y;
}
// 仅提供访问方法,无修改方法
}
四、运行时验证技巧
-
HashCode监控:
1
# 通过jstack检查不同线程中相同hashCode的对象
-
内存分析工具:
1
// 使用VisualVM/YourKit查看对象引用链
3.4 常见线程安全类
- String
- Integer
- StringBuffer
- Random
- Vector
- Hashtable
- java.util.concurrent 包下的类
这里说它们是线程安全的是指,多个线程调用它们同一个实例的某个方法时,是线程安全的。也可以理解为
- 它们的每个方法是原子的
- 但
注意它们多个方法的组合不是原子的,见后面分析
3.4.1 线程安全类方法的组合
分析下面代码是否线程安全?
1 | Hashtable table = new Hashtable(); |

3.4.2 不可变类线程安全性
String、Integer 等都是不可变类,因为其内部的状态不可以改变,因此它们的方法都是线程安全的
你或许有疑问,String 有 replace,substring 等方法【可以】改变值啊,那么这些方法又是如何保证线程安全的呢?
1. 不可变对象的定义
- 不可变性(Immutability):对象一旦创建,其内部状态(字段值)永远不能被修改。
- 例如:
String s = "abc";,"abc"这个值在内存中始终不变,任何操作(如s.replace("a", "x"))只会生成新对象"xbc",原对象"abc"依然存在。
- 例如:
2. 线程安全的本质
- 多线程环境下的风险:当多个线程同时读写共享数据时,可能因竞争导致数据不一致(如脏读、覆盖写)。
- 不可变对象的优势:
- 只读不写:所有线程只能读取
String的值,无法修改它。 - 无竞态条件:因为不存在“修改”操作,所以不需要同步(如
synchronized或锁)。
- 只读不写:所有线程只能读取
3. 具体场景分析
假设以下代码:
1 | String sharedStr = "Hello"; |
-
线程安全的表现:
- 线程1 调用
replace("H", "X"),生成新对象"Xello",原对象"Hello"不变。 - 线程2 同样生成新对象
"Xello",与线程1 的操作完全独立。
- 无冲突:两个线程互不干扰,无需加锁。
- 线程1 调用
4. 对比可变对象的线程安全问题
若 sharedStr 是 StringBuilder(可变):
1 | StringBuilder sharedStr = new StringBuilder("Hello"); |
- 风险:两个线程可能同时修改内部字符数组,导致数据丢失或异常,必须通过同步解决。
5. 不可变性的实现保障
- Java 语言机制:
String的char[] value字段是final的,初始化后引用不可变。- 所有方法(如
substring、replace)均返回新对象,绝不修改原数据。
6. 总结
“无需同步”的本质是:
- 不可变对象的所有操作都是只读的,多线程并发时不存在写竞争,因此无需额外同步措施。
- 这是最彻底的线程安全方案,优于加锁或原子类,但代价是可能产生更多对象(需权衡内存开销)。
1 | public class Immutable{ |
如果想增加一个新增的方法呢?
1 | public class Immutable{ |
3.4.3 实例分析
例1:
1 | public class MyServlet extends HttpServlet { |
例2:
1 | public class MyServlet extends HttpServlet { |
线程不安全原因分析
- Servlet单例模式导致的共享状态
- 根本机制:Servlet容器默认以单例模式管理
MyServlet,所有HTTP请求共享同一个userService实例 - 危险表现:当多个请求同时调用
doGet()时,会并发操作同一个UserServiceImpl中的count计数器 - 数据竞争:
count++操作非原子性(包含读取-修改-写入三步),可能导致计数丢失
- 成员变量未做同步保护
-
count自增问题:count++ 实际等效于:
1
2
3int tmp = count; // 读操作
tmp = tmp + 1; // 计算
count = tmp; // 写操作 -
并发后果:两个线程可能同时读取到相同的count值,导致最终结果少计
- Service层设计缺陷
- 有状态服务:
UserServiceImpl包含可变的count成员变量,但未声明为线程安全 - 设计反模式:服务层对象应设计为无状态(stateless),或将状态明确隔离
例3:
1 |
|
线程不安全核心原因
- 成员变量共享污染
-
根本机制:Spring默认单例管理切面类,所有切点方法共享同一个
start变量 -
并发场景:
1
2
3// 线程A调用method1() 线程B调用method2()
→ 写入start=100 → 写入start=200
→ 读取start(200) → 读取start(200) -
结果异常:两个方法的耗时计算都会基于错误的
start值
- 时间记录逻辑缺陷
- 竞态条件:
before()和after()方法非原子操作 - 典型问题序列:
- 线程A执行
before()设置start=100 - 线程B执行
before()覆盖start=200 - 线程A执行
after()读取到错误值200
- 线程A执行
- AOP通知设计不当
-
设计反模式:使用成员变量记录临时状态,违反无状态切面原则
-
Spring官方警告:
“Aspect instances are singletons by default. Do not use instance variables for state that needs to be maintained per-request.”
例4:
1 | public class MyServlet extends HttpServlet { |
线程安全评估(三层架构分析)
- Servlet层(MyServlet)
- 安全✅
- 虽然Servlet是单例,但
UserServiceImpl无共享状态 - 每次请求都会创建新的数据库连接(见Dao层分析)
- 虽然Servlet是单例,但
- Service层(UserServiceImpl)
- 安全✅
- 仅持有
UserDao引用,不维护可变状态 - 符合无状态服务设计原则
- 仅持有
- Dao层(UserDaoImpl)
- 安全✅
- 使用局部变量
Connection(每个线程独立) - 采用try-with-resources确保连接释放
- SQL语句作为局部变量不会共享
- 使用局部变量
例5:
1 | public class MyServlet extends HttpServlet { |
线程安全评估(三层架构分析)
- Servlet层(MyServlet)
- 安全✅
- 虽然Servlet是单例,但
UserServiceImpl无共享状态 - 每次请求理论上应该创建新的数据库连接(但Dao层实现有问题)
- 虽然Servlet是单例,但
- Service层(UserServiceImpl)
- 安全✅
- 仅持有
UserDao引用,不维护可变状态 - 符合无状态服务设计原则
- 仅持有
- Dao层(UserDaoImpl)
-
不安全❌
核心问题:
Connection作为成员变量被所有线程共享- 并发请求会导致连接对象被覆盖(可能引发:连接泄漏/事务混乱/SQL执行错乱)
- 未使用try-with-resources,连接可能无法正确关闭
例6:
1 | public class MyServlet extends HttpServlet { |
线程安全评估(关键变化分析)
- Servlet层(MyServlet)
- 安全✅
- 单例Servlet持有单例UserService
- 但UserServiceImpl现在改为方法内创建Dao(见下文分析)
- Service层(UserServiceImpl)
-
安全✅
重大改进:
1
2
3
4public void update() {
UserDao userDao = new UserDaoImpl(); // 每次调用新建Dao实例
userDao.update();
}- 将Dao实例化从成员变量改为局部变量
- 每个请求独立创建Dao对象,消除共享状态
- Dao层(UserDaoImpl)
-
理论安全⚠️(但存在严重设计缺陷)
看似安全的原因:
- 每个Dao实例被单个线程临时使用
- 连接对象(conn)虽然为成员变量,但不会被并发访问
实际隐患:
- ❌ 连接未及时关闭(可能泄漏)
- ❌ 未使用try-with-resources
- ❌ 多次调用update()会覆盖连接(单线程也会泄漏)
例7:
1 | public abstract class Test { |
其中 foo 的行为是不确定的,可能导致不安全的发生,被称之为外星方法
1 | public void foo(SimpleDateFormat sdf) { |
线程安全评估
1. 核心问题分析
- SimpleDateFormat线程不安全:SimpleDateFormat内部维护日历状态(Calendar对象),多线程并发调用parse()方法会导致:
- 日期解析错误
- 报错
NumberFormatException - 甚至程序崩溃
2. 当前代码问题
1 | public void foo(SimpleDateFormat sdf) { |
例8:
1 | private static Integer i = 0; |
线程安全问题诊断
1. 核心隐患
-
Integer对象锁失效:i++操作实际会创建新的Integer对象,导致同步块锁对象变化
1
2
3synchronized(i) { // 当i++执行后,锁对象实际上已改变
i++; // 等价于 i = Integer.valueOf(i.intValue() + 1)
} -
典型执行序列:
- 线程A锁定Integer@1001(值为0)
- 线程B阻塞等待Integer@1001
- 线程A执行i++后锁变为Integer@1002(值为1)
- 线程B获得Integer@1001的锁(此时已过时)
2. 实际后果
- 最终结果可能小于10000(如9783等随机值)
- 未实现真正的原子性保护
3.4.4 练习
卖票练习
测试下面代码是否存在线程安全问题,并尝试改正
- 将sell方法声明为synchronized即可
- 注意只将对count进行修改的一行代码用synchronized括起来也不行。对count大小的判断也必须是为原子操作的一部分,否则也会导致count值异常。
1 | public class ExerciseSell { |
另外,用下面的代码行不行,为什么?
- 不行,因为sellCount会被多个线程共享,必须使用线程安全的实现类。
1 | List<Integer> sellCount = new ArrayList<>(); |
测试脚本
1 | for /L %n in (1,1,10) do java -cp ".;C:\Users\manyh\.m2\repository\ch\qos\logback\logback�classic\1.2.3\logback-classic-1.2.3.jar;C:\Users\manyh\.m2\repository\ch\qos\logback\logback�core\1.2.3\logback-core-1.2.3.jar;C:\Users\manyh\.m2\repository\org\slf4j\slf4j�api\1.7.25\slf4j-api-1.7.25.jar" cn.itcast.n4.exercise.ExerciseSell |
说明:
- 两段没有前后因果关系的临界区代码,只需要保证各自的原子性即可,不需要括起来。
转账练习
测试下面代码是否存在线程安全问题,并尝试改正
1 | public class ExerciseTransfer { |
这样改正行不行,为什么?
- 不行,因为不同线程调用此方法,将会锁住不同的对象
1 | public synchronized void transfer(Account target, int amount) { |
正确方案
- 将transfer方法的方法体用同步代码块包裹,将Account.class设为锁对象。
3.5 操作系统的管程(Monitor)
3.5.1 管程模型
管程(Monitor) 是一种用于实现进程/线程同步与互斥的高级编程抽象
1. 管程的核心特性
- 封装性:
管程将共享变量和对这些变量的操作(如入队、出队)封装为一个整体,外部只能通过管程提供的接口访问,避免了直接操作共享数据导致的竞态条件。 - 互斥性:
管程内部同一时间仅允许一个线程执行(隐式锁机制),其他线程需等待当前线程退出管程后才能进入。 - 条件变量(Condition Variables):
通过wait、signal(或notify)等操作实现线程间的协作。线程可在条件不满足时主动阻塞(wait),并由其他线程唤醒(signal)。
- 管程 vs 其他同步机制
| 机制 | 特点 |
|---|---|
| 管程 | 高层抽象,内置互斥和条件变量,代码更简洁(如 Java synchronized 块)。 |
| 信号量 | 更灵活(可跨多个函数),但需手动管理 P/V 操作,易出错。 |
| 自旋锁 | 忙等待,适用于短临界区,但浪费 CPU 资源。 |
管程是一种在信号量机制上进行改进的并发编程模型
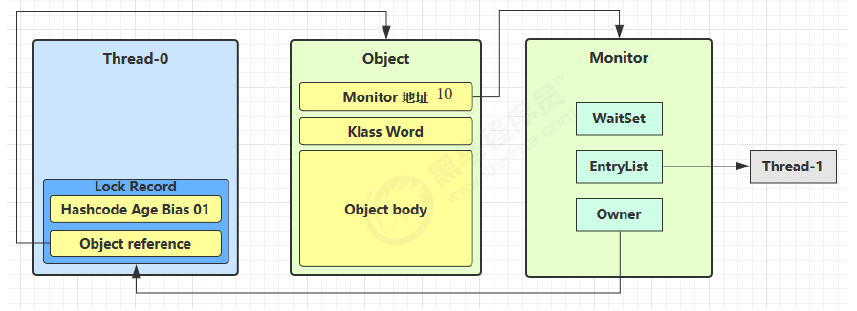
3.5.2 ObjectMonitor
JVM 中的同步就是基于进入和退出管程(Monitor)对象实现的。每个对象实例都会有一个 Monitor,Monitor 可以和对象一起创建、销毁。Monitor 是由 ObjectMonitor 实现,而 ObjectMonitor 是由 C++ 的 ObjectMonitor.hpp 文件实现,如下所示:
1 | ObjectMonitor() { |
本文使用的是 Java 17,其中有 sun.jvm.hotspot.runtime.ObjectMonitor 类,这个类有如下的初始化方法:
1 | private static synchronized void initialize(TypeDataBase db) throws WrongTypeException { |
可以和 C++ 的 ObjectMonitor.hpp 的结构对应上,如果查看 initialize 方法的调用链,能够发现很多 JVM 的内部原理,本篇文章限于篇幅和内容原因,不去详细叙述了。
3.5.3 工作原理
Monitor 被翻译为监视器或管程
每个 Java 对象都可以关联一个 Monitor 对象,Monitor 也是 class,其实例存储在堆中,如果使用 synchronized 给对象上锁(重量级)之后,该对象头的 Mark Word 中就被设置指向 Monitor 对象的指针
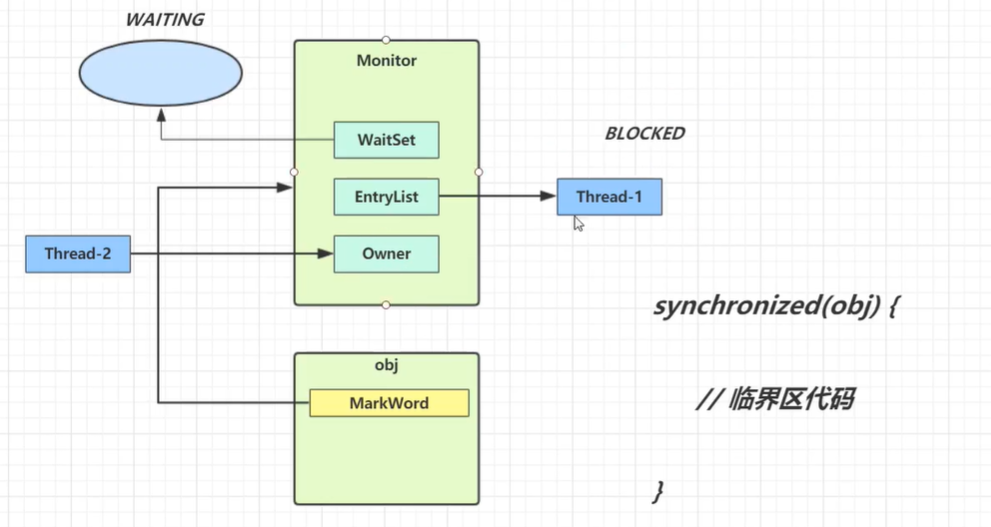
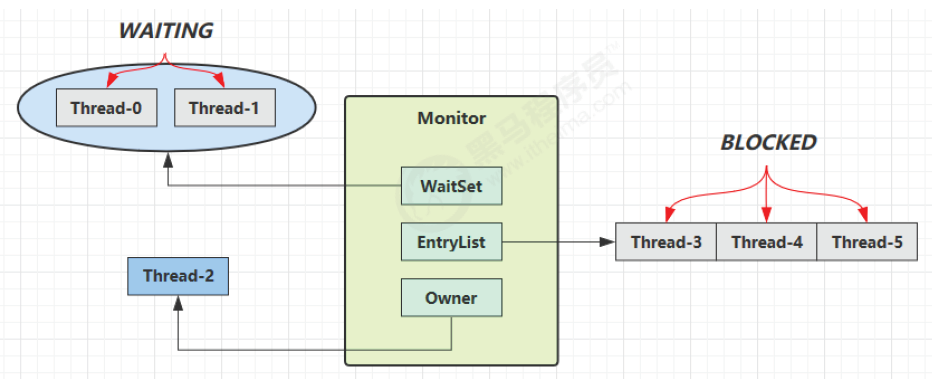
工作流程
- 当多个线程同时访问一段同步代码时,多个线程会先被存放在
EntryList集合中,处于 block 状态的线程,都会被加入到该列表。接下来当线程获取到对象的 Monitor时,Monitor 是依靠底层操作系统的Mutex Lock来实现互斥的,线程申请 Mutex 成功,则持有该 Mutex,其它线程将无法获取到该 Mutex。 - 当 Thread-2 执行 synchronized(obj) 就会将 Monitor 的所有者 Owner 置为 Thread-2,Monitor 中只能有一个 Owner,obj 对象的 Mark Word 指向 Monitor,把对象原有的 MarkWord 存入线程栈中的锁记录中(轻量级锁部分详解)
- 在 Thread-2 上锁的过程,Thread-3、Thread-4、Thread-5 也执行 synchronized(obj),就会进入 EntryList BLOCKED(双向链表)
- Thread-2 执行完同步代码块的内容,根据 obj 对象头中 Monitor 地址寻找,设置 Owner 为空,把线程栈的锁记录中的对象头的值设置回 MarkWord
- 唤醒 EntryList 中等待的线程来竞争锁,竞争是非公平的,如果这时有新的线程想要获取锁,可能直接就抢占到了,阻塞队列的线程就会继续阻塞
- WaitSet 中的 Thread-0,是以前获得过锁,但条件不满足进入 WAITING 状态的线程(wait-notify 机制)
Monitor 依赖于底层操作系统的实现,存在用户态和内核态的转换,增加了性能开销。
synchronized 必须是进入同一个对象的 Monitor 才有上述的效果
不加 synchronized 的对象不会关联监视器,不遵从以上规则
3.6 synchronized详解
3.6.1 Java对象的内存结构
- 对象头
- Mark Word
- Klass Pointer(类型指针)
- 指向对象所属类的元数据(即Class对象)
- 数组长度
- 实例数据
- 对齐填充
其中 Mark Word 记录了对象和锁有关的信息,在 64 位 JVM 中的长度是 64 位,具体信息如下图所示:

3.6.2 synchronized原理
1 | static final Object lock = new Object(); |
对应的字节码为
1 | public static void main(java.lang.String[]); |
monitorenter
官方的定义:

主要的意思是说:
每个对象都与一个 monitor 相关联。当且仅当 monitor 对象有一个所有者时才会被锁定。执行 monitorenter 的线程试图获得与 objectref 关联的 monitor 的所有权,如下所示:
- 若与 objectref 相关联的 monitor 计数为 0,线程进入 monitor 并设置 monitor 计数为 1,这个线程成为这个 monitor 的拥有者。
- 如果该线程已经拥有与 objectref 关联的 monitor,则该线程重新进入 monitor,并增加 monitor 的计数。
- 如果另一个线程已经拥有与 objectref 关联的 monitor,则该线程将阻塞,直到 monitor 的计数为零,该线程才会再次尝试获得 monitor 的所有权。
monitorexit
官方的定义:

主要的意思是说:
- 执行 monitorexit 的线程必须是与 objectref 引用的实例相关联的 monitor 的所有者。
- 线程将与 objectref 关联的 monitor 计数减一。如果计数为 0,则线程退出并释放这个 monitor。其他因为该 monitor 阻塞的线程可以尝试获取该 monitor。
3.6.3 锁的发展过程
在 JDK 1.5 之前,Java 是依靠 Synchronized 关键字实现锁功能来做到这点的。Synchronized 是 JVM 实现的一种内置锁,锁的获取和释放是由 JVM 隐式实现。
到了 JDK 1.5 版本,并发包中新增了 Lock 接口来实现锁功能,它提供了与Synchronized 关键字类似的同步功能,只是在使用时需要显示获取和释放锁。
Lock 同步锁是基于 Java 实现的,而 Synchronized 是基于底层操作系统的 Mutex Lock 实现,每次获取和释放锁操作都会带来用户态和内核态的切换,从而增加系统性能开销。因此,在锁竞争激烈的情况下,Synchronized同步锁在性能上就表现得非常糟糕,它也常被大家称为重量级锁。
特别是在单个线程重复申请锁的情况下,JDK1.5 版本的 Synchronized 锁性能要比 Lock 的性能差很多。
到了 JDK 1.6 版本之后,Java 对 Synchronized 同步锁做了充分的优化,甚至在某些场景下,它的性能已经超越了 Lock 同步锁。
3.6.4 锁升级过程
synchronized 是可重入、不公平的重量级锁,所以可以对其进行优化
无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁 // 随着竞争的增加,只能锁升级,不能降级

3.6.5 偏向锁
偏向锁的思想是偏向于让第一个获取锁对象的线程使用,这个线程之后重新获取该锁不再需要同步操作:
- 当锁对象第一次被线程获得的时候进入偏向状态,标记为 101,同时
使用 CAS 操作将线程 ID 记录到 Mark Word。如果 CAS 操作成功,这个线程以后进入这个锁相关的同步块,查看这个线程 ID 是自己的就表示没有竞争,就不需要再进行任何同步操作
例如:
1 | static final Object obj = new Object(); |
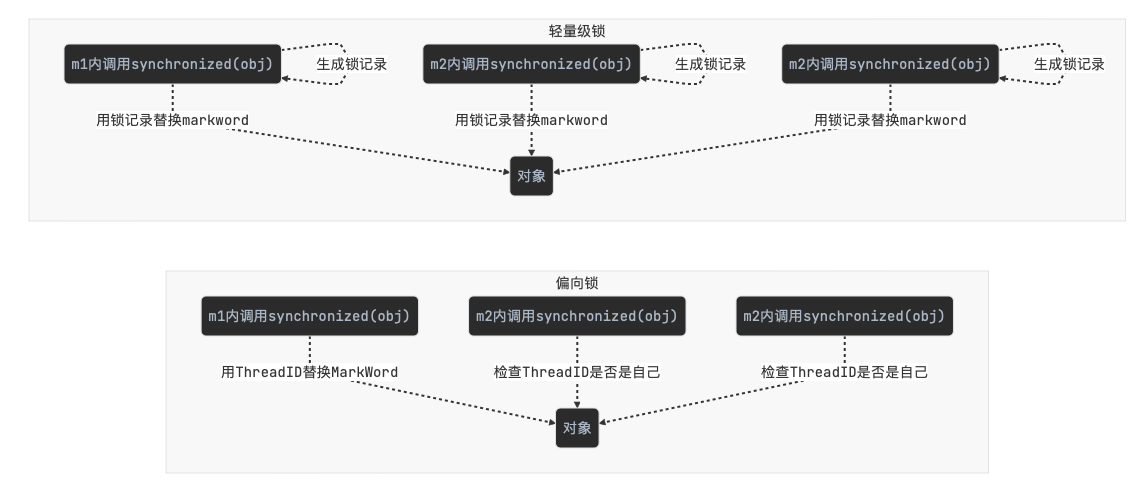
偏向状态
回忆一下对象头格式
一个对象创建时:
-
如果开启了偏向锁(默认开启),那么对象创建后,MarkWord 值为 0x05 即最后 3 位为 101,thread、epoch、age 都为 0
-
偏向锁是默认是延迟的,不会在程序启动时立即生效,如果想避免延迟,可以加 VM 参数
-XX:BiasedLockingStartupDelay=0来禁用延迟。JDK 8 延迟 4s 开启偏向锁原因:在刚开始执行代码时,会有好多线程来抢锁,如果开偏向锁效率反而降低 -
当一个对象已经计算过 hashCode,就再也无法进入偏向状态了
-
添加 VM 参数
-XX:-UseBiasedLocking禁用偏向锁 -
当有另外一个线程去尝试获取这个锁对象时,偏向状态就宣告结束,此时撤销偏向(Revoke Bias)后恢复到未锁定或轻量级锁状态
1)测试延迟特性
2)测试偏向锁
利用 jol 第三方工具来查看对象头信息
1 | // 添加虚拟机参数 -XX:BiasedLockingStartupDelay=0 |
1 | 11:08:58.117 c.TestBiased [t1] - synchronized 前 |
处于偏向锁的对象解锁后,线程 id 仍存储于对象头中
3)测试禁用
在上面测试代码运行时在添加 VM 参数 -XX:-UseBiasedLocking 禁用偏向锁
输出
1 | 11:13:10.018 c.TestBiased [t1] - synchronized 前 |
4)测试 hashCode
- 正常状态对象一开始是没有 hashCode 的,第一次调用才生成
撤销偏向锁的状态
- 调用对象的 hashCode
调用了对象的 hashCode,但偏向锁的对象 MarkWord 中存储的是线程 id,如果调用 hashCode 会导致偏向锁被撤销
- 轻量级锁会在锁记录中记录 hashCode
- 重量级锁会在 Monitor 中记录 hashCode
在调用 hashCode 后使用偏向锁,记得去掉-XX:-UseBiasedLocking
输出
1 | 11:22:10.386 c.TestBiased [main] - 调用 hashCode:1778535015 |
- 有其它线程使用偏向锁对象
当有其它线程使用偏向锁对象时,会将偏向锁升级为轻量级锁
1 | private static void test2() throws InterruptedException { |
输出
1 | [t1] - 00000000 00000000 00000000 00000000 00011111 01000001 00010000 00000101 |
- 调用 wait/notify,需要申请 Monitor,进入 WaitSet
1 | public static void main(String[] args) throws InterruptedException { |
输出
1 | [t1] - 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000101 |
批量重偏向
如果对象虽然被多个线程访问,但没有竞争,这时偏向了线程 T1 的对象仍有机会重新偏向 T2,重偏向会重置对象 的 Thread ID
当撤销偏向锁阈值超过 20 次后,jvm 会这样觉得,我是不是偏向错了呢,于是会在给这些对象加锁时重新偏向至 加锁线程
1 | private static void test3() throws InterruptedException { |
输出
1 | [t1] - 0 00000000 00000000 00000000 00000000 00011111 11110011 11100000 00000101 |
批量撤销
当撤销偏向锁阈值超过 40 次后,jvm 会觉得自己确实偏向错了,根本就不该偏向。于是整个类的所有对象 都会变为不可偏向的,新建的对象也是不可偏向的
1 | static Thread t1,t2,t3; |
JDK 15 废弃偏向锁
官方的详细说明JEP 374: Disable and Deprecate Biased Locking
当时为什么要引入偏向锁?
在过去,Java应用通常使用的都是HashTable、Vector等比较老的集合库,这类集合库大量使用了 synchronized来保证线程安全。所以偏向锁技术作为synchronized的一种优化手段,可以减少无锁竞争情况下的 开销,通过假定一个锁一直由同一线程拥有,从而避免执行比较和交换的原子操作。从历史上看,偏向锁使得 JVM 的性能得到了显著改善。
现在为什么又要废弃偏向锁?
但是,偏向锁的局限是当只有一个线程反复进入同步代码块时才能快速获得,但是当有其他线程尝试获取锁的时 候,就需要等到safepoint时,再将偏向锁撤销为无锁的状态或者升级为轻量级锁,而这个过程其实是会消耗一 定的性能的。
在高并发的场景下,频繁的撤销偏向锁和重新偏向不仅不能提升性能,还会导致性能下降,特别是在那些锁竞争较为激烈的应用中。
并且,随着Java应用程序的发展和优化,过去能够从偏向锁中获得的性能提升在当今的应用中不再明显。许多现代应用程序使用了不需要同步的集合类或更高性能的并发数据结构(如ConcurrentHashMap、CopyOnWriteArrayList等),而不再频繁地执行无争用的同步(synchronized)操作。
还有就是官方在文档中提到的,偏向锁的引入导致代码很复杂,给HotSpot虚拟机中锁相关部分与其他组件之间的交互也带来了复杂性。这种复杂性使得理解代码的各个部分变得困难,并且阻碍了在同步子系统内进行重大设计更改。因此,废弃偏向锁有助于减少复杂性,使代码更容易维护和改进。
总之,废弃偏向锁是为了减少复杂性、提高代码可维护性,并鼓励开发人员采用更现代的并发编程技术,以适应当今Java应用程序的性能需求。
参考资料
https://github.com/farmerjohngit/myblog/issues/12
https://www.cnblogs.com/LemonFive/p/11246086.html
https://www.cnblogs.com/LemonFive/p/11248248.html
3.6.6 轻量级锁
使用场景:有多个线程对同一个对象加锁,但加锁的时间是错开的(没有竞争),可以使用轻量级锁来优化,轻量级锁对使用者是透明的(不可见)
可重入锁:线程可以进入任何一个它已经拥有的锁所同步着的代码块,可重入锁最大的作用是避免死锁
轻量级锁在没有竞争时(锁重入时),每次重入仍然需要执行 CAS 操作,Java 6 才引入的偏向锁来优化
锁重入实例:假设有两个方法同步块,利用同一个对象加锁
1 | static final Object obj = new Object(); |
-
创建锁记录(Lock Record)对象,每个线程的栈帧都会包含一个锁记录的结构,存储锁定对象的 Mark Word
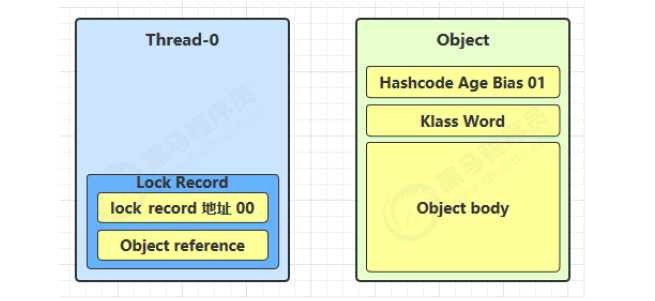
-
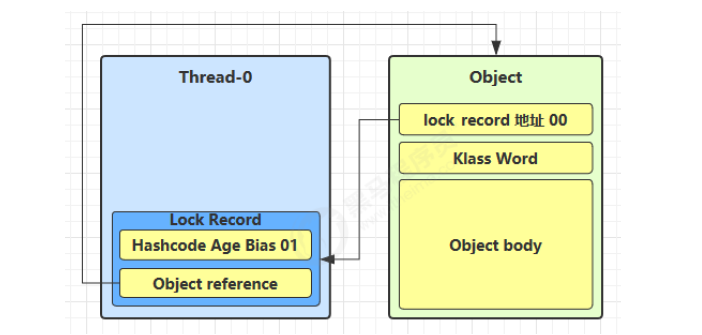
让锁记录中 Object reference 指向锁住的对象,并尝试用 CAS 替换 Object 的 Mark Word,将 Mark Word 的值存入锁记录
-
如果 CAS 替换成功,对象头中存储了锁记录地址和状态 00(轻量级锁),表示由该线程给对象加锁
-
如果 CAS 失败,有两种情况:
- 如果是其它线程已经持有了该 Object 的轻量级锁,这时表明有竞争,进入锁膨胀过程
- 如果是线程自己执行了 synchronized 锁重入,就添加一条 Lock Record 作为重入的计数
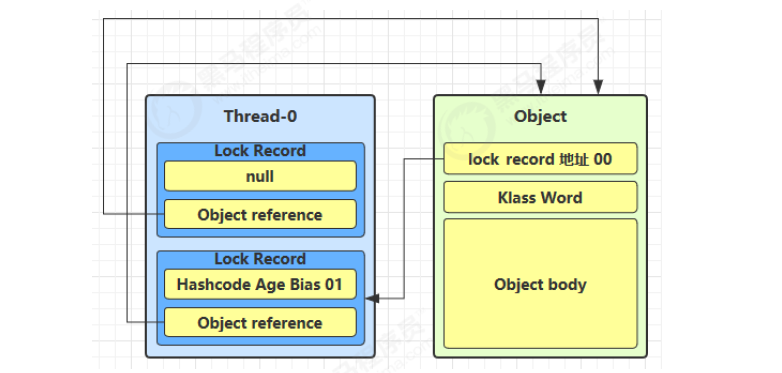
-
当退出 synchronized 代码块(解锁时)
- 如果有取值为 null 的锁记录,表示有重入,这时重置锁记录,表示重入计数减 1
- 如果锁记录的值不为 null,这时使用 CAS 将 Mark Word 的值恢复给对象头
- 成功,则解锁成功
- 失败,说明轻量级锁进行了锁膨胀或已经升级为重量级锁,进入重量级锁解锁流程
3.6.7 锁膨胀
在尝试加轻量级锁的过程中,CAS 操作无法成功,可能是其它线程为此对象加上了轻量级锁(有竞争),这时需要进行锁膨胀,将轻量级锁变为重量级锁
-
当 Thread-1 进行轻量级加锁时,Thread-0 已经对该对象加了轻量级锁
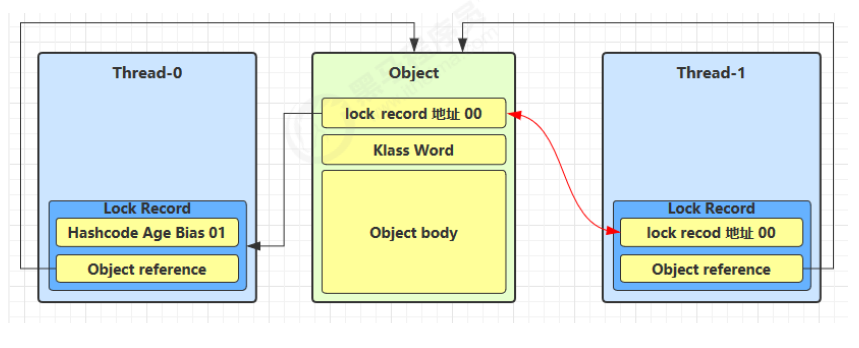
-
Thread-1 加轻量级锁失败,进入锁膨胀流程:
-
为 Object 对象申请 Monitor 锁,通过 Object 对象头获取到持锁线程,将 Monitor 的 Owner 置为 Thread-0,将 Object 的对象头指向重量级锁地址
-
然后自己进入 Monitor 的 EntryList BLOCKED
-
-
当 Thread-0 退出同步块解锁时,使用 CAS 将 Mark Word 的值恢复给对象头失败,这时进入重量级解锁流程,即按照 Monitor 地址找到 Monitor 对象,设置 Owner 为 null,唤醒 EntryList 中 BLOCKED 线程
3.7 锁优化
3.7.1 自旋锁
重量级锁竞争时,尝试获取锁的线程不会立即阻塞,可以使用自旋(默认 10 次)来进行优化,采用循环的方式去尝试获取锁
注意:
- 自旋占用 CPU 时间,单核 CPU 自旋就是浪费时间,因为同一时刻只能运行一个线程,多核 CPU 自旋才能发挥优势
- 自旋失败的线程会进入阻塞状态
优点:不会立即进入阻塞状态,减少线程上下文切换的消耗
缺点:当自旋的线程越来越多时,会不断的消耗 CPU 资源
自旋锁情况:
-
自旋成功的情况:
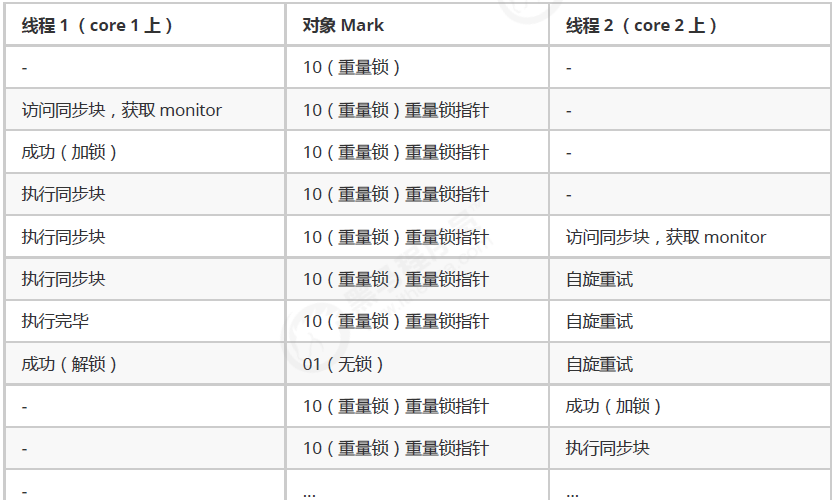
-
自旋失败的情况:
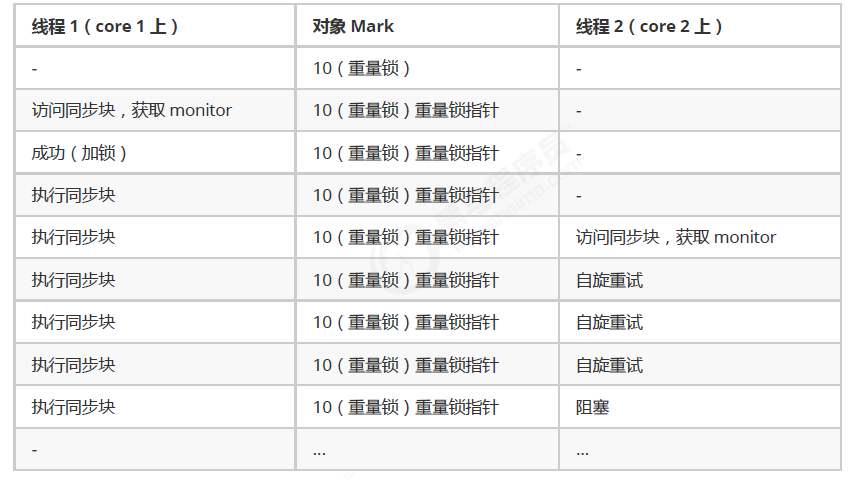
自旋锁说明:
- 在 Java 6 之后自旋锁是自适应的,比如对象刚刚的一次自旋操作成功过,那么认为这次自旋成功的可能性会高,就多自旋几次;反之,就少自旋甚至不自旋,比较智能
- Java 7 之后不能控制是否开启自旋功能,由 JVM 控制
1 | //手写自旋锁 |
3.7.2 锁消除
锁消除是指对于被检测出不可能存在竞争的共享数据的锁进行消除,这是 JVM 即时编译器的优化
锁消除主要是通过逃逸分析来支持,如果堆上的共享数据不可能逃逸出去被其它线程访问到,那么就可以把它们当成私有数据对待,也就可以将它们的锁进行消除(同步消除:JVM 逃逸分析)
1 |
|
java -jar benchmarks.jar
Benchmark Mode Samples Score Score error Units c.i.MyBenchmark.a avgt 5 1.542 0.056 ns/op c.i.MyBenchmark.b avgt 5 1.518 0.091 ns/op
java -XX:-EliminateLocks -jar benchmarks.jar
Benchmark Mode Samples Score Score error Units c.i.MyBenchmark.a avgt 5 1.507 0.108 ns/op c.i.MyBenchmark.b avgt 5 16.976 1.572 ns/op
3.7.3 锁粗化
对相同对象多次加锁,导致线程发生多次重入,频繁的加锁操作就会导致性能损耗,可以使用锁粗化方式优化
如果虚拟机探测到一串的操作都对同一个对象加锁,将会把加锁的范围扩展(粗化)到整个操作序列的外部
-
一些看起来没有加锁的代码,其实隐式的加了很多锁:
1
2
3public static String concatString(String s1, String s2, String s3) {
return s1 + s2 + s3;
} -
String 是一个不可变的类,编译器会对 String 的拼接自动优化。在 JDK 1.5 之前,转化为 StringBuffer 对象的连续 append() 操作,每个 append() 方法中都有一个同步块
1
2
3
4
5
6
7public static String concatString(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
扩展到第一个 append() 操作之前直至最后一个 append() 操作之后,只需要加锁一次就可以
3.8 wait & notify
3.8.1 基本使用
obj.wait()让进入 object 监视器的线程到 waitSet 等待obj.notify()在 object 上正在 waitSet 等待的线程中挑一个唤醒obj.notifyAll()让 object 上正在 waitSet 等待的线程全部唤醒
它们都是线程之间进行协作的手段,都属于 Object 对象的方法。必须获得此对象的锁,才能调用这几个方法
1 | final static Object obj = new Object(); |
notify 的一种结果
20:00:53.096 [Thread-0] c.TestWaitNotify - 执行.... 20:00:53.099 [Thread-1] c.TestWaitNotify - 执行.... 20:00:55.096 [main] c.TestWaitNotify - 唤醒 obj 上其它线程 20:00:55.096 [Thread-0] c.TestWaitNotify - 其它代码....
notifyAll 的结果
19:58:15.457 [Thread-0] c.TestWaitNotify - 执行.... 19:58:15.460 [Thread-1] c.TestWaitNotify - 执行.... 19:58:17.456 [main] c.TestWaitNotify - 唤醒 obj 上其它线程 19:58:17.456 [Thread-1] c.TestWaitNotify - 其它代码.... 19:58:17.456 [Thread-0] c.TestWaitNotify - 其它代码....
wait() 方法会释放对象的锁,进入 WaitSet 等待区,无限制等待,直到 notify 为止,从而让其他线程有机会获取对象的锁。
wait(long n) 有时限的等待, 到 n 毫秒后结束等待,或是被 notify
sleep(long n) 和 wait(long n)的区别?
- sleep 是 Thread 方法,而 wait 是 Object 的方法
- sleep 不需要强制和 synchronized 配合使用,但 wait 需要 和 synchronized 一起用
- sleep 在睡眠的同时,不会释放对象锁的,但 wait 在等待的时候会释放对象锁
- 它们 状态 TIMED_WAITING
step 1
1 | static final Object room = new Object(); |
思考下面的解决方案好不好,为什么?
1 | new Thread(() -> { |
输出
20:49:49.883 [小南] c.TestCorrectPosture - 有烟没?[false] 20:49:49.887 [小南] c.TestCorrectPosture - 没烟,先歇会! 20:49:50.882 [送烟的] c.TestCorrectPosture - 烟到了噢! 20:49:51.887 [小南] c.TestCorrectPosture - 有烟没?[true] 20:49:51.887 [小南] c.TestCorrectPosture - 可以开始干活了 20:49:51.887 [其它人] c.TestCorrectPosture - 可以开始干活了 20:49:51.887 [其它人] c.TestCorrectPosture - 可以开始干活了 20:49:51.888 [其它人] c.TestCorrectPosture - 可以开始干活了 20:49:51.888 [其它人] c.TestCorrectPosture - 可以开始干活了 20:49:51.888 [其它人] c.TestCorrectPosture - 可以开始干活了
- 其它干活的线程,都要一直阻塞,效率太低
- 小南线程必须睡足 2s 后才能醒来,就算烟提前送到,也无法立刻醒来
- 加了 synchronized (room) 后,就好比小南在里面反锁了门睡觉,烟根本没法送进门,main 没加 synchronized 就好像 main 线程是翻窗户进来的
- 解决方法,使用 wait - notify 机制
step 2
思考下面的实现行吗,为什么?
1 | new Thread(() -> { |
- 解决了其它干活的线程阻塞的问题
- 但如果有其它线程也在等待条件呢?
step 3
1 | new Thread(() -> { |
输出
20:53:12.173 [小南] c.TestCorrectPosture - 有烟没?[false] 20:53:12.176 [小南] c.TestCorrectPosture - 没烟,先歇会! 20:53:12.176 [小女] c.TestCorrectPosture - 外卖送到没?[false] 20:53:12.176 [小女] c.TestCorrectPosture - 没外卖,先歇会! 20:53:13.174 [送外卖的] c.TestCorrectPosture - 外卖到了噢! 20:53:13.174 [小南] c.TestCorrectPosture - 有烟没?[false] 20:53:13.174 [小南] c.TestCorrectPosture - 没干成活...
- notify 只能随机唤醒一个 WaitSet 中的线程,这时如果有其它线程也在等待,那么就可能唤醒不了正确的线程,称之为【虚假唤醒】
- 解决方法,改为 notifyAll
step 4
1 | new Thread(() -> { |
输出
20:55:23.978 [小南] c.TestCorrectPosture - 有烟没?[false] 20:55:23.982 [小南] c.TestCorrectPosture - 没烟,先歇会! 20:55:23.982 [小女] c.TestCorrectPosture - 外卖送到没?[false] 20:55:23.982 [小女] c.TestCorrectPosture - 没外卖,先歇会! 20:55:24.979 [送外卖的] c.TestCorrectPosture - 外卖到了噢! 20:55:24.979 [小女] c.TestCorrectPosture - 外卖送到没?[true] 20:55:24.980 [小女] c.TestCorrectPosture - 可以开始干活了 20:55:24.980 [小南] c.TestCorrectPosture - 有烟没?[false] 20:55:24.980 [小南] c.TestCorrectPosture - 没干成活...
- 用 notifyAll 仅解决某个线程的唤醒问题,但使用 if + wait 判断仅有一次机会,一旦条件不成立,就没有重新判断的机会了
- 解决方法,用 while + wait,当条件不成立,再次 wait
step 5
将 if 改为 while
1 | if (!hasCigarette) { |
改动后
1 | while (!hasCigarette) { |
输出
20:58:34.322 [小南] c.TestCorrectPosture - 有烟没?[false] 20:58:34.326 [小南] c.TestCorrectPosture - 没烟,先歇会! 20:58:34.326 [小女] c.TestCorrectPosture - 外卖送到没?[false] 20:58:34.326 [小女] c.TestCorrectPosture - 没外卖,先歇会! 20:58:35.323 [送外卖的] c.TestCorrectPosture - 外卖到了噢! 20:58:35.324 [小女] c.TestCorrectPosture - 外卖送到没?[true] 20:58:35.324 [小女] c.TestCorrectPosture - 可以开始干活了 20:58:35.324 [小南] c.TestCorrectPosture - 没烟,先歇会!
正确使用wait-notify套路总结
1 | synchronized(lock) { |
3.8.2 原理
- Owner 线程发现条件不满足,调用 wait 方法,即可进入 WaitSet 变为 WAITING 状态
- BLOCKED 和 WAITING 的线程都处于阻塞状态,不占用 CPU 时间片
- BLOCKED 线程会在 Owner 线程释放锁时唤醒
- WAITING 线程会在 Owner 线程调用 notify 或 notifyAll 时唤醒,唤醒后并不意味者立刻获得锁,需要进入 EntryList 重新竞争
*同步模式之保护性暂停
- 定义
即 Guarded Suspension,用在一个线程等待另一个线程的执行结果
要点
- 有一个结果需要从一个线程传递到另一个线程,让他们关联同一个 GuardedObject
- 如果有结果不断从一个线程到另一个线程那么可以使用消息队列(见生产者/消费者)
- JDK 中,join 的实现、Future 的实现,采用的就是此模式
- 因为要等待另一方的结果,因此归类到同步模式
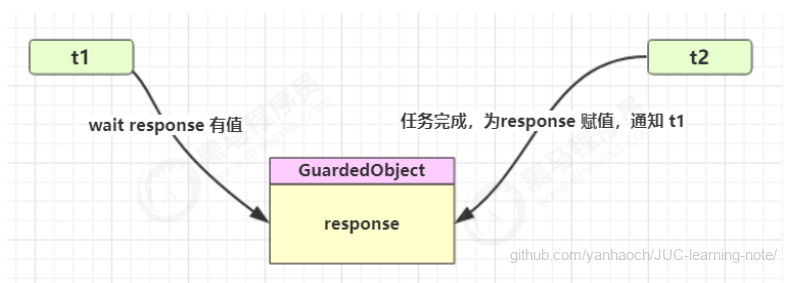
- 实现
1 | class GuardedObject { |
测试 一个线程等待另一个线程的执行结果
1 | public static void main(String[] args) { |
执行结果
20:19:47.513 [main] INFO com.lxd.juc.GuardedObject -- 等待结果... 20:19:50.515 [Thread-0] INFO com.lxd.juc.GuardedObject -- download complete... 20:19:50.515 [main] INFO com.lxd.juc.GuardedObject -- OK
- 带超时版GuardedObject
如果要控制超时时间呢
1 |
|
测试 没有超时
1 | public static void main(String[] args) { |
输出
21:02:30.373 [main] INFO com.lxd.juc.GuardedObjectV2 -- 等待结果... 21:02:30.374 [main] INFO com.lxd.juc.GuardedObjectV2 -- waitTime: 4000 21:02:33.378 [t1] INFO com.lxd.juc.GuardedObjectV2 -- download complete... 21:02:33.378 [t1] INFO com.lxd.juc.GuardedObjectV2 -- send notify... 21:02:33.379 [main] INFO com.lxd.juc.GuardedObjectV2 -- passTime:【3005】,result is null ?【false】 21:02:33.379 [main] INFO com.lxd.juc.GuardedObjectV2 -- result -> OK
测试超时
1 | // 等待时间不足 |
输出
21:02:56.988 [main] INFO com.lxd.juc.GuardedObjectV2 -- 等待结果... 21:02:56.989 [main] INFO com.lxd.juc.GuardedObjectV2 -- waitTime: 2000 21:02:58.994 [main] INFO com.lxd.juc.GuardedObjectV2 -- passTime:【2005】,result is null ?【true】 21:02:58.996 [main] INFO com.lxd.juc.GuardedObjectV2 -- waitTime: -5 21:02:58.996 [main] INFO com.lxd.juc.GuardedObjectV2 -- 等待超时 break... 21:02:58.996 [main] INFO com.lxd.juc.GuardedObjectV2 -- result -> null 21:02:59.992 [t1] INFO com.lxd.juc.GuardedObjectV2 -- download complete... 21:02:59.992 [t1] INFO com.lxd.juc.GuardedObjectV2 -- send notify...
*join原理
1 | //不带参 |
- 多任务版GuardedObject
图中 Futures 就好比居民楼一层的信箱(每个信箱有房间编号),左侧的 t0,t2,t4 就好比等待邮件的居民,右侧的 t1,t3,t5 就好比邮递员 。
如果需要在多个类之间使用 GuardedObject 对象,作为参数传递不是很方便,因此设计一个用来解耦的中间类, 这样不仅能够解耦【结果等待者】和【结果生产者】,还能够同时支持多个任务的管理。
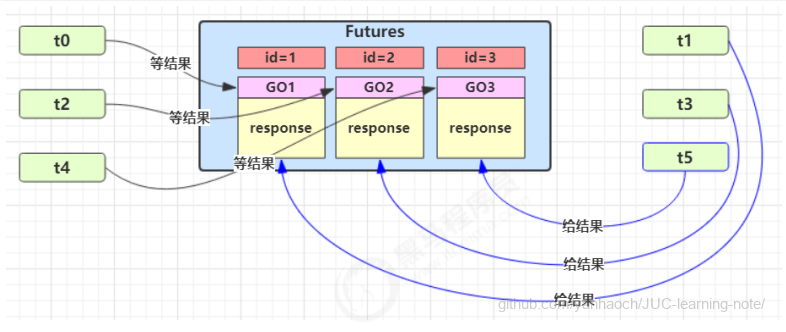
新增 id 用来标识 Guarded Object
1 | static class GuardedObject { |
中间解耦类
1 | static class MailBoxes { |
业务相关类
1 | static class Person extends Thread { |
测试
1 | public static void main(String[] args) throws InterruptedException { |
某次运行结果
22:05:14.688 [Thread-1] INFO com.lxd.juc.Test1 -- 开始收信 id:2 22:05:14.688 [Thread-0] INFO com.lxd.juc.Test1 -- 开始收信 id:1 22:05:14.688 [Thread-2] INFO com.lxd.juc.Test1 -- 开始收信 id:3 22:05:15.691 [Thread-5] INFO com.lxd.juc.Test1 -- 送信 id:1, 内容:内容1 22:05:15.691 [Thread-4] INFO com.lxd.juc.Test1 -- 送信 id:2, 内容:内容2 22:05:15.691 [Thread-3] INFO com.lxd.juc.Test1 -- 送信 id:3, 内容:内容3 22:05:15.691 [Thread-1] INFO com.lxd.juc.Test1 -- 收到信 id:2,内容:内容2 22:05:15.691 [Thread-0] INFO com.lxd.juc.Test1 -- 收到信 id:1,内容:内容1 22:05:15.691 [Thread-2] INFO com.lxd.juc.Test1 -- 收到信 id:3,内容:内容3
∗异步模式之生产者消费者
- 定义
要点
- 与前面的保护性暂停中的 GuardObject 不同,不需要产生结果和消费结果的线程一一对应
- 消费队列可以用来平衡生产和消费的线程资源
- 生产者仅负责产生结果数据,不关心数据该如何处理,而消费者专心处理结果数据
- 消息队列是有容量限制的,满时不会再加入数据,空时不会再消耗数据
- JDK 中各种阻塞队列,采用的就是这种模式
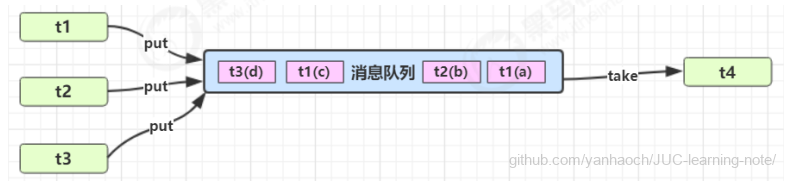
- 实现
1 |
|
测试
1 | public static void main(String[] args) { |
某次运行结果
22:43:01.547 [生产者线程0] INFO com.lxd.juc.Test21 -- 生产者线程已添加元素:Msg{id=0, msg=消息0}
22:43:01.551 [生产者线程1] INFO com.lxd.juc.Test21 -- 生产者线程已添加元素:Msg{id=1, msg=消息1}
22:43:01.552 [生产者线程2] INFO com.lxd.juc.Test21 -- 队列已满,生产者线程等待...
22:43:02.552 [消费者线程] INFO com.lxd.juc.Test21 -- 消费者线程拿到消息:Msg{id=0, msg=消息0}
22:43:02.553 [生产者线程2] INFO com.lxd.juc.Test21 -- 生产者线程已添加元素:Msg{id=2, msg=消息2}
22:43:03.558 [消费者线程] INFO com.lxd.juc.Test21 -- 消费者线程拿到消息:Msg{id=1, msg=消息1}
22:43:04.561 [消费者线程] INFO com.lxd.juc.Test21 -- 消费者线程拿到消息:Msg{id=2, msg=消息2}
22:43:05.566 [消费者线程] INFO com.lxd.juc.Test21 -- 队列为空,消费者线程等待...
3.9 park & unpark
3.9.1 基本使用
它们是 LockSupport 类中的方法
1 | // 暂停当前线程 |
1 | public static void main(String[] args) throws InterruptedException { |
输出
23:26:53.697 [t1] INFO com.lxd.juc.Test21 -- start... 23:26:54.701 [t1] INFO com.lxd.juc.Test21 -- park... 23:26:55.698 [main] INFO com.lxd.juc.Test21 -- unpark... 23:26:55.698 [t1] INFO com.lxd.juc.Test21 -- resume...
先 unpark 再 park
1 | public static void main(String[] args) throws InterruptedException { |
输出
23:28:58.580 [t1] INFO com.lxd.juc.Test21 -- start... 23:28:59.582 [main] INFO com.lxd.juc.Test21 -- unpark... 23:29:00.582 [t1] INFO com.lxd.juc.Test21 -- park... 23:29:00.583 [t1] INFO com.lxd.juc.Test21 -- resume...
特点
LockSupport 出现就是为了增强 wait & notify 的功能
与 Object 的 wait & notify 相比
- wait,notify 和 notifyAll 必须配合 Object Monitor 一起使用,而 park、unpark 不需要
- park & unpark 以线程为单位来阻塞和唤醒线程,而 notify 只能随机唤醒一个等待线程,notifyAll 是唤醒所有等待线程
- park & unpark 可以先 unpark,而 wait & notify 不能先 notify。类比生产消费,先消费发现有产品就消费,没有就等待;先生产就直接产生商品,然后线程直接消费
- wait 会释放锁资源进入等待队列,park 不会释放锁资源,只负责阻塞当前线程,会释放 CPU
3.9.2 原理
每个线程都有自己的一个 Parker 对象(由C++编写,java中不可见),由三部分组成 _counter, _cond和 _mutex 打个比喻
- 线程就像一个旅人,Parker 就像他随身携带的背包,条件变量就好比背包中的帐篷。_counter 就好比背包中 的备用干粮(0 为耗尽,1 为充足)
- 调用 park 就是要看需不需要停下来歇息
- 如果备用干粮耗尽,那么钻进帐篷歇息
- 如果备用干粮充足,那么不需停留,继续前进
- 调用 unpark,就好比令干粮充足
- 如果这时线程还在帐篷,就唤醒让他继续前进
- 如果这时线程还在运行,那么下次他调用 park 时,仅是消耗掉备用干粮,不需停留继续前进
- 因为背包空间有限,多次调用 unpark 仅会补充一份备用干粮
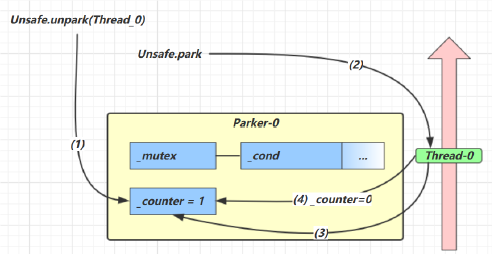
场景一
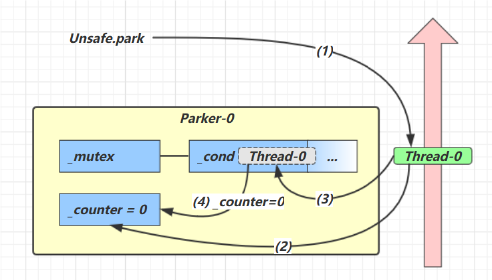
- 当前线程调用 Unsafe.park() 方法
- 检查 _counter ,本情况为 0,这时获得 _mutex 互斥锁
- 线程进入 _cond 条件变量阻塞
- 设置 _counter = 0
场景二
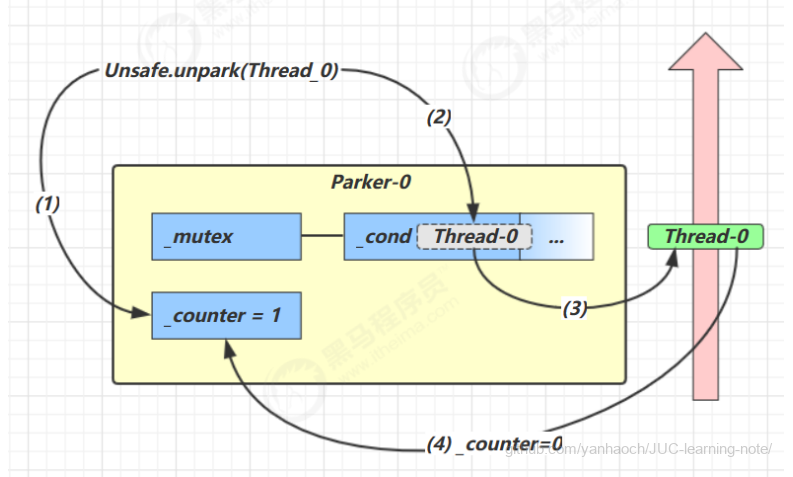
- 调用 Unsafe.unpark(Thread_0) 方法,设置 _counter 为 1
- 唤醒 _cond 条件变量中的 Thread_0
- Thread_0 恢复运行
- 设置 _counter 为 0
场景三
- 调用 Unsafe.unpark(Thread_0) 方法,设置 _counter 为 1
- 当前线程调用 Unsafe.park() 方法
- 检查 _counter ,本情况为 1,这时线程无需阻塞,继续运行
- 设置 _counter 为 0
3.10 重新理解线程状态转换
假设有线程 Thread t
1️⃣ NEW --> RUNNABLE
- 当调用
t.start()方法时,由NEW --> RUNNABLE
2️⃣ RUNNABLE <--> WAITING
t 线程用 synchronized(obj) 获取了对象锁后
- 调用
obj.wait()方法时,t 线程从RUNNABLE --> WAITING - 调用
obj.notify(),obj.notifyAll(),t.interrupt()时- 竞争锁成功,t 线程从
WAITING --> RUNNABLE - 竞争锁失败,t 线程从
WAITING --> BLOCKED
- 竞争锁成功,t 线程从
1 | public class TestWaitNotify { |
3️⃣ RUNNABLE <--> WAITING
- 当前线程调用
t.join()方法时,当前线程从RUNNABLE --> WAITING注意是当前线程在t 线程对象的监视器上等待 - t 线程运行结束,或调用了当前线程的
interrupt()时,当前线程从WAITING --> RUNNABLE
4️⃣ RUNNABLE <--> WAITING
- 当前线程调用
LockSupport.park()方法会让当前线程从RUNNABLE --> WAITING - 调用
LockSupport.unpark(目标线程) 或调用了线程 的interrupt(),会让目标线程从WAITING --> RUNNABLE
5️⃣ RUNNABLE <--> TIMED_WAITING
t 线程用 synchronized(obj) 获取了对象锁后
- 调用
obj.wait(long n)方法时,t 线程从RUNNABLE --> TIMED_WAITING - t线程等待时间超过了 n 毫秒,或调用
obj.notify(),obj.notifyAll(),t.interrupt()时- 竞争锁成功,t 线程从
TIMED_WAITING --> RUNNABLE - 竞争锁失败,t 线程从
TIMED_WAITING --> BLOCKED
- 竞争锁成功,t 线程从
6️⃣ RUNNABLE <--> TIMED_WAITING
- 当前线程调用
t.join(long n)方法时,当前线程从RUNNABLE --> TIMED_WAITING注意是当前线程在t 线程对象的监视器上等待 - 当前线程等待时间超过了 n 毫秒,或t 线程运行结束,或调用了当前线程的
interrupt()时,当前线程从TIMED_WAITING --> RUNNABLE
7️⃣ RUNNABLE <--> TIMED_WAITING
- 当前线程调用
Thread.sleep(long n),当前线程从RUNNABLE --> TIMED_WAITING - 当前线程等待时间超过了 n 毫秒,当前线程从
TIMED_WAITING --> RUNNABLE
8️⃣ RUNNABLE <--> TIMED_WAITING
- 当前线程调用
LockSupport.parkNanos(long nanos)或LockSupport.parkUntil(long millis)时,当前线程从RUNNABLE --> TIMED_WAITING - 调用
LockSupport.unpark(目标线程)或调用了线程的interrupt(),或是等待超时,会让目标线程从TIMED_WAITING--> RUNNABLE
9️⃣ RUNNABLE <--> BLOCKED
- t 线程用
synchronized(obj)获取了对象锁时如果竞争失败,从RUNNABLE --> BLOCKED - 持 obj 锁线程的同步代码块执行完毕,会唤醒该对象上所有
BLOCKED的线程重新竞争,如果其中 t 线程竞争 成功,从BLOCKED --> RUNNABLE,其它失败的线程仍然BLOCKED
🔟 RUNNABLE <--> TERMINATED
- 当前线程所有代码运行完毕,进入
TERMINATED
3.11 多把锁
多把不相干的锁
一间大屋子有两个功能:睡觉、学习,互不相干。
现在小南要学习,小女要睡觉,但如果只用一间屋子(一个对象锁)的话,那么并发度很低
解决方法是准备多个房间(多个对象锁)
例如
1 | public class BigRoom { |
执行
1 | public static void main(String[] args) { |
结果
21:55:12.212 [小南] INFO com.lxd.juc.BigRoom -- study 1 小时 21:55:12.214 [小女] INFO com.lxd.juc.BigRoom -- sleeping 2 小时
改进
1 |
|
某次执行结果
21:56:01.214 [小南] INFO com.lxd.juc.BigRoom -- study 1 小时 21:56:01.214 [小女] INFO com.lxd.juc.BigRoom -- sleeping 2 小时
将锁的粒度细分
- 好处,是可以增强并发度
- 坏处,如果一个线程需要同时获得多把锁,就容易发生死锁
- 前提:两把锁锁住的两段代码互不相关
3.12 活跃性
3.12.1 死锁
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放,由于线程被无限期地阻塞,因此程序不可能正常终止
例:t1线程获得A对象锁,接下来想获取B对象的锁;t2线程获得B对象锁,接下来想获取A对象的锁
1 |
|
结果
22:02:52.854 [t1] INFO com.lxd.juc.DeadLock -- lock A 22:02:52.854 [t2] INFO com.lxd.juc.DeadLock -- lock B
定位死锁
检测死锁可以使用 jconsole工具,或者使用 jps 定位进程 id,再用 jstack 定位死锁:
1 | cmd > jps |
1 | cmd > jstack 33200 |
- 避免死锁要注意加锁顺序
- 另外如果由于某个线程进入了死循环,导致其它线程一直等待,对于这种情况 linux 下可以通过 top 先定位到 CPU 占用高的 Java 进程,再利用 top -Hp 进程id 来定位是哪个线程,最后再用 jstack 排查
Java 死锁产生的四个必要条件
- 互斥条件,即当资源被一个线程使用(占有)时,别的线程不能使用
- 占有且等待,即当资源请求者在请求其他的资源的同时保持对原有资源的占有
- 不可剥夺条件,资源请求者不能强制从资源占有者手中夺取资源,资源只能由资源占有者主动释放
- 循环等待条件,若干进程之间形成一种头尾相接的循环等待资源关系
四个条件都成立的时候,便形成死锁。死锁情况下打破上述任何一个条件,便可让死锁消失
3.12.2 活锁
活锁出现在两个线程互相改变对方的结束条件,最后谁也无法结束,例如
1 | public class TestLiveLock { |
解决方式:
- 错开线程的运行时间,使得一方不能改变另一方的结束条件。
- 将睡眠时间调整为随机数。
3.12.3 饥饿
很多教程中把饥饿定义为,一个线程由于优先级太低,始终得不到 CPU 调度执行,也不能够结束,饥饿的情况不易演示,讲读写锁时会涉及饥饿问题
下面我讲一下我遇到的一个线程饥饿的例子,先来看看使用顺序加锁的方式解决之前的死锁问题
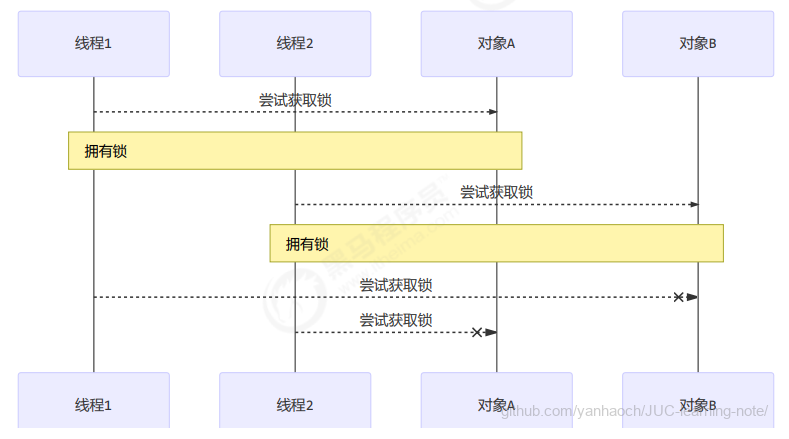
顺序加锁的解决方案

说明:
- 顺序加锁可以解决死锁问题,但也会导致一些线程一直得不到锁,产生饥饿现象。
3.13 ReentrantLock
Synchronized 和 ReentrantLock 都是用于线程的同步控制,二者都是可重入锁
- Synchronized是Java内置特性,而ReentrantLock是通过Java代码实现的
- Synchronized是自动获取/释放锁,而ReentrantLock需要手动获取/释放锁
- ReentrantLock还具有响应中断、超时等待,支持多个条件变量等特性
- ReentrantLock可实现公平/非公平锁,而Synchronized只是非公平锁
3.13.1 基本语法
1 | // 获取锁 |
3.13.2 可重入
可重入是指同一个线程如果首次获得了这把锁,那么因为它是这把锁的拥有者,因此有权利再次获取这把锁 如果是不可重入锁,那么第二次获得锁时,自己也会被锁挡住。
1 | static ReentrantLock lock = new ReentrantLock(); |
输出
23:06:14.348 [main] INFO com.lxd.juc.TestReentrantLock -- execute method1 23:06:14.349 [main] INFO com.lxd.juc.TestReentrantLock -- execute method2 23:06:14.349 [main] INFO com.lxd.juc.TestReentrantLock -- execute method3
ReentrantLock如何实现可重入的
ReentrantLock 加锁时,会判断当前持有锁的线程和请求的线程是否是同一个,一样就可以重入。只需要将state值+1,记录当前线程的重入次数即可
1 | if(current==getExclusiveOwnerThread()){ |
同时,在锁进行释放的时候,需要确保state=0的时候才能执行释放资源的动作,也就是说,一个可重入锁,重入了多少次,就要解锁多少次
1 | protected final boolean tryRelease(int releases){ |
3.13.3 可打断
可打断指的是处于阻塞状态等待锁的线程可以被打断等待。注意lock.lockInterruptibly()和lock.trylock()方法是可打断的,lock.lock()不是。可打断的意义在于避免得不到锁的线程无限制地等待下去,防止死锁的一种方式。
1 | public static void main(String[] args) throws InterruptedException { |
输出
23:10:50.957 [main] INFO com.lxd.juc.TestReentrantLock -- 获得了锁 23:10:50.958 [t1] INFO com.lxd.juc.TestReentrantLock -- 启动... 23:10:50.959 [main] INFO com.lxd.juc.TestReentrantLock -- 执行打断 23:10:50.960 [t1] INFO com.lxd.juc.TestReentrantLock -- 等锁的过程中被打断 java.lang.InterruptedException at java.base/java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireInterruptibly(AbstractQueuedSynchronizer.java:959) at java.base/java.util.concurrent.locks.ReentrantLock$Sync.lockInterruptibly(ReentrantLock.java:161) at java.base/java.util.concurrent.locks.ReentrantLock.lockInterruptibly(ReentrantLock.java:372) at com.lxd.juc.TestReentrantLock.lambda$main$0(TestReentrantLock.java:16) at java.base/java.lang.Thread.run(Thread.java:840)
注意lock()是不可中断模式,即使使用了 interrupt ,lock()也会忽略异常继续等待获取锁
1 |
|
输出
23:12:22.818 [main] INFO com.lxd.juc.TestReentrantLock -- 获得了锁 23:12:22.819 [t1] INFO com.lxd.juc.TestReentrantLock -- 启动... 23:12:22.820 [main] INFO com.lxd.juc.TestReentrantLock -- 执行打断 23:12:22.820 [t1] INFO com.lxd.juc.TestReentrantLock -- 获得了锁
3.13.4 锁超时
立即失败
1 |
|
输出
23:17:53.708 [main] INFO com.lxd.juc.TestReentrantLock -- 获得了锁 23:17:53.709 [t1] INFO com.lxd.juc.TestReentrantLock -- 启动... 23:17:53.709 [t1] INFO com.lxd.juc.TestReentrantLock -- 获取立刻失败,返回
超时失败
1 |
|
输出
23:22:51.849 [main] INFO com.lxd.juc.TestReentrantLock -- 获得了锁 23:22:51.850 [t1] INFO com.lxd.juc.TestReentrantLock -- 启动... 23:22:52.851 [t1] INFO com.lxd.juc.TestReentrantLock -- 获取等待 1s 后失败,返回
使用 tryLock 解决哲学家就餐问题
1 | class Chopstick extends ReentrantLock { |
1 | class Philosopher extends Thread { |
3.13.5 公平锁
ReentrantLock 默认是不公平的
1 |
|
强行插入,有机会在中间输出
t39 running... t40 running... t41 running... t42 running... t43 running... 强行插入 start... 强行插入 running... t44 running... t45 running... t46 running... t47 running... t49 running...
改为公平锁后
1 | ReentrantLock lock = new ReentrantLock(true); |
强行插入,总是在最后输出
t465 running... t464 running... t477 running... t442 running... t468 running... t493 running... t482 running... t485 running... t481 running... 强行插入 running...
公平锁一般没有必要,会降低并发度,后面分析原理时会讲解
3.13.6 条件变量
synchronized 中也有条件变量,就是我们讲原理时那个 waitSet 休息室,当条件不满足时进入 waitSet 等待
ReentrantLock 的条件变量比 synchronized 强大之处在于,它是支持多个条件变量的,这就好比
- synchronized 是那些不满足条件的线程都在一间休息室等消息
- 而 ReentrantLock 支持多间休息室,有专门等烟的休息室、专门等早餐的休息室、唤醒时也是按休息室来唤醒
使用要点
- await 前需要获得锁
- await 执行后,会释放锁,进入 conditionObject 等待
- await 的线程被唤醒(或打断、或超时)取重新竞争 lock 锁
- 竞争 lock 锁成功后,从 await 后继续执行
详细API
1 | public interface Condition { |
例子:
1 |
|
输出
23:36:46.238 [main] INFO com.lxd.juc.TestReentrantLock -- 送外卖来了 23:36:46.238 [Thread-1] INFO com.lxd.juc.TestReentrantLock -- 外卖来喽,开吃 23:36:46.240 [main] INFO com.lxd.juc.TestReentrantLock -- 送烟来了 23:36:46.240 [Thread-0] INFO com.lxd.juc.TestReentrantLock -- 烟来喽,干活
*同步模式之顺序控制
固定运行顺序
比如,必须先 2 后 1 打印
wait-notify版
1 |
|
可以看到,实现上很麻烦:
- 首先,需要保证先 wait 再 notify,否则 wait 线程永远得不到唤醒。因此使用了『运行标记』来判断该不该 wait
- 第二,如果有些干扰线程错误地 notify 了 wait 线程,条件不满足时还要重新等待,使用了 while 循环来解决 此问题
- 最后,唤醒对象上的 wait 线程需要使用 notifyAll,因为『同步对象』上的等待线程可能不止一个
await-signal版
1 |
|
Park Unpark 版
1 | public static void main(String[] args) { |
park 和 unpark 方法比较灵活,他俩谁先调用,谁后调用无所谓。并且是以线程为单位进行『暂停』和『恢复』, 不需要『同步对象』和『运行标记』
交替输出
线程 1 输出 a 5 次,线程 2 输出 b 5 次,线程 3 输出 c 5 次。现在要求输出 abcabcabcabcabc 怎么实现
wait-notify版
1 |
|
Lock 条件变量版
1 |
|
Park Unpark 版
1 |
|
4. 共享模型之内存
这一章重点解释并发问题为什么会发生,以及 Java 内存模型(JMM)如何约束线程之间的可见性、有序性和原子性。建议重点关注
volatile、happens-before 以及指令重排序相关内容。
4.1 Java内存模型
Java 内存模型是 Java Memory Model(JMM),本身是一种抽象的概念,实际上并不存在,描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式
JMM的意义:
- 规定了线程和内存之间的一些关系
- 屏蔽各种硬件和操作系统的内存访问差异,实现让 Java 程序在各种平台下都能达到一致的内存访问效果
- 计算机硬件底层的内存结构过于复杂,JMM的意义在于避免程序员直接管理计算机底层内存,用一些关键字synchronized、volatile等可以方便的管理内存。
JMM 体现在以下几个方面
- 原子性 - 保证指令不会受到线程上下文切换的影响
- 可见性 - 保证指令不会受 cpu 缓存的影响
- 有序性 - 保证指令不会受 cpu 指令并行优化的影响
根据 JMM 的设计,系统存在一个主内存(Main Memory),Java 中所有变量都存储在主存中,对于所有线程都是共享的;每条线程都有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作都是先对变量进行拷贝,然后在工作内存中进行,不能直接操作主内存中的变量;线程之间无法相互直接访问,线程间的通信(传递)必须通过主内存来完成

主内存和工作内存:
- 主内存:所有线程共享的内存区域,存储所有实例字段、静态字段和构成数组对象的元素
- 工作内存:每个线程私有的内存空间,存储该线程使用到的变量的主内存副本
JVM 和 JMM 之间的关系:JMM 中的主内存、工作内存与 JVM 中的 Java 堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的,如果两者一定要勉强对应起来:
- 主内存主要对应于 Java 堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域
- 从更低层次上说,主内存直接对应于物理硬件的内存,工作内存对应寄存器和高速缓存
内存交互
Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互操作,每个操作都是原子的
非原子协定:没有被 volatile 修饰的 long、double 外,默认按照两次 32 位的操作

- lock(锁定):作用于主内存,将一个变量标识为线程独占状态(对应 monitorenter)
- unclock(解锁):作用于主内存,将一个变量从独占状态释放出来,释放后的变量才可以被其他线程锁定(对应 monitorexit)
- read(读取):作用于主内存,把一个变量的值从主内存传输到工作内存中
- load(载入):作用于工作内存,在 read 之后执行,把 read 得到的值放入工作内存的变量副本中
- use(使用):作用于工作内存,把工作内存中一个变量的值传递给执行引擎,每当遇到一个使用到变量的操作时都要使用该指令
- assign(赋值):作用于工作内存,把从执行引擎接收到的一个值赋给工作内存的变量
- store(存储):作用于工作内存,把工作内存的一个变量的值传送到主内存中
- write(写入):作用于主内存,在 store 之后执行,把 store 得到的值放入主内存的变量中
参考文章:https://github.com/CyC2018/CS-Notes/blob/master/notes/Java 并发.md
4.2 原子性
原子性:不可分割,完整性,也就是说某个线程正在做某个具体业务时,中间不可以被分割,需要具体完成,要么同时成功,要么同时失败,保证指令不会受到线程上下文切换的影响
定义原子操作的使用规则:
- 不允许 read 和 load、store 和 write 操作之一单独出现,必须顺序执行,但是不要求连续
- 不允许一个线程丢弃 assign 操作,必须同步回主存
- 不允许一个线程无原因地(没有发生过任何 assign 操作)把数据从工作内存同步会主内存中
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(assign 或者 load)的变量,即对一个变量实施 use 和 store 操作之前,必须先执行 assign 和 load 操作
- 一个变量在同一时刻只允许一条线程对其进行 lock 操作,但 lock 操作可以被同一线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock 操作,变量才会被解锁,lock 和 unlock 必须成对出现
- 如果对一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量之前需要重新从主存加载
- 如果一个变量事先没有被 lock 操作锁定,则不允许执行 unlock 操作,也不允许去 unlock 一个被其他线程锁定的变量
- 对一个变量执行 unlock 操作之前,必须先把此变量同步到主内存中(执行 store 和 write 操作)
4.3 可见性
可见性:是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值
存在不可见问题的根本原因是由于缓存的存在,线程持有的是共享变量的副本,无法感知其他线程对于共享变量的更改,导致读取的值不是最新的。但是 final 修饰的变量是不可变的,就算有缓存,也不会存在不可见的问题
main 线程对 run 变量的修改对于 t 线程不可见,导致了 t 线程无法停止:
1 | static boolean run = true; //添加volatile |
原因:
- 初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存
- 因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率
- 1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值

解决方法
volatile(易变关键字)
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存
volatile 适合一个线程写,其他线程读的情况
可见性 vs 原子性
前面例子体现的实际就是可见性,它保证的是在多个线程之间,一个线程对 volatile 变量的修改对另一个线程可见, 不能保证原子性,仅用在一个写线程,多个读线程的情况: 上例从字节码理解是这样的:
getstatic run // 线程 t 获取 run true getstatic run // 线程 t 获取 run true getstatic run // 线程 t 获取 run true getstatic run // 线程 t 获取 run true putstatic run // 线程 main 修改 run 为 false, 仅此一次 getstatic run // 线程 t 获取 run false
比较一下之前我们将线程安全时举的例子:两个线程一个 i++ 一个 i-- ,只能保证看到最新值,不能解决指令交错
// 假设i的初始值为0 getstatic i // 线程2-获取静态变量i的值 线程内i=0 getstatic i // 线程1-获取静态变量i的值 线程内i=0 iconst_1 // 线程1-准备常量1 iadd // 线程1-自增 线程内i=1 putstatic i // 线程1-将修改后的值存入静态变量i 静态变量i=1 iconst_1 // 线程2-准备常量1 isub // 线程2-自减 线程内i=-1 putstatic i // 线程2-将修改后的值存入静态变量i 静态变量i=-1
注意
synchronized 语句块既可以保证代码块的原子性,也同时保证代码块内变量的可见性。但缺点是 synchronized 是属于重量级操作,性能相对更低 。
JMM关于synchronized的两条规定:
1)线程解锁前,必须把共享变量的最新值刷新到主内存中
2)线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新获取最新的值
(注意:加锁与解锁需要是同一把锁)
通过以上两点,可以看到synchronized能够实现可见性。同时,由于synchronized具有同步锁,所以它也具有原子性
如果在前面示例的死循环中加入 System.out.println() 会发现即使不加 volatile 修饰符,线程 t 也能正确看到 对 run 变量的修改了,想一想为什么?(println方法中有synchronized代码块保证了可见性)
synchronized关键字不能阻止指令重排,但在一定程度上能保证有序性(如果共享变量没有逃逸出同步代码块的话)。因为在单线程的情况下指令重排不影响结果,相当于保障了有序性。
*模式之Balking
Balking (犹豫)模式用在一个线程发现另一个线程或本线程已经做了某一件相同的事,那么本线程就无需再做了,直接结束返回
1 | public class MonitorService { |
当前端页面多次点击按钮调用 start 时
输出
[http-nio-8080-exec-1] cn.itcast.monitor.service.MonitorService - 该监控线程已启动?(false) [http-nio-8080-exec-1] cn.itcast.monitor.service.MonitorService - 监控线程已启动... [http-nio-8080-exec-2] cn.itcast.monitor.service.MonitorService - 该监控线程已启动?(true) [http-nio-8080-exec-3] cn.itcast.monitor.service.MonitorService - 该监控线程已启动?(true) [http-nio-8080-exec-4] cn.itcast.monitor.service.MonitorService - 该监控线程已启动?(true)
为什么需要加锁?
- 当 t1 线程进入 start() 准备修改 initialized 状态,t2 线程进来,initialized 还为false,则 t2 就又执行一次
它还经常用来实现线程安全的单例
1 | public final class Singleton { |
对比保护性暂停模式:保护性暂停模式用在一个线程等待另一个线程的执行结果,当条件不满足时线程等待
4.4 有序性
JVM 会在不影响正确性的前提下,可以调整语句的执行顺序,思考下面一段代码
1 | static int i; |
可以看到,至于是先执行 i 还是 先执行 j ,对最终的结果不会产生影响。所以,上面代码真正执行时,既可以是
1 | i = ...; |
也可以是
1 | j = ...; |
这种特性称之为『指令重排』,多线程下『指令重排』会影响正确性。为什么要有重排指令这项优化呢?从 CPU 执行指令的原理来理解一下吧
*原理之指令级并行
Clock Cycle Time
主频的概念大家接触的比较多,而 CPU 的 Clock Cycle Time(时钟周期时间),等于主频的倒数,意思是 CPU 能 够识别的最小时间单位,比如说 4G 主频的 CPU 的 Clock Cycle Time 就是 0.25 ns,作为对比,我们墙上挂钟的 Cycle Time 是 1s
例如,运行一条加法指令一般需要一个时钟周期时间
CPI
有的指令需要更多的时钟周期时间,所以引出了 CPI (Cycles Per Instruction)指令平均时钟周期数
IPC
IPC(Instruction Per Clock Cycle) 即 CPI 的倒数,表示每个时钟周期能够运行的指令数
CPU 执行时间
程序的 CPU 执行时间,即我们前面提到的 user + system 时间,可以用下面的公式来表示
程序 CPU 执行时间 = 指令数 * CPI * Clock Cycle Time
指令重排序优化
事实上,现代处理器会设计为一个时钟周期完成一条执行时间最长的 CPU 指令。为什么这么做呢?可以想到指令 还可以再划分成一个个更小的阶段,例如,每条指令都可以分为: 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 这 5 个阶段

在不改变程序结果的前提下,这些指令的各个阶段可以通过重排序和组合来实现指令级并行,这一技术在 80’s 中 叶到 90’s 中叶占据了计算架构的重要地位。
指令重排的前提是,重排指令不能影响结果,例如
1 | // 可以重排的例子 |
参考:
Scoreboarding and the Tomasulo algorithm (which is similar to scoreboarding but makes use of register renaming )are two of the most common techniques for implementing out-of-order execution and instruction-level parallelism.
支持流水线的处理器
现代 CPU 支持多级指令流水线,例如支持同时执行 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 的处理器,就可以称之为五级指令流水线。这时 CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(相当于一 条执行时间最长的复杂指令),IPC = 1,本质上,流水线技术并不能缩短单条指令的执行时间,但它变相地提高了指令的吞吐率。

SuperScalar 处理器
大多数处理器包含多个执行单元,并不是所有计算功能都集中在一起,可以再细分为整数运算单元、浮点数运算单元等,这样可以把多条指令也可以做到并行获取、译码等,CPU 可以在一个时钟周期内,执行多于一条指令,IPC > 1

诡异的结果
1 | int num = 0; |
I_Result 是一个对象,有一个属性 r1 用来保存结果,问,可能的结果有几种?
有同学这么分析
情况1:线程1 先执行,这时 ready = false,所以进入 else 分支结果为 1
情况2:线程2 先执行 num = 2,但没来得及执行 ready = true,线程1 执行,还是进入 else 分支,结果为1
情况3:线程2 执行到 ready = true,线程1 执行,这回进入 if 分支,结果为 4(因为 num 已经执行过了)
但我告诉你,结果还有可能是 0 😁😁😁,信不信吧!
这种情况下是:线程2 执行 ready = true,切换到线程1,进入 if 分支,相加为 0,再切回线程2 执行 num = 2
相信很多人已经晕了 😵😵😵
这种现象叫做指令重排,是 JIT 编译器在运行时的一些优化,这个现象需要通过大量测试才能复现:
借助 java 并发压测工具 jcstress https://wiki.openjdk.java.net/display/CodeTools/jcstress
mvn archetype:generate -DinteractiveMode=false -DarchetypeGroupId=org.openjdk.jcstress - DarchetypeArtifactId=jcstress-java-test-archetype -DarchetypeVersion=0.5 -DgroupId=cn.itcast - DartifactId=ordering -Dversion=1.0
创建 maven 项目,提供如下测试类
1 |
|
执行
mvn clean install java -jar target/jcstress.jar
会输出我们感兴趣的结果,摘录其中一次结果:
*** INTERESTING tests
Some interesting behaviors observed. This is for the plain curiosity.
==== ==== ==== ==== ==== ==== ==== ==== ==== ==== ==== ==== ==== ====
2 matching test results.
[OK] test.ConcurrencyTest
(JVM args: [-XX:-TieredCompilation])
Observed state Occurrences Expectation Interpretation
0 1,729 ACCEPTABLE_INTERESTING !!!!
1 42,617,915 ACCEPTABLE ok
4 5,146,627 ACCEPTABLE ok
==== ==== ==== ==== ==== ==== ==== ==== ==== ==== ==== ==== ==== ====
[OK] test.ConcurrencyTest
(JVM args: [])
Observed state Occurrences Expectation Interpretation
0 1,652 ACCEPTABLE_INTERESTING !!!!
1 46,460,657 ACCEPTABLE ok
4 4,571,072 ACCEPTABLE ok
可以看到,出现结果为 0 的情况,虽然次数相对很少,但毕竟是出现了。
解决方法
volatile 修饰的变量,可以禁用指令重排
1 |
|
结果为:
*** INTERESTING tests Some interesting behaviors observed. This is for the plain curiosity. 0 matching test results.
4.5 volatile
4.5.1 同步机制
volatile 是 Java 虚拟机提供的轻量级的同步机制(三大特性)
- 保证可见性
- 不保证原子性
- 保证有序性(禁止指令重排)
性能:volatile 修饰的变量进行读操作与普通变量几乎没什么差别,但是写操作相对慢一些,因为需要在本地代码中插入很多内存屏障来保证指令不会发生乱序执行,但是开销比锁要小
synchronized 无法禁止指令重排和处理器优化,为什么可以保证有序性可见性
- 加了锁之后,只能有一个线程获得到了锁,获得不到锁的线程就要阻塞,所以同一时间只有一个线程执行,相当于单线程,由于数据依赖性的存在,单线程的指令重排是没有问题的
- 线程加锁前,将清空工作内存中共享变量的值,使用共享变量时需要从主内存中重新读取最新的值;线程解锁前,必须把共享变量的最新值刷新到主内存中(JMM 内存交互章节有讲)
4.5.2 指令重排
volatile 修饰的变量,可以禁用指令重排
指令重排实例:
1 | public void mySort() { |
执行顺序是:1 2 3 4、2 1 3 4、1 3 2 4
指令重排也有限制不会出现:4321,语句 4 需要依赖于 y 以及 x 的申明,因为存在数据依赖,无法首先执行
1 | int num = 0; |
情况一:线程 1 先执行,ready = false,结果为 r.r1 = 1
情况二:线程 2 先执行 num = 2,但还没执行 ready = true,线程 1 执行,结果为 r.r1 = 1
情况三:线程 2 先执行 ready = true,线程 1 执行,进入 if 分支结果为 r.r1 = 4
情况四:线程 2 执行 ready = true,切换到线程 1,进入 if 分支为 r.r1 = 0,再切回线程 2 执行 num = 2,发生指令重排
4.5.3 底层原理
缓存一致
使用 volatile 修饰的共享变量,底层通过汇编 lock 前缀指令进行缓存锁定,在线程修改完共享变量后写回主存,其他的 CPU 核心上运行的线程通过 CPU 总线嗅探机制会修改其共享变量为失效状态,读取时会重新从主内存中读取最新的数据
lock 前缀指令就相当于内存屏障,Memory Barrier(Memory Fence)
- 对 volatile 变量的写指令后会加入写屏障
- 对 volatile 变量的读指令前会加入读屏障
内存屏障有三个作用:
- 确保对内存的读-改-写操作原子执行
- 阻止屏障两侧的指令重排序
- 强制把缓存中的脏数据写回主内存,让缓存行中相应的数据失效
保证可见性
-
写屏障(sfence,Store Barrier)保证在该屏障之前的,对共享变量的改动,都同步到主存当中
1
2
3
4
5public void actor2(I_Result r) {
num = 2;
ready = true; // ready 是 volatile 赋值带写屏障
// 写屏障
} -
读屏障(lfence,Load Barrier)保证在该屏障之后的,对共享变量的读取,从主存刷新变量值,加载的是主存中最新数据
1
2
3
4
5
6
7
8
9public void actor1(I_Result r) {
// 读屏障
// ready 是 volatile 读取值带读屏障
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
-
全能屏障:mfence(modify/mix Barrier),兼具 sfence 和 lfence 的功能
保证有序性
-
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
1
2
3
4
5public void actor2(I_Result r) {
num = 2;
ready = true; // ready 是 volatile 赋值带写屏障
// 写屏障
} -
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
1
2
3
4
5
6
7
8
9public void actor1(I_Result r) {
// 读屏障
// ready 是 volatile 读取值带读屏障
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}

不能解决指令交错
-
写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证其他线程的读跑到写屏障之前
-
有序性的保证也只是保证了本线程内相关代码不被重排序
1
2
3volatile i = 0;
new Thread(() -> {i++});
new Thread(() -> {i--});i++ 反编译后的指令:
1
2
30: iconst_1 // 当int取值 -1~5 时,JVM采用iconst指令将常量压入栈中
1: istore_1 // 将操作数栈顶数据弹出,存入局部变量表的 slot 1
2: iinc 1, 1
对于 volatile 修饰的变量:
- 线程对变量的 use 与 load、read 操作是相关联的,所以变量使用前必须先从主存加载
- 线程对变量的 assign 与 store、write 操作是相关联的,所以变量使用后必须同步至主存
- 线程 1 和线程 2 谁先对变量执行 read 操作,就会先进行 write 操作,防止指令重排
4.5.4 双端检锁
double-checked locking 单例模式
1 | public final class Singleton { |
以上的实现特点是:
- 懒惰实例化
- 首次使用 getInstance() 才使用 synchronized 加锁,后续使用时无需加锁
- 有隐含的,但很关键的一点:第一个 if 使用了 INSTANCE 变量,是在同步块之外
但在多线程环境下,上面的代码是有问题的,getInstance 方法对应的字节码为:
0: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 3: ifnonnull 37 6: ldc #3 // class cn/itcast/n5/Singleton 8: dup 9: astore_0 10: monitorenter 11: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 14: ifnonnull 27 17: new #3 // class cn/itcast/n5/Singleton 20: dup 21: invokespecial #4 // Method "":()V 24: putstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 27: aload_0 28: monitorexit 29: goto 37 32: astore_1 33: aload_0 34: monitorexit 35: aload_1 36: athrow 37: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 40: areturn
其中
- 17 表示创建对象,将对象引用入栈 // new Singleton
- 20 表示复制一份对象引用 // 引用地址
- 21 表示利用一个对象引用,调用构造方法
- 24 表示利用一个对象引用,赋值给 static INSTANCE
也许 jvm 会优化为:先执行 24,再执行 21。如果两个线程 t1,t2 按如下时间序列执行:

关键在于 0: getstatic 这行代码在 monitor 控制之外,它就像之前举例中不守规则的人,可以越过 monitor 读取 INSTANCE 变量的值
这时 t1 还未完全将构造方法执行完毕,如果在构造方法中要执行很多初始化操作,那么 t2 拿到的是将是一个未初始化完毕的单例。
对 INSTANCE 使用 volatile 修饰即可,可以禁用指令重排,但要注意在 JDK 5 以上的版本的 volatile 才会真正有效
double-checked locking 解决
1 | public final class Singleton { |
字节码上看不出来 volatile 指令的效果
// -------------------------------------> 加入对 INSTANCE 变量的读屏障 0: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 3: ifnonnull 37 6: ldc #3 // class cn/itcast/n5/Singleton 8: dup 9: astore_0 10: monitorenter -----------------------> 保证原子性、可见性 11: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 14: ifnonnull 27 17: new #3 // class cn/itcast/n5/Singleton 20: dup 21: invokespecial #4 // Method "":()V 24: putstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; // -------------------------------------> 加入对 INSTANCE 变量的写屏障 27: aload_0 28: monitorexit ------------------------> 保证原子性、可见性 29: goto 37 32: astore_1 33: aload_0 34: monitorexit 35: aload_1 36: athrow 37: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 40: areturn
如上面的注释内容所示,读写 volatile 变量时会加入内存屏障(Memory Barrier(Memory Fence)),保证下面 两点:
- 可见性
- 写屏障(sfence)保证在该屏障之前的 t1 对共享变量的改动,都同步到主存当中
- 而读屏障(lfence)保证在该屏障之后 t2 对共享变量的读取,加载的是主存中最新数据
- 有序性
- 写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
- 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
- 更底层是读写变量时使用 lock 指令来多核 CPU 之间的可见性与有序性

4.5.5 happens-before
happens-before 规定了对共享变量的写操作对其它线程的读操作可见,它是可见性与有序性的一套规则总结,抛开以下 happens-before 规则,JMM 并不能保证一个线程对共享变量的写,对于其它线程对该共享变量的读可见
happends-before原则的适用场景
- 程序次序规则(ProgramOrderRule):在单个线程内,按照程序代码的顺序,前一个操作happens-before 后一个操作。
1 | public class ProgramOrderExample{ |
- 管程锁定规则(MonitorLockRule):对一个锁的解锁happens-before 随后对这个锁的加锁。即在 synchronized代码块或方法中,释放锁之前的所有操作对于下一个获取这个锁的线程是可见的。
1 | public class MonitorLockExample{ |
increment方法中对value的修改,在getValue方法获取锁之后是可见的。
- volatile变量规则(VolatileVariableRule): 对一个volatile字段的写操作happens-before任意后续对这 个字段的读操作。即确保volatile变量的写操作对其他线程立即可见
1 | public class VolatileExample{ |
当一个线程调用writeFlag(),另一个线程随后调用checkFlag()将看到flag为true。
- 线程启动规则(ThreadStartRule):对线程的start()方法的调用happens-before该线程的每个动作。确保线程启动时,主线程中对共享变量的写操作对于新线程是可见的。
1 | public class ThreadStartExample{ |
线程启动时,将看到startValue的值为11。
- 线程终止规则(ThreadTerminationRule):一个线程的所有操作happens-before对这个线程的join()方 法的成功返回。确保线程终止时,该线程中的所有操作对于调用join()方法的线程是可见的。
1 | public class ThreadJoinExample{ |
主线程中可以看到子线程对counter的修改
-
线程中断规则(ThreadInterruptionRule):对线程的interrupt()方法的调用happens-before被中断线程检测到中断事件的发生。即线程的中断操作在被该线程检测到之前已经发生。
-
对象终结规则(FinalizerRule):一个对象的初始化完成(构造函数执行结束)happens-before它的finalize()方法的开始。即在对象被回收前,其构造过程已经完全结束。
1 | public class FinalizerExample{ |
- 传递性(Transitivity):如果操作A先行发生于操作B,操作B先行发生于操作C,那就可以得出操作A先行发生于操作C的结论。
1 | public class TransitivityExample{ |
由于ready是一个volatile变量,写入ready(操作B)发生在读取ready之前,同样,写入number(操作A)发生在写入ready之前。根据传递性规则,写入number发生在读取ready之前。
参考链接:happens-before规则解析 - 知乎 (zhihu.com)
*单例模式的实现方法
饿汉、懒汉、静态内部类、枚举类,试分析每种实现下获取单例对象(即调用 getInstance)时的线程安全,并思考注释中的问题
饿汉式:类加载就会导致该单实例对象被创建
懒汉式:类加载不会导致该单实例对象被创建,而是首次使用该对象时才会创建
实现1(饿汉式):
1 | // 问题1:为什么加 final(防止被子类继承从而重写方法改写单例) |
实现2(枚举类):
1 | // 问题1:枚举单例是如何限制实例个数的 (枚举类会按照声明的个数在类加载时实例化对象) |
实现3(synchronized方法):
1 | public final class Singleton { |
实现4:DCL+volatile
1 | public final class Singleton { |
实现5(内部类初始化):
1 | public final class Singleton { |
5. 共享模型之无锁
这一章从另一条路线解释并发控制:不是通过阻塞和互斥来解决竞争,而是通过 CAS、原子变量等机制实现更轻量的并发协调。它适合和锁机制对照着看,理解两者各自的适用边界。
5.1 问题提出(应用之互斥)
有如下需求,保证 account.withdraw 取款方法的线程安全
1 | interface Account { |
原有实现并不是线程安全的
1 | class AccountUnsafe implements Account { |
执行测试代码
1 | public static void main(String[] args) { |
某次的执行结果
330 cost: 306 ms
为什么不安全
1 | public void withdraw(Integer amount) { |
对应的字节码
ALOAD 0 ALOAD 0 GETFIELD cn/itcast/AccountUnsafe.balance : Ljava/lang/Integer; INVOKEVIRTUAL java/lang/Integer.intValue ()I ALOAD 1 INVOKEVIRTUAL java/lang/Integer.intValue ()I ISUB // 减法 INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer; PUTFIELD cn/itcast/AccountUnsafe.balance : Ljava/lang/Integer;
| 字节码指令 | 栈状态变化 | 作用说明 |
|---|---|---|
ALOAD 0 |
[this] | 加载局部变量表第0槽位的this对象引用(当前AccountUnsafe实例) |
ALOAD 0 |
[this, this] | 再次加载this引用 |
GETFIELD balance |
[Integer] | 获取this.balance 字段值(Integer对象) |
INVOKEVIRTUAL intValue() |
[int] | 调用Integer.intValue() 拆箱为原始int值 |
ALOAD 1 |
[int, Integer] | 加载局部变量表第1槽位的amount参数(Integer对象) |
INVOKEVIRTUAL intValue() |
[int, int] | 拆箱amount为原始int值 |
ISUB |
[int] | 执行减法操作(栈顶两int值相减) |
INVOKESTATIC Integer.valueOf() |
[Integer] | 将减法结果装箱为Integer对象 |
PUTFIELD balance |
[] | 将新Integer对象存入this.balance 字段 |

- 多步骤非原子性
从读取balance到写入新值共经历 7步操作,若多个线程交叉执行,会导致:- 脏读:线程B在A计算期间读取到未更新的旧值
- 丢失更新:后写入的线程覆盖前一线程的结果(如
100-50-30可能得70而非正确值20)
- 拆箱/装箱的隐藏风险
Integer的不可变性导致每次运算都创建新对象,若并发PUTFIELD可能引发对象引用竞争- 自动装箱缓存问题(
-128~127)可能意外共享Integer实例
- 内存可见性缺失
- 无
volatile修饰时,balance字段更新可能对其他线程不可见(线程缓存未刷新)
- 无
5.1.1 解决思路-锁(悲观互斥)
首先想到的是给 Account 对象加锁
1 | class AccountUnsafe implements Account { |
结果为
0 cost: 399 ms
5.1.2 解决思路-无锁(乐观重试)
1 | class AccountSafe implements Account { |
执行测试代码
1 | public static void main(String[] args) { |
某次的执行结果
0 cost: 302 ms
5.2 CAS与volatile
前面看到的 AtomicInteger 的解决方法,内部并没有用锁来保护共享变量的线程安全。那么它是如何实现的呢?
1 | public void withdraw(Integer amount) { |
其中的关键是 compareAndSet,它的简称就是 CAS (也有 Compare And Swap 的说法),它必须是原子操作。
5.2.1 CAS
无锁编程:Lock Free
CAS 的全称是 Compare-And-Swap,是 CPU 并发原语
- CAS 并发原语体现在 Java 语言中就是 sun.misc.Unsafe 类的各个方法,调用 UnSafe 类中的 CAS 方法,JVM 会实现出 CAS 汇编指令,这是一种完全依赖于硬件的功能,实现了原子操作
- CAS 是一种系统原语,原语属于操作系统范畴,是由若干条指令组成 ,用于完成某个功能的一个过程,并且原语的执行必须是连续的,执行过程中不允许被中断,所以 CAS 是一条 CPU 的原子指令,不会造成数据不一致的问题,是线程安全的
底层原理:CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核和多核 CPU 下都能够保证比较交换的原子性
-
程序是在单核处理器上运行,会省略 lock 前缀,单处理器自身会维护处理器内的顺序一致性,不需要 lock 前缀的内存屏障效果
-
程序是在多核处理器上运行,会为 cmpxchg 指令加上 lock 前缀。当某个核执行到带 lock 的指令时,CPU 会执行总线锁定或缓存锁定,将修改的变量写入到主存,这个过程不会被线程的调度机制所打断,保证了多个线程对内存操作的原子性
作用:比较当前工作内存中的值和主物理内存中的值,如果相同则执行规定操作,否则继续比较直到主内存和工作内存的值一致为止
CAS 特点:
- CAS 体现的是无锁并发、无阻塞并发,线程不会陷入阻塞,线程不需要频繁切换状态(上下文切换,系统调用)
- CAS 是基于乐观锁的思想
CAS 缺点:
- 执行的是循环操作,如果比较不成功一直在循环,最差的情况某个线程一直取到的值和预期值都不一样,就会无限循环导致饥饿,使用 CAS 线程数不要超过 CPU 的核心数,采用分段 CAS 和自动迁移机制
- 只能保证一个共享变量的原子操作
- 对于一个共享变量执行操作时,可以通过循环 CAS 的方式来保证原子操作
- 对于多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候只能用锁来保证原子性
- 引出来 ABA 问题
5.2.2 volatile
获取共享变量时,为了保证该变量的可见性,需要使用 volatile 修饰。
它可以用来修饰成员变量和静态成员变量, 避免线程从自己的工作缓存中查找变量的值,必须到主存中获取值,线程操作 volatile 变量都是直接操作主存。即一个线程对 volatile 变量的修改,对另一个线程可见。
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现【比较并交换】的效果。
为什么无锁效率高
- 无锁情况下,即使重试失败,线程始终在高速运行,没有停歇,类似于自旋。而 synchronized 会让线程在没有获得锁的时候,发生上下文切换,进入阻塞。线程的上下文切换是费时的,在重试次数不是太多时,无锁的效率高于有锁。线程就好像高速跑道上的赛车,高速运行时,速度超快,一旦发生上下文切换,就好比赛车要减速、熄火, 等被唤醒又得重新打火、启动、加速… 恢复到高速运行,代价比较大
- 但无锁情况下,因为线程要保持运行,需要额外 CPU 的支持,CPU 在这里就好比高速跑道,没有额外的跑道,线程想高速运行也无从谈起,虽然不会进入阻塞,但由于没有分到时间片,仍然会进入可运行状态,还是会导致上下文切换。
- 所以总的来说,当线程数小于等于cpu核心数时,使用无锁方案是很合适的,因为有足够多的cpu让线程运行。当线程数远多于cpu核心数时,无锁效率相比于有锁就没有太大优势,因为依旧会发生上下文切换。
CAS 与 synchronized 总结
- synchronized 是从悲观的角度出发:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程),因此 synchronized 也称之为悲观锁,ReentrantLock 也是一种悲观锁,性能较差
- CAS 是从乐观的角度出发:总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。如果别人修改过,则获取现在最新的值,如果别人没修改过,直接修改共享数据的值,CAS 这种机制也称之为乐观锁,综合性能较好
5.3 原子整数
常见原子类:AtomicInteger、AtomicBoolean、AtomicLong
以 AtomicInteger 为例,构造方法:
public AtomicInteger():初始化一个默认值为 0 的原子型 Integerpublic AtomicInteger(int initialValue):初始化一个指定值的原子型 Integer
常用API:
| 方法 | 作用 |
|---|---|
| public final int get() | 获取 AtomicInteger 的值 |
| public final int getAndIncrement() | 以原子方式将当前值加 1,返回的是自增前的值 |
| public final int incrementAndGet() | 以原子方式将当前值加 1,返回的是自增后的值 |
| public final int getAndSet(int value) | 以原子方式设置为 newValue 的值,返回旧值 |
| public final int addAndGet(int data) | 以原子方式将输入的数值与实例中的值相加并返回 实例:AtomicInteger 里的 value |
1 | AtomicInteger i = new AtomicInteger(0); |
说明:
-
以上方法都是以CAS为基础进行了封装,保证了方法的原子性和变量的可见性。
-
updateAndGet方法的手动实现:
1
2
3
4
5
6
7
8
9public static int updateAndGet(AtomicInteger i, IntUnaryOperator operator){
while (true){
int prev = i.get();
int next = operator.applyAsInt(prev);
if(i.compareAndSet(prev,next)){
return next;
}
}
}
5.4 原子引用
为什么需要原子引用类型?
- AtomicReference
- AtomicMarkableReference
- AtomicStampedReference
实际开发的过程中我们使用的不一定是int、long等基本数据类型,也有可能是BigDecimal这样的类型,这时就需要用到原子引用作为容器。原子引用设置值使用的是unsafe.compareAndSwapObject()方法。原子引用中表示数据的类型需要重写equals()方法。
有如下方法
1 | public interface DecimalAccount { |
试着提供不同的 DecimalAccount 实现,实现安全的取款操作
5.4.1 不安全的实现
1 | class DecimalAccountUnsafe implements DecimalAccount { |
5.4.2 安全实现-使用锁
1 | class DecimalAccountSafeLock implements DecimalAccount { |
5.4.3 安全实现-使用CAS
1 | class DecimalAccountSafeCas implements DecimalAccount { |
测试代码
1 | DecimalAccount.demo(new DecimalAccountUnsafe(new BigDecimal("10000"))); |
运行结果
4310 cost: 425 ms 0 cost: 285 ms 0 cost: 274 ms
5.4.4 ABA问题及解决
ABA问题
1 | static AtomicReference<String> ref = new AtomicReference<>("A"); |
输出
11:29:52.325 c.Test36 [main] - main start... 11:29:52.379 c.Test36 [t1] - change A->B true 11:29:52.879 c.Test36 [t2] - change B->A true 11:29:53.880 c.Test36 [main] - change A->C true
主线程仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种从 A 改为 B 又 改回 A 的情况,如果主线程希望:
只要有其它线程 操作过 共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号
AtomicStampedReference
1 | static AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0); |
输出为
15:41:34.891 c.Test36 [main] - main start... 15:41:34.894 c.Test36 [main] - 版本 0 15:41:34.956 c.Test36 [t1] - change A->B true 15:41:34.956 c.Test36 [t1] - 更新版本为 1 15:41:35.457 c.Test36 [t2] - change B->A true 15:41:35.457 c.Test36 [t2] - 更新版本为 2 15:41:36.457 c.Test36 [main] - change A->C false
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如: A -> B -> A -> C ,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。
但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了 AtomicMarkableReference

AtomicMarkableReference
1 | class GarbageBag { |
1 |
|
输出
2019-10-13 15:30:09.264 [main] 主线程 start... 2019-10-13 15:30:09.270 [main] cn.itcast.GarbageBag@5f0fd5a0 装满了垃圾 2019-10-13 15:30:09.293 [Thread-1] 打扫卫生的线程 start... 2019-10-13 15:30:09.294 [Thread-1] cn.itcast.GarbageBag@5f0fd5a0 空垃圾袋 2019-10-13 15:30:10.294 [main] 主线程想换一只新垃圾袋? 2019-10-13 15:30:10.294 [main] 换了么?false 2019-10-13 15:30:10.294 [main] cn.itcast.GarbageBag@5f0fd5a0 空垃圾袋
可以注释掉打扫卫生线程代码,再观察输出
5.5 原子数组
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
有如下方法
1 | /** |
5.5.1 不安全的数组
1 | demo( |
结果
[9870, 9862, 9774, 9697, 9683, 9678, 9679, 9668, 9680, 9698]
5.5.2 安全的数组
1 | demo( |
结果
[10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000]
5.6 字段更新器
- AtomicReferenceFieldUpdater
- AtomicIntegerFieldUpdater
- AtomicLongFieldUpdater
利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常
Exception in thread "main" java.lang.IllegalArgumentException: Must be volatile type
1 | public class Test5 { |
5.7 原子累加器
- LongAdder
- DoubleAdder
- LongAccumulator
- DoubleAccumulator
LongAdder 和 LongAccumulator 区别:
相同点:
- LongAddr 与 LongAccumulator 类都是使用非阻塞算法 CAS 实现的
- LongAddr 类是 LongAccumulator 类的一个特例,只是 LongAccumulator 提供了更强大的功能,可以自定义累加规则,当accumulatorFunction 为 null 时就等价于 LongAdder
不同点:
-
调用 casBase 时,LongAccumulator 使用 function.applyAsLong(b = base, x) 来计算,LongAddr 使用 casBase(b = base, b + x)
-
LongAccumulator 类功能更加强大,构造方法参数中
- accumulatorFunction 是一个双目运算器接口,可以指定累加规则,比如累加或者相乘,其根据输入的两个参数返回一个计算值,LongAdder 内置累加规则
- identity 则是 LongAccumulator 累加器的初始值,LongAccumulator 可以为累加器提供非0的初始值,而 LongAdder 只能提供默认的 0
5.7.1 累加器性能比较
1 | private static <T> void demo(Supplier<T> adderSupplier, Consumer<T> action) { |
比较 AtomicLong 与 LongAdder
1 | for (int i = 0; i < 5; i++) { |
输出
1000000 cost:43 1000000 cost:9 1000000 cost:7 1000000 cost:7 1000000 cost:7 1000000 cost:31 1000000 cost:27 1000000 cost:28 1000000 cost:24 1000000 cost:22
5.7.2 优化机制
LongAdder 是 Java8 提供的类,跟 AtomicLong 有相同的效果,但对 CAS 机制进行了优化,尝试使用分段 CAS 以及自动分段迁移的方式来大幅度提升多线程高并发执行 CAS 操作的性能
优化核心思想:数据分离,将 AtomicLong 的单点的更新压力分担到各个节点,空间换时间,在低并发的时候直接更新,可以保障和 AtomicLong 的性能基本一致,而在高并发的时候通过分散减少竞争,提高了性能
分段 CAS 机制:
- 在发生竞争时,创建 Cell 数组用于将不同线程的操作离散(通过 hash 等算法映射)到不同的节点上
- 设置多个累加单元(会根据需要扩容,最大为 CPU 核数),Therad-0 累加 Cell[0],而 Thread-1 累加 Cell[1] 等,最后将结果汇总
- 在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能
自动分段迁移机制:某个 Cell 的 value 执行 CAS 失败,就会自动寻找另一个 Cell 分段内的 value 值进行 CAS 操作
*原理之伪共享
CPU缓存结构
在计算机系统中,CPU 高速缓存(CPU Cache,简称缓存)是用于减少处理器访问内存所需平均时间的部件;在存储体系中位于自顶向下的第二层,仅次于 CPU 寄存器;其容量远小于内存,但速度却可以接近处理器的频率
CPU 处理器速度远远大于内存读取速度的,为了解决速度差异,在它们之间架设了多级缓存,如 L1、L2、L3 级别的缓存,这些缓存离 CPU 越近就越快,将频繁操作的数据缓存到这里,加快访问速度

查看 cpu 缓存
⚡ root@yihang01 ~ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 1 On-line CPU(s) list: 0 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 142 Model name: Intel(R) Core(TM) i7-8565U CPU @ 1.80GHz Stepping: 11 CPU MHz: 1992.002 BogoMIPS: 3984.00 Hypervisor vendor: VMware Virtualization type: full L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 8192K NUMA node0 CPU(s): 0
速度比较
| 从 CPU 到 | 大约需要的时钟周期 |
|---|---|
| 寄存器 | 1 cycle (4GHz 的 CPU 约为 0.25ns) |
| L1 | 3~4 cycle |
| L2 | 10~20 cycle |
| L3 | 40~45 cycle |
| 内存 | 120~240 cycle |
Linux 查看 CPU 缓存行:
- 命令:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size64 - 内存地址格式:[高位组标记] [低位索引] [偏移量]

读取数据流程如下
- 根据低位,计算在缓存中的索引
- 判断是否有效
- 0 去内存读取新数据更新缓存行
- 1 再对比高位组标记是否一致
- 一致,根据偏移量返回缓存数据
- 不一致,去内存读取新数据更新缓存行
缓存使用
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据,如果存在(命中),则不用访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器
缓存之所以有效,主要因为程序运行时对内存的访问呈现局部性(Locality)特征。既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality),有效利用这种局部性,缓存可以达到极高的命中率
CPU缓存一致性
缓存一致性:当多个处理器运算任务都涉及到同一块主内存区域的时候,将可能导致各自的缓存数据不一样

MESI(Modified Exclusive Shared Or Invalid)是一种广泛使用的支持写回策略的缓存一致性协议,CPU 中每个缓存行(caceh line)使用 4 种状态进行标记(使用额外的两位 bit 表示):
-
M:被修改(Modified)
该缓存行只被缓存在该 CPU 的缓存中,并且是被修改过的,与主存中的数据不一致 (dirty),该缓存行中的内存需要写回 (write back) 主存。该状态的数据再次被修改不会发送广播,因为其他核心的数据已经在第一次修改时失效一次
当被写回主存之后,该缓存行的状态会变成独享 (exclusive) 状态
-
E:独享的(Exclusive)
该缓存行只被缓存在该 CPU 的缓存中,是未被修改过的 (clear),与主存中数据一致,修改数据不需要通知其他 CPU 核心,该状态可以在任何时刻有其它 CPU 读取该内存时变成共享状态 (shared)
当 CPU 修改该缓存行中内容时,该状态可以变成 Modified 状态
-
S:共享的(Shared)
该状态意味着该缓存行可能被多个 CPU 缓存,并且各个缓存中的数据与主存数据一致,当 CPU 修改该缓存行中,会向其它 CPU 核心广播一个请求,使该缓存行变成无效状态 (Invalid),然后再更新当前 Cache 里的数据
-
I:无效的(Invalid)
该缓存是无效的,可能有其它 CPU 修改了该缓存行
解决方法:各个处理器访问缓存时都遵循一些协议,在读写时要根据协议进行操作,协议主要有 MSI、MESI 等
处理机制
单核 CPU 处理器会自动保证基本内存操作的原子性
多核 CPU 处理器,每个 CPU 处理器内维护了一块内存,每个内核内部维护着一块缓存,当多线程并发读写时,就会出现缓存数据不一致的情况。处理器提供:
- 总线锁定:当处理器要操作共享变量时,在 BUS 总线上发出一个 LOCK 信号,其他处理器就无法操作这个共享变量,该操作会导致大量阻塞,从而增加系统的性能开销(平台级别的加锁)
- 缓存锁定:当处理器对缓存中的共享变量进行了操作,其他处理器有嗅探机制,将各自缓存中的该共享变量的失效,读取时会重新从主内存中读取最新的数据,基于 MESI 缓存一致性协议来实现
有如下两种情况处理器不会使用缓存锁定:
-
当操作的数据跨多个缓存行,或没被缓存在处理器内部,则处理器会使用总线锁定
-
有些处理器不支持缓存锁定,比如:Intel 486 和 Pentium 处理器也会调用总线锁定
总线机制:
-
总线嗅探:每个处理器通过嗅探在总线上传播的数据来检查自己缓存值是否过期了,当处理器发现自己的缓存对应的内存地址的数据被修改,就将当前处理器的缓存行设置为无效状态,当处理器对这个数据进行操作时,会重新从内存中把数据读取到处理器缓存中
-
总线风暴:当某个 CPU 核心更新了 Cache 中的数据,要把该事件广播通知到其他核心(写传播),CPU 需要每时每刻监听总线上的一切活动,但是不管别的核心的 Cache 是否缓存相同的数据,都需要发出一个广播事件,不断的从主内存嗅探和 CAS 循环,无效的交互会导致总线带宽达到峰值;因此不要大量使用 volatile 关键字,使用 volatile、syschonized 都需要根据实际场景
MESI 协议
- E、S、M 状态的缓存行都可以满足 CPU 的读请求
- E 状态的缓存行,有写请求,会将状态改为 M,这时并不触发向主存的写
- E 状态的缓存行,必须监听该缓存行的读操作,如果有,要变为 S 状态
- M 状态的缓存行,必须监听该缓存行的读操作,如果有,先将其它缓存(S 状态)中该缓存行变成 I 状态(即 6. 的流程),写入主存,自己变为 S 状态
- S 状态的缓存行,有写请求,走 4. 的流程
- S 状态的缓存行,必须监听该缓存行的失效操作,如果有,自己变为 I 状态
- I 状态的缓存行,有读请求,必须从主存读取


内存屏障
Memory Barrier(Memory Fence)
可见性
- 写屏障(sfence)保证在该屏障之前,对共享变量的改动,都同步到主存当中
- 读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据
有序性
- 写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
- 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前

*源码之 LongAdder
LongAdder 是并发大师 @author Doug Lea (大哥李)的作品,设计的非常精巧
LongAdder 类有几个关键域
1 | // 累加单元数组, 懒惰初始化 |
其中 Cell 即为累加单元
1 | // 防止缓存行伪共享 |
伪共享
缓存以缓存行 cache line 为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long),在 CPU 从主存获取数据时,以 cache line 为单位加载,于是相邻的数据会一并加载到缓存中
缓存会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中,CPU 要保证数据的一致性,需要做到某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效,这就是伪共享

解决方法:
-
padding:通过填充,让数据落在不同的 cache line 中
-
@Contended:原理参考 无锁 → Adder → 优化机制 → 伪共享

Cell 是数组形式,在内存中是连续存储的,64 位系统中,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),每一个 cache line 为 64 字节,因此缓存行可以存下 2 个的 Cell 对象,当 Core-0 要修改 Cell[0]、Core-1 要修改 Cell[1],无论谁修改成功都会导致当前缓存行失效,从而导致对方的数据失效,需要重新去主存获取,影响效率
@sun.misc.Contended:防止缓存行伪共享,在使用此注解的对象或字段的前后各增加 128 字节大小的 padding,使用 2 倍于大多数硬件缓存行让 CPU 将对象预读至缓存时占用不同的缓存行,这样就不会造成对方缓存行的失效

累加主要调用下面的方法
1 | public void add(long x) { |
总结 :
- 如果已经
有了累加数组或给base累加发生了竞争导致失败- 如果
累加数组没有创建或者累加数组长度为1或者当前线程还没有对应的cell或者累加cell失败- 进入累加数组的创建流程
- 否则说明累加成功,退出。
- 如果
- 否则累加成功
add流程图

1 | final void longAccumulate(long x, LongBinaryOperator fn, |
总结:
- 先判断当前线程有没有对应的Cell
- 如果没有,随机生成一个值,这个值与当前线程绑定,通过这个值的取模运算定位当前线程Cell的位置。
- 进入for循环
- if 有Cells累加数组且长度大于0
- if 如果当前线程没有cell
- 准备扩容,如果前累加数组不繁忙(正在扩容之类)
- 将新建的cell放入对应的槽位中,新建Cell成功,进入下一次循环,尝试cas累加。
- 将collide置为false,表示无需扩容。
- 准备扩容,如果前累加数组不繁忙(正在扩容之类)
- else if 有竞争
- 将wasUncontended置为tue,进入分支底部,改变线程对应的cell来cas重试
- else if cas重试累加成功
- 退出循环。
- else if cells 长度已经超过了最大长度, 或者已经扩容,
- collide置为false,进入分支底部,改变线程对应的 cell 来重试 cas
- else if collide为false
- 将collide置为true(确保 collide 为 false 进入此分支, 就不会进入下面的 else if 进行扩容了)
- else if 累加数组不繁忙且加锁成功
- 退出本次循环,进入下一次循环(扩容)
- 改变线程对应的 cell 来重试 cas
- if 如果当前线程没有cell
- else if 数组不繁忙且数组为null且加锁成功
- 新建数组,在槽位处新建cell,释放锁,退出循环。
- else if 尝试给base累加成功
- 退出循环
- if 有Cells累加数组且长度大于0
longAccumulate 流程图


每个线程刚进入 longAccumulate 时,会尝试对应一个 cell 对象(找到一个坑位)

获取最终结果通过 sum 方法
1 | public long sum() { |
与运算和取模的关系
参考链接:https://www.cnblogs.com/thrillerz/p/4530108.html
5.8 Unsafe
5.8.1 概述
Unsafe 是 CAS 的核心类,由于 Java 无法直接访问底层系统,需要通过本地(Native)方法来访问
Unsafe 类存在 sun.misc 包,其中所有方法都是 native 修饰的,都是直接调用操作系统底层资源执行相应的任务,基于该类可以直接操作特定的内存数据,其内部方法操作类似 C 的指针
Unsafe 对象提供了非常底层的,操作内存、线程的方法,Unsafe 对象不能直接调用,只能通过反射获得。jdk8直接调用Unsafe.getUnsafe()获得的unsafe不能用。
1 | public class UnsafeAccessor { |
方法:
1 | //以下三个方法只执行一次,成功返回true,不成功返回false |
5.8.2 Unsafe CAS 操作
unsafe实现字段更新
1 |
|
1 | Unsafe unsafe = UnsafeAccessor.getUnsafe(); |
输出
Student(id=20, name=张三)
5.8.3 unsafe实现原子整数
1 | class AtomicData { |
Account 实现
1 | Account.demo(new Account() { |
5.8.4 手动实现原子整数完整版+测试
1 |
|
5.9 自定义CAS锁
1 | // 不要用于实践!!! |
测试
1 | LockCas lock = new LockCas(); |
18:27:07.198 c.Test42 [Thread-0] - begin... 18:27:07.202 c.Test42 [Thread-0] - lock... 18:27:07.198 c.Test42 [Thread-1] - begin... 18:27:08.204 c.Test42 [Thread-0] - unlock... 18:27:08.204 c.Test42 [Thread-1] - lock... 18:27:08.204 c.Test42 [Thread-1] - unlock...
6. 共享模型之不可变
这一章强调一种经常被低估的线程安全思路:与其在共享可变状态上反复加锁,不如尽量减少可变状态本身。阅读时可以重点体会“不可变”在并发设计中的简化价值。
6.1 日期转换的问题
下面的代码在运行时,由于 SimpleDateFormat 不是线程安全的
1 | SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); |
有很大几率出现 java.lang.NumberFormatException 或者出现不正确的日期解析结果,例如:
19:10:40.859 [Thread-2] c.TestDateParse - {}
java.lang.NumberFormatException: For input string: ""
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Long.parseLong(Long.java:601)
at java.lang.Long.parseLong(Long.java:631)
at java.text.DigitList.getLong(DigitList.java:195)
at java.text.DecimalFormat.parse(DecimalFormat.java:2084)
at java.text.SimpleDateFormat.subParse(SimpleDateFormat.java:2162)
at java.text.SimpleDateFormat.parse(SimpleDateFormat.java:1514)
at java.text.DateFormat.parse(DateFormat.java:364)
at cn.itcast.n7.TestDateParse.lambda$test1$0(TestDateParse.java:18)
at java.lang.Thread.run(Thread.java:748)
19:10:40.859 [Thread-1] c.TestDateParse - {}
java.lang.NumberFormatException: empty String
at sun.misc.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:1842)
at sun.misc.FloatingDecimal.parseDouble(FloatingDecimal.java:110)
at java.lang.Double.parseDouble(Double.java:538)
at java.text.DigitList.getDouble(DigitList.java:169)
at java.text.DecimalFormat.parse(DecimalFormat.java:2089)
at java.text.SimpleDateFormat.subParse(SimpleDateFormat.java:2162)
at java.text.SimpleDateFormat.parse(SimpleDateFormat.java:1514)
at java.text.DateFormat.parse(DateFormat.java:364)
at cn.itcast.n7.TestDateParse.lambda$test1$0(TestDateParse.java:18)
at java.lang.Thread.run(Thread.java:748)
19:10:40.857 [Thread-8] c.TestDateParse - Sat Apr 21 00:00:00 CST 1951
19:10:40.857 [Thread-9] c.TestDateParse - Sat Apr 21 00:00:00 CST 1951
19:10:40.857 [Thread-6] c.TestDateParse - Sat Apr 21 00:00:00 CST 1951
19:10:40.857 [Thread-4] c.TestDateParse - Sat Apr 21 00:00:00 CST 1951
19:10:40.857 [Thread-5] c.TestDateParse - Mon Apr 21 00:00:00 CST 178960645
19:10:40.857 [Thread-0] c.TestDateParse - Sat Apr 21 00:00:00 CST 1951
19:10:40.857 [Thread-7] c.TestDateParse - Sat Apr 21 00:00:00 CST 1951
19:10:40.857 [Thread-3] c.TestDateParse - Sat Apr 21 00:00:00 CST 1951
解决思路1-同步锁
这样虽能解决问题,但带来的是性能上的损失,并不算很好:
1 | SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); |
解决思路2-不可变
如果一个对象在创建后,其内部状态(属性)无法被修改(即不可变对象),那么它天生就是线程安全的
这样的对象在 Java 中有很多,例如在 Java 8 后,提供了一个新的日期格式化类:
1 | //This class is immutable and thread-safe. |
不可变对象,实际是另一种避免竞争的方式。
6.2 不可变设计
6.2.1 String类的设计
1 | public final class String |
- 将类声明为final,避免被带外星方法的子类继承,从而破坏了不可变性。
- 将字符数组声明为final,避免被修改
- hash虽然不是final的,但是其只有在调用hash()方法的时候才被赋值,除此之外再无别的方法修改。
6.2.2 final的使用
发现该类、类中所有属性都是 final 的
- 属性用 final 修饰保证了该属性是只读的,不能修改
- 类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性
6.2.3 保护性拷贝
但有同学会说,使用字符串时,也有一些跟修改相关的方法啊,比如 substring 等,那么下面就看一看这些方法是 如何实现的,就以 substring 为例:
1 | public String substring(int beginIndex) { |
现其内部是调用 String 的构造方法创建了一个新字符串,并对原有内容进行复制。这种通过创建副本对象来避免共享的手段称之为【保护性拷贝(defensive copy)】
1 | public static String newString(byte[] val, int index, int len) { |
*模式之享元
定义
Flyweight pattern
享元对象是一种通过与其他类似对象共享尽可能多的数据来最小化内存使用的对象
体现
- 包装类
在JDK中 Boolean,Byte,Short,Integer,Long,Character 等包装类提供了 valueOf 方法,例如 Long 的 valueOf 会缓存 -128~127 之间的 Long 对象,在这个范围之间会重用对象,大于这个范围,才会新建 Long 对象:
1 | public static Long valueOf(long l) { |
- Byte, Short, Long 缓存的范围都是 -128~127
- Character 缓存的范围是 0~127
- Integer的默认范围是 -128~127
- 最小值不能变
- 但最大值可以通过调整虚拟机参数
-Djava.lang.Integer.IntegerCache.high来改变- Boolean 缓存了 TRUE 和 FALSE
-
字符串常量池
-
BigDecimal BigInteger
手动实现一个连接池
例如:一个线上商城应用,QPS 达到数千,如果每次都重新创建和关闭数据库连接,性能会受到极大影响。 这时 预先创建好一批连接,放入连接池。一次请求到达后,从连接池获取连接,使用完毕后再还回连接池,这样既节约了连接的创建和关闭时间,也实现了连接的重用,不至于让庞大的连接数压垮数据库。
1 | class Pool { |
使用连接池:
1 | Pool pool = new Pool(2); |
以上实现没有考虑:
- 连接的动态增长与收缩
- 连接保活(可用性检测)
- 等待超时处理
- 分布式 hash
对于关系型数据库,有比较成熟的连接池实现,例如c3p0, druid等 对于更通用的对象池,可以考虑使用apache commons pool,例如redis连接池可以参考jedis中关于连接池的实现
*原理之final
设置 final 变量的原理
理解了 volatile 原理,再对比 final 的实现就比较简单了
1 | public class TestFinal { |
字节码
0: aload_0 1: invokespecial #1 // Method java/lang/Object."":()V 4: aload_0 5: bipush 20 7: putfield #2 // Field a:I <-- 写屏障 10: return
发现 final 变量的赋值也会通过 putfield 指令来完成,同样在这条指令之后也会加入写屏障,这样对final变量的写入不会重排序到构造方法之外,保证在其它线程读到它的值时不会出现为 0 的情况。普通变量则不能保证这一点。
读取final变量原理
1 | public class TestFinal { |
反编译UseFinal1中的test方法:
public test()V
L0
LINENUMBER 31 L0
GETSTATIC java/lang/System.out : Ljava/io/PrintStream;
BIPUSH 10
INVOKEVIRTUAL java/io/PrintStream.println (I)V
L1
LINENUMBER 32 L1
GETSTATIC java/lang/System.out : Ljava/io/PrintStream;
LDC 32768
INVOKEVIRTUAL java/io/PrintStream.println (I)V
L2
LINENUMBER 33 L2
GETSTATIC java/lang/System.out : Ljava/io/PrintStream;
NEW cn/itcast/n5/TestFinal
DUP
INVOKESPECIAL cn/itcast/n5/TestFinal. ()V
INVOKEVIRTUAL java/lang/Object.getClass ()Ljava/lang/Class;
POP
BIPUSH 20
INVOKEVIRTUAL java/io/PrintStream.println (I)V
L3
LINENUMBER 34 L3
GETSTATIC java/lang/System.out : Ljava/io/PrintStream;
NEW cn/itcast/n5/TestFinal
DUP
INVOKESPECIAL cn/itcast/n5/TestFinal. ()V
INVOKEVIRTUAL java/lang/Object.getClass ()Ljava/lang/Class;
POP
LDC 2147483647
INVOKEVIRTUAL java/io/PrintStream.println (I)V
L4
LINENUMBER 35 L4
NEW cn/itcast/n5/TestFinal
DUP
INVOKESPECIAL cn/itcast/n5/TestFinal. ()V
INVOKEVIRTUAL cn/itcast/n5/TestFinal.test1 ()V
L5
LINENUMBER 36 L5
RETURN
L6
LOCALVARIABLE this Lcn/itcast/n5/UseFinal1; L0 L6 0
MAXSTACK = 3
MAXLOCALS = 1
}
常量直接嵌入字节码(L0和L1部分)
BIPUSH 10和LDC 32768直接将final常量的值嵌入到指令中- 无需从TestFinal类中加载,直接在操作数栈中操作
类初始化优化(L2和L4部分)
- 虽然创建了
TestFinal对象(NEW和INVOKESPECIAL) - 但后续仅调用
getClass()后立即POP丢弃结果 - 表明JVM知道这些操作不会影响final变量的值
大常量处理(L3部分)
LDC 2147483647同样直接嵌入最大值- 即使这个值可能来自TestFinal类中的final常量
方法调用优化(L5部分)
INVOKEVIRTUAL cn/itcast/n5/TestFinal.test1 ()V调用- 如果test1()方法使用了final变量,JVM会采用复制优化
jvm对final变量的访问做出了优化:另一个类中的方法调用final变量时,不是从final变量所在类中获取(共享内存),而是直接复制一份到方法栈栈帧中的操作数栈中(工作内存),这样可以提升效率,是一种优化。
总结:
- 对于较小的static final变量:复制一份到操作数栈中
- 对于较大的static final变量:复制一份到当前类的常量池中
- 对于非静态final变量,优化同上。
final总结
final关键字的好处:
(1)final关键字提高了性能。JVM和Java应用都会缓存final变量。
(2)final变量可以安全的在多线程环境下进行共享,而不需要额外的同步开销。
(3)使用final关键字,JVM会对方法、变量及类进行优化。
关于final的重要知识点
- final关键字可以用于成员变量、本地变量、方法以及类。
- 不能够对final变量再次赋值。
- 在匿名类中所有变量都必须是final变量。
- final方法不能被重写。
- final类不能被继承。
- final关键字不同于finally关键字,后者用于异常处理。
- final关键字容易与finalize()方法搞混,后者是在Object类中定义的方法,是在垃圾回收之前被JVM调用的方法。
- 接口中声明的所有变量本身是final的。
- final和abstract这两个关键字是反相关的,final类就不可能是abstract的。
- final方法在编译阶段绑定,称为静态绑定(static binding)。
- 将类、方法、变量声明为final能够提高性能,这样JVM就有机会进行估计,然后优化。
- 按照Java代码惯例,final变量就是常量,而且通常常量名要大写。
- 对于集合对象声明为final指的是引用不能被更改,但可以向其中增加,删除或者改变内容。
- 没有在声明时初始化final变量的称为空白final变量(blank final variable),它们必须在构造器中初始化,或者调用this()初始化。不这么做的话,编译器会报错“final变量(变量名)需要进行初始化”。
6.3 无状态
在 web 阶段学习时,设计 Servlet 时为了保证其线程安全,都会有这样的建议,不要为 Servlet 设置成员变量,这种没有任何成员变量的类是线程安全的。
因为成员变量保存的数据也可以称为状态信息,因此没有成员变量就称之为【无状态】
7. 共享模型之工具
这一章更偏工程实践,聚焦各种并发辅助工具类如何提升开发效率,例如线程池、阻塞队列、同步器、并发集合等。建议把这些工具和实际使用场景关联起来记忆,而不是只背 API。
7.1 线程池
7.1.1 基本概述
线程池:一个容纳多个线程的容器,容器中的线程可以重复使用,省去了频繁创建和销毁线程对象的操作
线程池作用:
- 降低资源消耗,减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务
- 提高响应速度,当任务到达时,如果有线程可以直接用,不会出现系统僵死
- 提高线程的可管理性,如果无限制的创建线程,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
线程池的核心思想:线程复用,同一个线程可以被重复使用,来处理多个任务
池化技术 (Pool) :一种编程技巧,核心思想是资源复用,在请求量大时能优化应用性能,降低系统频繁建连的资源开销
7.1.2 阻塞队列
基本介绍
BlockingQueue 是一个接口,继承自 Queue,所以其实现类也可以作为 Queue 的实现来使用,而 Queue 又继承自 Collection 接口。
1 | public interface BlockingQueue<E> extends Queue<E> {} |
1 | public interface Queue<E> extends Collection<E> {} |
核心方法
BlockingQueue 对插入操作、移除操作、获取元素操作提供了四种不同的方法用于不同场景的使用
| 方法类型 | 抛出异常 | 特殊值 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入(尾) | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除(头) | remove() | poll() | take() | poll(time,unit) |
| 检查(队首元素) | element() | peek() | 不可用 | 不可用 |
- 抛出异常组:
- 当阻塞队列满时:在往队列中 add 插入元素会抛出 IllegalStateException:Queue full
- 当阻塞队列空时:再往队列中 remove 移除元素,会抛出 NoSuchException
- 特殊值组:
- 插入方法:成功 true,失败 false
- 移除方法:成功返回出队列元素,队列没有就返回 null
- 阻塞组:
- 当阻塞队列满时,生产者继续往队列里 put 元素,队列会一直阻塞生产线程直到队列有空间 put 数据或响应中断退出
- 当阻塞队列空时,消费者线程试图从队列里 take 元素,队列会一直阻塞消费者线程直到队列中有可用元素
- 超时退出:当阻塞队列满时,队列会阻塞生产者线程一定时间,超过时限后生产者线程会退出
对于 BlockingQueue,我们的关注点应该在 put(e) 和 take() 这两个方法,因为这两个方法是带阻塞的。
BlockingQueue 不接受 null 值的插入,相应的方法在碰到 null 的插入时会抛出 NullPointerException 异常。null 值在这里通常用于作为特殊值返回(表格中的第三列),代表 poll 失败。所以,如果允许插入 null 值的话,那获取的时候,就不能很好地用 null 来判断到底是代表失败,还是获取的值就是 null 值。
一个 BlockingQueue 可能是有界的,如果在插入的时候,发现队列满了,那么 put 操作将会阻塞。通常,在这里我们说的无界队列也不是说真正的无界,而是它的容量是 Integer.MAX_VALUE(21亿多)。
BlockingQueue 是设计用来实现生产者-消费者队列的,当然,你也可以将它当做普通的 Collection 来用,前面说了,它实现了 java.util.Collection 接口。例如,我们可以用 remove(x) 来删除任意一个元素,但是,这类操作通常并不高效,所以尽量只在少数的场合使用,比如一条消息已经入队,但是需要做取消操作的时候。
BlockingQueue 的实现都是线程安全的,但是批量的集合操作如 addAll, containsAll, retainAll 和 removeAll 不一定是原子操作。如 addAll© 有可能在添加了一些元素后中途抛出异常,此时 BlockingQueue 中已经添加了部分元素,这个是允许的,取决于具体的实现。
BlockingQueue 不支持 close 或 shutdown 等关闭操作,因为开发者可能希望不会有新的元素添加进去,此特性取决于具体的实现,不做强制约束。
最后,BlockingQueue 在生产者-消费者的场景中,是支持多消费者和多生产者的,说的其实就是线程安全问题。
BlockingQueue 实现之 ArrayBlockingQueue
ArrayBlockingQueue 是 BlockingQueue 接口的有界队列实现类,底层采用数组来实现。
其并发控制采用可重入锁来控制,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。
它采用一个 ReentrantLock 和相应的两个 Condition 来实现。
ArrayBlockingQueue 共有以下几个属性:
1 | // 用于存放元素的数组 |
我们用个示意图来描述其同步机制:

ArrayBlockingQueue 实现并发同步的原理就是,读操作和写操作都需要获取到 AQS 独占锁才能进行操作。如果队列为空,这个时候读操作的线程进入到读线程队列排队,等待写线程写入新的元素,然后唤醒读线程队列的第一个等待线程。如果队列已满,这个时候写操作的线程进入到写线程队列排队,等待读线程将队列元素移除腾出空间,然后唤醒写线程队列的第一个等待线程。
对于 ArrayBlockingQueue,我们可以在构造的时候指定以下三个参数:
- 队列容量,其限制了队列中最多允许的元素个数;
- 指定独占锁是公平锁还是非公平锁。非公平锁的吞吐量比较高,公平锁可以保证每次都是等待最久的线程获取到锁;
- 可以指定用一个集合来初始化,将此集合中的元素在构造方法期间就先添加到队列中。
BlockingQueue 实现之 LinkedBlockingQueue
底层基于单向链表实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用。看构造方法:
1 | // 传说中的无界队列 |
1 | // 传说中的有界队列 |
我们看看这个类有哪些属性:
1 | // 队列容量 |
这里用了两个锁,两个 Condition,简单介绍如下:
**takeLock 和 notEmpty 怎么搭配:**如果要获取(take)一个元素,需要获取 takeLock 锁,但是获取了锁还不够,如果队列此时为空,还需要队列不为空(notEmpty)这个条件(Condition)。
**putLock 需要和 notFull 搭配:**如果要插入(put)一个元素,需要获取 putLock 锁,但是获取了锁还不够,如果队列此时已满,还需要队列不是满的(notFull)这个条件(Condition)。
首先,这里用一个示意图来看看 LinkedBlockingQueue 的并发读写控制,然后再开始分析源码:

看懂这个示意图,源码也就简单了,读操作是排好队的,写操作也是排好队的,唯一的并发问题在于一个写操作和一个读操作同时进行,只要控制好这个就可以了。
构造方法:
-
初始化链表
last = head = new Node<E>(null),Dummy 节点用来占位,item 为 null1
2
3
4
5
6public LinkedBlockingQueue(int capacity) {
// 默认是 Integer.MAX_VALUE
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
put 方法:
注意,这里会初始化一个空的头结点,那么第一个元素入队的时候,队列中就会有两个元素。读取元素时,也总是获取头节点后面的一个节点。count 的计数值不包括这个头节点。
我们来看下 put 方法是怎么将元素插入到队尾的:
1 | public void put(E e) throws InterruptedException { |
-
当一个节点入队:
1
2
3
4private void enqueue(Node<E> node) {
// 从右向左计算
last = last.next = node;
}
1 | private void signalNotEmpty() { |
take 方法:
1 | public E take() throws InterruptedException { |
-
当一个节点出队:
1
2
3
4
5
6
7
8
9
10
11
12
13private E dequeue() {
Node<E> h = head;
// 获取临头节点
Node<E> first = h.next;
// 自己指向自己,help GC
h.next = h;
head = first;
// 出队的元素
E x = first.item;
// 【当前节点置为 Dummy 节点】
first.item = null;
return x;
} -
h = head→first = h.next
-
h.next = h→head = first
first.item = null:当前节点置为 Dummy 节点
1 | private void signalNotFull() { |
BlockingQueue 实现之 SynchronousQueue
它是一个特殊的队列,它的名字其实就蕴含了它的特征 - - 同步的队列。为什么说是同步的呢?这里说的并不是多线程的并发问题,而是因为当一个线程往队列中写入一个元素时,写入操作不会立即返回,需要等待另一个线程来将这个元素拿走;同理,当一个读线程做读操作的时候,同样需要一个相匹配的写线程的写操作。这里的 Synchronous 指的就是读线程和写线程需要同步,一个读线程匹配一个写线程。
我们比较少使用到 SynchronousQueue 这个类,不过它在线程池的实现类 ThreadPoolExecutor 中得到了应用,感兴趣的读者可以在看完这个后去看看相应的使用。
虽然上面我说了队列,但是 SynchronousQueue 的队列其实是虚的,其不提供任何空间(一个都没有)来存储元素。数据必须从某个写线程交给某个读线程,而不是写到某个队列中等待被消费。
你不能在 SynchronousQueue 中使用 peek 方法(在这里这个方法直接返回 null),peek 方法的语义是只读取不移除,显然,这个方法的语义是不符合 SynchronousQueue 的特征的。SynchronousQueue 也不能被迭代,因为根本就没有元素可以拿来迭代的。虽然 SynchronousQueue 间接地实现了 Collection 接口,但是如果你将其当做 Collection 来用的话,那么集合是空的。当然,这个类也是不允许传递 null 值的(并发包中的容器类好像都不支持插入 null 值,因为 null 值往往用作其他用途,比如用于方法的返回值代表操作失败)。
源码加注释大概有 1200 行,我们先看大框架:
1 | // 构造时,我们可以指定公平模式还是非公平模式,区别之后再说 |
Transferer 有两个内部实现类,是因为构造 SynchronousQueue 的时候,我们可以指定公平策略。公平模式意味着,所有的读写线程都遵守先来后到,FIFO 嘛,对应 TransferQueue。而非公平模式则对应 TransferStack。
1 | static final class TransferStack<E> extends Transferer<E> {} |
1 | static final class TransferQueue<E> extends Transferer<E> {} |
我们先采用公平模式分析源码,然后再说说公平模式和非公平模式的区别。
接下来,我们看看 put 方法和 take 方法:
1 | // 写入值 |
我们看到,写操作 put(E o) 和读操作 take() 都是调用 Transferer.transfer(…) 方法,区别在于第一个参数是否为 null 值。
我们来看看 transfer 的设计思路,其基本算法如下:
- 当调用这个方法时,如果队列是空的,或者队列中的节点和当前的线程操作类型一致(如当前操作是 put 操作,而队列中的元素也都是写线程)。这种情况下,将当前线程加入到等待队列即可。
- 如果队列中有等待节点,而且与当前操作可以匹配(如队列中都是读操作线程,当前线程是写操作线程,反之亦然)。这种情况下,匹配等待队列的队头,出队,返回相应数据。
其实这里有个隐含的条件被满足了,队列如果不为空,肯定都是同种类型的节点,要么都是读操作,要么都是写操作。这个就要看到底是读线程积压了,还是写线程积压了。
我们可以假设出一个男女配对的场景:一个男的过来,如果一个人都没有,那么他需要等待;如果发现有一堆男的在等待,那么他需要排到队列后面;如果发现是一堆女的在排队,那么他直接牵走队头的那个女的。
既然这里说到了等待队列,我们先看看其实现,也就是 QNode:
1 | static final class QNode { |
我们再来看 transfer 方法的代码就轻松多了。
1 | E transfer(E e, boolean timed, long nanos) { |
下面,再说说前面说的公平模式和非公平模式的区别。
相信大家心里面已经有了公平模式的工作流程的概念了,我就简单说说 TransferStack 的算法,就不分析源码了。
- 当调用这个方法时,如果队列是空的,或者队列中的节点和当前的线程操作类型一致(如当前操作是 put 操作,而栈中的元素也都是写线程)。这种情况下,将当前线程加入到等待栈中,等待配对。然后返回相应的元素,或者如果被取消了的话,返回 null。
- 如果栈中有等待节点,而且与当前操作可以匹配(如栈里面都是读操作线程,当前线程是写操作线程,反之亦然)。将当前节点压入栈顶,和栈中的节点进行匹配,然后将这两个节点出栈。配对和出栈的动作其实也不是必须的,因为下面的一条会执行同样的事情。
- 如果栈顶是进行匹配而入栈的节点,帮助其进行匹配并出栈,然后再继续操作。
应该说,TransferStack 的源码要比 TransferQueue 的复杂一些,如果读者感兴趣,请自行进行源码阅读。
BlockingQueue 实现之 PriorityBlockingQueue
带排序的 BlockingQueue 实现,其并发控制采用的是 ReentrantLock,队列为无界队列(ArrayBlockingQueue 是有界队列,LinkedBlockingQueue 也可以通过在构造函数中传入 capacity 指定队列最大的容量,但是 PriorityBlockingQueue 只能指定初始的队列大小,后面插入元素的时候,如果空间不够的话会自动扩容)。
简单地说,它就是 PriorityQueue 的线程安全版本。不可以插入 null 值,同时,插入队列的对象必须是可比较大小的(comparable),否则报 ClassCastException 异常。它的插入操作 put 方法不会 block,因为它是无界队列(take 方法在队列为空的时候会阻塞)。
它的源码相对比较简单,本节将介绍其核心源码部分。
我们来看看它有哪些属性:
1 | // 构造方法中,如果不指定大小的话,默认大小为 11 |
此类实现了 Collection 和 Iterator 接口中的所有接口方法,对其对象进行迭代并遍历时,不能保证有序性。如果你想要实现有序遍历,建议采用 Arrays.sort(queue.toArray()) 进行处理。PriorityBlockingQueue 提供了 drainTo 方法用于将部分或全部元素有序地填充(准确说是转移,会删除原队列中的元素)到另一个集合中。还有一个需要说明的是,如果两个对象的优先级相同(compare 方法返回 0),此队列并不保证它们之间的顺序。
PriorityBlockingQueue 使用了基于数组的二叉堆来存放元素,所有的 public 方法采用同一个 lock 进行并发控制。
二叉堆:一颗完全二叉树,它非常适合用数组进行存储,对于数组中的元素 a[i],其左子节点为 a[2*i+1],其右子节点为 a[2*i + 2],其父节点为 a[(i-1)/2],其堆序性质为,每个节点的值都小于其左右子节点的值。二叉堆中最小的值就是根节点,但是删除根节点是比较麻烦的,因为需要调整树。
简单用个图解释一下二叉堆,我就不说太多专业的严谨的术语了,这种数据结构的优点是一目了然的,最小的元素一定是根元素,它是一棵满的树,除了最后一层,最后一层的节点从左到右紧密排列。

下面开始 PriorityBlockingQueue 的源码分析,首先我们来看看构造方法:
1 | // 默认构造方法,采用默认值(11)来进行初始化 |
接下来,我们来看看其内部的自动扩容实现:
1 | private void tryGrow(Object[] array, int oldCap) { |
扩容方法对并发的控制也非常的巧妙,释放了原来的独占锁 lock,这样的话,扩容操作和读操作可以同时进行,提高吞吐量。
下面,我们来分析下写操作 put 方法和读操作 take 方法。
1 | public void put(E e) { |
对于二叉堆而言,插入一个节点是简单的,插入的节点如果比父节点小,交换它们,然后继续和父节点比较。
1 | // 这个方法就是将数据 x 插入到数组 es 的位置 k 处,然后再调整树 |
我们用图来示意一下,我们接下来要将 11 插入到队列中,看看 siftUp 是怎么操作的。

我们再看看 take 方法:
1 | public E take() throws InterruptedException { |
1 | private E dequeue() { |
dequeue 方法返回队头,并调整二叉堆的树,调用这个方法必须先获取独占锁。
废话不多说,出队是非常简单的,因为队头就是最小的元素,对应的是数组的第一个元素。难点是队头出队后,需要调整树。
1 | private static <T> void siftDownComparable(int k, T x, Object[] es, int n) { |

记住二叉堆是一棵完全二叉树,那么根节点 10 拿掉后,最后面的元素 17 必须找到合适的地方放置。首先,17 和 10 不能直接交换,那么先将根节点 10 的左右子节点中较小的节点往上滑,即 12 往上滑,然后原来 12 留下了一个空节点,然后再把这个空节点的较小的子节点往上滑,即 13 往上滑,最后,留出了位子,17 补上即可。
我稍微调整下这个树,以便读者能更明白:

BlockingQueue 实现之 DelayedWorkQueue
DelayedWorkQueue 是支持延时获取元素的阻塞队列,内部采用优先队列 PriorityQueue(小根堆、满二叉树)存储元素
其他阻塞队列存储节点的数据结构大多是链表,延迟队列是数组,所以延迟队列出队头元素后需要让其他元素(尾)替换到头节点,防止空指针异常
成员变量
-
容量:
1
2
3private static final int INITIAL_CAPACITY = 16;
private RunnableScheduledFuture<?>[] queue =new RunnableScheduledFuture<?>[INITIAL_CAPACITY];
private int size; -
锁:
1
2private final ReentrantLock lock = new ReentrantLock(); // 控制并发
private final Condition available = lock.newCondition();// 条件队列 -
阻塞等待头节点的线程:线程池内的某个线程去 take() 获取任务时,如果延迟队列顶层节点不为 null(队列内有任务),但是节点任务还不到触发时间,线程就去检查队列的 leader字段是否被占用
- 如果未被占用,则当前线程占用该字段,然后当前线程到 available 条件队列指定超时时间
堆顶任务.time - now()挂起 - 如果被占用,当前线程直接到 available 条件队列不指定超时时间的挂起
1
2// leader 在 available 条件队列内是首元素,它超时之后会醒过来,然后再次将堆顶元素获取走,获取走之后,take()结束之前,会调用是 available.signal() 唤醒下一个条件队列内的等待者,然后释放 lock,下一个等待者被唤醒后去到 AQS 队列,做 acquireQueue(node) 逻辑
private Thread leader = null; - 如果未被占用,则当前线程占用该字段,然后当前线程到 available 条件队列指定超时时间
成员方法
-
offer():插入节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40public boolean offer(Runnable x) {
// 判空
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>)x;
// 队列锁,增加删除数据时都要加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = size;
// 队列数量大于存放节点的数组长度,需要扩容
if (i >= queue.length)
// 扩容为原来长度的 1.5 倍
grow();
size = i + 1;
// 当前是第一个要插入的节点
if (i == 0) {
queue[0] = e;
// 修改 ScheduledFutureTask 的 heapIndex 属性,表示该对象在队列里的下标
setIndex(e, 0);
} else {
// 向上调整元素的位置,并更新 heapIndex
siftUp(i, e);
}
// 情况1:当前任务是第一个加入到 queue 内的任务,所以在当前任务加入到 queue 之前,take() 线程会直接
// 到 available 队列不设置超时的挂起,并不会去占用 leader 字段,这时需会唤醒一个线程 让它去消费
// 情况2:当前任务【优先级最高】,原堆顶任务可能还未到触发时间,leader 线程设置超时的在 available 挂起
// 原先的 leader 等待的是原先的头节点,所以 leader 已经无效,需要将 leader 线程唤醒,
// 唤醒之后它会检查堆顶,如果堆顶任务可以被消费,则直接获取走,否则继续成为 leader 等待新堆顶任务
if (queue[0] == e) {
// 将 leader 设置为 null
leader = null;
// 直接随便唤醒等待头结点的阻塞线程
available.signal();
}
} finally {
lock.unlock();
}
return true;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 插入新节点后对堆进行调整,进行节点上移,保持其特性【节点的值小于子节点的值】,小顶堆
private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
// 父节点,就是堆排序
int parent = (k - 1) >>> 1;
RunnableScheduledFuture<?> e = queue[parent];
// key 和父节点比,如果大于父节点可以直接返回,否则就继续上浮
if (key.compareTo(e) >= 0)
break;
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
} -
poll():非阻塞获取头结点,获取执行时间最近并且可以执行的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 非阻塞获取
public RunnableScheduledFuture<?> poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 获取队头节点,因为是小顶堆
RunnableScheduledFuture<?> first = queue[0];
// 头结点为空或者的延迟时间没到返回 null
if (first == null || first.getDelay(NANOSECONDS) > 0)
return null;
else
// 头结点达到延迟时间,【尾节点成为替代节点下移调整堆结构】,返回头结点
return finishPoll(first);
} finally {
lock.unlock();
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {
// 获取尾索引
int s = --size;
// 获取尾节点
RunnableScheduledFuture<?> x = queue[s];
// 将堆结构最后一个节点占用的 slot 设置为 null,因为该节点要尝试升级成堆顶,会根据特性下调
queue[s] = null;
// s == 0 说明 当前堆结构只有堆顶一个节点,此时不需要做任何的事情
if (s != 0)
// 从索引处 0 开始向下调整
siftDown(0, x);
// 出队的元素索引设置为 -1
setIndex(f, -1);
return f;
} -
take():阻塞获取头节点,读取当前堆中最小的也就是触发时间最近的任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
// 保证线程安全
lock.lockInterruptibly();
try {
for (;;) {
// 头节点
RunnableScheduledFuture<?> first = queue[0];
if (first == null)
// 等待队列不空,直至有任务通过 offer 入队并唤醒
available.await();
else {
// 获取头节点的延迟时间是否到时
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
// 到达触发时间,获取头节点并调整堆,重新选择延迟时间最小的节点放入头部
return finishPoll(first);
// 逻辑到这说明头节点的延迟时间还没到
first = null;
// 说明有 leader 线程在等待获取头节点,当前线程直接去阻塞等待
if (leader != null)
available.await();
else {
// 没有 leader 线程,【当前线程作为leader线程,并设置头结点的延迟时间作为阻塞时间】
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
// 在条件队列 available 使用带超时的挂起(堆顶任务.time - now() 纳秒值..)
available.awaitNanos(delay);
// 到达阻塞时间时,当前线程会从这里醒来来
} finally {
// t堆顶更新,leader 置为 null,offer 方法释放锁后,
// 有其它线程通过 take/poll 拿到锁,读到 leader == null,然后将自身更新为leader。
if (leader == thisThread)
// leader 置为 null 用以接下来判断是否需要唤醒后继线程
leader = null;
}
}
}
}
} finally {
// 没有 leader 线程,头结点不为 null,唤醒阻塞获取头节点的线程,
// 【如果没有这一步,就会出现有了需要执行的任务,但是没有线程去执行】
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
} -
remove():删除节点,堆移除一个元素的时间复杂度是 O(log n),延迟任务维护了 heapIndex,直接访问的时间复杂度是 O(1),从而可以更快的移除元素,任务在队列中被取消后会进入该逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public boolean remove(Object x) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 查找对象在队列数组中的下标
int i = indexOf(x);
// 节点不存在,返回 false
if (i < 0)
return false;
// 修改元素的 heapIndex,-1 代表删除
setIndex(queue[i], -1);
// 尾索引是长度-1
int s = --size;
// 尾节点作为替代节点
RunnableScheduledFuture<?> replacement = queue[s];
queue[s] = null;
// s == i 说明头节点就是尾节点,队列空了
if (s != i) {
// 向下调整
siftDown(i, replacement);
// 说明没发生调整
if (queue[i] == replacement)
// 上移和下移不可能同时发生,替代节点大于子节点时下移,否则上移
siftUp(i, replacement);
}
return true;
} finally {
lock.unlock();
}
}
总结
ArrayBlockingQueue 底层是数组,有界队列,如果我们要使用生产者-消费者模式,这是非常好的选择。
LinkedBlockingQueue 底层是链表,可以当做无界和有界队列来使用,所以大家不要以为它就是无界队列。
SynchronousQueue 本身不带有空间来存储任何元素,使用上可以选择公平模式和非公平模式。
PriorityBlockingQueue 是无界队列,基于数组,数据结构为二叉堆,数组第一个也是树的根节点总是最小值。
7.1.3 自定义线程池

1. 自定义任务队列
Blocking Queue是用于 平衡生产者与消费者的桥梁
1 | static class BlockingQueue<T> { |
2. 自定义线程池
1 | static class ThreadPool { |
1 | public static void main(String[] args) { |
输出
[main] INFO com.lxd.juc.TestPool -- 新增 worker:【Thread[Thread-0,5,main]】,task:【com.lxd.juc.TestPool$$Lambda$19/0x0000007001018cc0@75412c2f】 [main] INFO com.lxd.juc.TestPool -- 新增 worker:【Thread[Thread-1,5,main]】,task:【com.lxd.juc.TestPool$$Lambda$19/0x0000007001018cc0@2cfb4a64】 [Thread-0] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x0000007001018cc0@75412c2f】 [Thread-0] INFO com.lxd.juc.TestPool -- 0 [Thread-1] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x0000007001018cc0@2cfb4a64】 [Thread-1] INFO com.lxd.juc.TestPool -- 1 [main] INFO com.lxd.juc.TestPool -- 加入任务队列【com.lxd.juc.TestPool$$Lambda$19/0x0000007001018cc0@4b6995df】 [Thread-1] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x0000007001018cc0@4b6995df】 [Thread-1] INFO com.lxd.juc.TestPool -- 2 [main] INFO com.lxd.juc.TestPool -- 加入任务队列【com.lxd.juc.TestPool$$Lambda$19/0x0000007001018cc0@2fc14f68】 [main] INFO com.lxd.juc.TestPool -- 加入任务队列【com.lxd.juc.TestPool$$Lambda$19/0x0000007001018cc0@591f989e】 [Thread-1] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x0000007001018cc0@2fc14f68】 [Thread-0] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x0000007001018cc0@591f989e】 [Thread-1] INFO com.lxd.juc.TestPool -- 3 [Thread-0] INFO com.lxd.juc.TestPool -- 4
任务都执行完毕,程序并未结束,task = taskQueue.get()会一直等待
修改为带有超时时间的方案taskQueue.poll(timeout, timeUnit),程序结束正常退出
[main] INFO com.lxd.juc.TestPool -- 新增 worker:【Thread[Thread-0,5,main]】,task:【com.lxd.juc.TestPool$$Lambda$19/0x000000c801018cc0@75412c2f】 [main] INFO com.lxd.juc.TestPool -- 新增 worker:【Thread[Thread-1,5,main]】,task:【com.lxd.juc.TestPool$$Lambda$19/0x000000c801018cc0@2cfb4a64】 [Thread-0] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x000000c801018cc0@75412c2f】 [Thread-0] INFO com.lxd.juc.TestPool -- 0 [main] INFO com.lxd.juc.TestPool -- 加入任务队列【com.lxd.juc.TestPool$$Lambda$19/0x000000c801018cc0@4b6995df】 [Thread-1] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x000000c801018cc0@2cfb4a64】 [Thread-1] INFO com.lxd.juc.TestPool -- 1 [Thread-0] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x000000c801018cc0@4b6995df】 [main] INFO com.lxd.juc.TestPool -- 加入任务队列【com.lxd.juc.TestPool$$Lambda$19/0x000000c801018cc0@2fc14f68】 [Thread-0] INFO com.lxd.juc.TestPool -- 2 [main] INFO com.lxd.juc.TestPool -- 加入任务队列【com.lxd.juc.TestPool$$Lambda$19/0x000000c801018cc0@591f989e】 [Thread-1] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x000000c801018cc0@2fc14f68】 [Thread-1] INFO com.lxd.juc.TestPool -- 3 [Thread-0] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x000000c801018cc0@591f989e】 [Thread-0] INFO com.lxd.juc.TestPool -- 4 [Thread-0] INFO com.lxd.juc.TestPool -- 移除worker【Thread[Thread-0,5,main]】 [Thread-1] INFO com.lxd.juc.TestPool -- 移除worker【Thread[Thread-1,5,main]】
模拟任务数超过任务队列的情况
1 | public static void main(String[] args) { |
23:25:20.902 [main] INFO com.lxd.juc.TestPool -- 新增 worker:【Thread[Thread-0,5,main]】,task:【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@75412c2f】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 新增 worker:【Thread[Thread-1,5,main]】,task:【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@2cfb4a64】 23:25:20.904 [Thread-0] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@75412c2f】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 添加任务至taskQueue中【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@4b6995df】 23:25:20.904 [Thread-1] INFO com.lxd.juc.TestPool -- 执行任务【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@2cfb4a64】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 添加任务至taskQueue中【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@2fc14f68】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 添加任务至taskQueue中【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@591f989e】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 添加任务至taskQueue中【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@66048bfd】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 添加任务至taskQueue中【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@61443d8f】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 添加任务至taskQueue中【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@445b84c0】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 添加任务至taskQueue中【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@61a52fbd】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 添加任务至taskQueue中【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@233c0b17】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 添加任务至taskQueue中【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@63d4e2ba】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 添加任务至taskQueue中【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@7bb11784】 23:25:20.904 [main] INFO com.lxd.juc.TestPool -- 队列已满等待中....【com.lxd.juc.TestPool$$Lambda$19/0x0000000601018cc0@33a10788】
增强阻塞队列的功能
1 | //待超时时间的阻塞添加 |
队列满时支持的操作
1 | /** |
3. 自定义拒绝策略接口
1 |
|
4. 完整实现
1 | static class BlockingQueue<T> { |
1 | static class ThreadPool { |
1 | public static void main(String[] args) { |
7.1.4 ThreadPoolExecutor

- ScheduledThreadPoolExecutor是带调度的线程池
- ThreadPoolExecutor是不带调度的线程池
构造方法
1 | public ThreadPoolExecutor(int corePoolSize, |
参数介绍:
-
corePoolSize:核心线程数,定义了最小可以同时运行的线程数量
-
maximumPoolSize:最大线程数,当队列中存放的任务达到队列容量时,当前可以同时运行的数量变为最大线程数,创建线程并立即执行最新的任务,与核心线程数之间的差值又叫救急线程数
-
keepAliveTime:救急线程最大存活时间,当线程池中的线程数量大于 corePoolSize 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等到 keepAliveTime 时间超过销毁
-
unit:keepAliveTime 参数的时间单位
-
workQueue:阻塞队列,存放被提交但尚未被执行的任务
-
threadFactory:线程工厂,创建新线程时用到,可以为线程创建时起名字
-
handler:拒绝策略,线程到达最大线程数仍有新任务时会执行拒绝策略
RejectedExecutionHandler 下有 4 个实现类:
- AbortPolicy:让调用者抛出 RejectedExecutionException 异常,默认策略
- CallerRunsPolicy:让调用者运行的调节机制,将某些任务回退到调用者,从而降低新任务的流量
- DiscardPolicy:直接丢弃任务,不予任何处理也不抛出异常
- DiscardOldestPolicy:放弃队列中最早的任务,把当前任务加入队列中尝试再次提交当前任务
补充:其他框架拒绝策略
- Dubbo:在抛出 RejectedExecutionException 异常前记录日志,并 dump 线程栈信息,方便定位问题
- Netty:创建一个新线程来执行任务
- ActiveMQ:带超时等待(60s)尝试放入队列
- PinPoint:它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略
工作原理:

- 创建线程池,这时没有创建线程(懒惰),等待提交过来的任务请求,调用 execute 方法才会创建线程
- 当调用 execute() 方法添加一个请求任务时,线程池会做如下判断:
- 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务
- 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列
- 如果这时队列满了且正在运行的线程数量还小于 maximumPoolSize,那么会创建非核心线程立刻运行这个任务,对于阻塞队列中的任务不公平。这是因为创建每个 Worker(线程)对象会绑定一个初始任务,启动 Worker 时会优先执行
- 如果队列满了且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会启动饱和拒绝策略来执行
- 当一个线程完成任务时,会从队列中取下一个任务来执行
- 当一个线程空闲超过一定的时间(keepAliveTime)时,线程池会判断:如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉,所以线程池的所有任务完成后最终会收缩到 corePoolSize 大小
根据这个构造方法,JDK Executors 类中提供了众多工厂方法来创建各种用途的线程池。
newFixedThreadPool
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
内部调用了:ThreadPoolExecutor的一个构造方法
1 | public ThreadPoolExecutor(int corePoolSize, |
默认工厂以及默认构造线程的方法:
1 | public static ThreadFactory defaultThreadFactory() { |
默认拒绝策略:抛出异常
1 | private static final RejectedExecutionHandler defaultHandler = new AbortPolicy(); |
特点
- 核心线程数 == 最大线程数(没有救急线程被创建),因此也无需超时时间
- LinkedBlockingQueue 是一个单向链表实现的阻塞队列,默认大小为
Integer.MAX_VALUE,也就是无界队列,可以放任意数量的任务,在任务比较多的时候会导致 OOM(内存溢出)
适用于任务量已知,相对耗时的任务
newCachedThreadPool
1 | public static ExecutorService newCachedThreadPool() { |
特点
- 核心线程数是 0, 最大线程数是Integer.MAX_VALUE ,全部都是救急线程(60s 后可以回收),可能会创建大量线程,从而导致 OOM
- SynchronousQueue 作为阻塞队列,没有容量,对于每一个 take 的线程会阻塞直到有一个 put 的线程放入元素为止(类似一手交钱、一手交货)
1 | SynchronousQueue<Integer> integers = new SynchronousQueue<>(); |
输出
11:48:15.500 c.TestSynchronousQueue [t1] - putting 1 11:48:16.500 c.TestSynchronousQueue [t2] - taking 1 11:48:16.500 c.TestSynchronousQueue [t1] - 1 putted... 11:48:16.500 c.TestSynchronousQueue [t1] - putting...2 11:48:17.502 c.TestSynchronousQueue [t3] - taking 2 11:48:17.503 c.TestSynchronousQueue [t1] - 2 putted...
整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲 1分钟后释放线程。 适合任务数比较密集,但每个任务执行时间较短的情况
newSingleThreadExecutor
1 | public static ExecutorService newSingleThreadExecutor() { |
使用场景:
保证所有任务按照指定顺序执行,线程数固定为 1,任务数多于 1 时,会放入无界队列排队。任务执行完毕,这唯一的线程也不会被释放。
区别:
- 自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建一个线程,保证池的正常工作
- Executors.newSingleThreadExecutor() 线程个数始终为1,不能修改
- FinalizableDelegatedExecutorService 应用的是装饰器模式,在调用构造方法时将ThreadPoolExecutor对象传给了内部的ExecutorService接口。只对外暴露了 ExecutorService 接口,因此不能调用 ThreadPoolExecutor 中特有的方法,也不能重新设置线程池的大小。
- Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改
- 对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改

阿里巴巴 Java 开发手册要求:
线程资源必须通过线程池提供,不允许在应用中自行显式创建线程
- 使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题
- 如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者过度切换的问题
线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式更加明确线程池的运行规则,规避资源耗尽的风险
Executors 返回的线程池对象弊端如下:
- FixedThreadPool 和 SingleThreadPool:请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM
- CacheThreadPool 和 ScheduledThreadPool:允许创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,导致 OOM
创建多大容量的线程池合适?
一般来说池中总线程数是核心池线程数量两倍,确保当核心池有线程停止时,核心池外有线程进入核心池
过小会导致程序不能充分地利用系统资源、容易导致饥饿
过大会导致更多的线程上下文切换,占用更多内存
上下文切换:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态,任务从保存到再加载的过程就是一次上下文切换
核心线程数常用公式:
CPU 密集型任务 (N+1): 这种任务消耗的是 CPU 资源,可以将核心线程数设置为 N (CPU 核心数) + 1,比 CPU 核心数多出来的一个线程是为了防止线程发生缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 某个核心就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如在内存中对大量数据进行分析
I/O 密集型任务: 这种系统 CPU 处于阻塞状态,用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用,因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N 或 CPU 核数/ (1-阻塞系数),阻塞系数在 0.8~0.9 之间
IO 密集型就是涉及到网络读取,文件读取此类任务 ,特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上
提交任务
ExecutorService 类 API:
| 方法 | 说明 |
|---|---|
void execute(Runnable command) |
执行任务(Executor 类 API),无返回值,适用于无需结果反馈的异步操作。 |
Future<?> submit(Runnable task) |
提交任务 task,返回 Future 对象用于判断任务是否完成(get() 阻塞等待)。 |
<T> Future<T> submit(Callable<T> task) |
提交任务 task,通过 Future 获取任务执行结果(含返回值)。 |
<T> Future<T> submit(Runnable task, T result) |
提交任务 task,任务完成后返回指定的 result(通过 Future 获取)。 |
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) |
提交 tasks 中所有任务,返回所有任务的 Future 列表(按提交顺序)。 |
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) |
提交所有任务,若整体超时,未完成的任务会被取消并抛出 TimeoutException。 |
<T> T invokeAny(Collection<? extends Callable<T>> tasks) |
提交所有任务,返回首个成功执行的任务结果(其余任务自动取消)。 |
<T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) |
提交所有任务,在指定超时时间内返回首个成功结果,超时抛出 TimeoutException。 |
execute 和 submit 都属于线程池的方法,对比:
-
execute 只能执行 Runnable 类型的任务,没有返回值; submit 既能提交 Runnable 类型任务也能提交 Callable 类型任务,底层是封装成 FutureTask,然后调用 execute 执行
-
execute 会直接抛出任务执行时的异常,submit 会吞掉异常,可通过 Future 的 get 方法将任务执行时的异常重新抛出
关闭线程池
ExecutorService 类 API:
| 方法 | 说明 |
|---|---|
void shutdown() |
优雅关闭: • 线程池状态变为 SHUTDOWN,不再接收新任务 • 已提交任务会继续执行完成 • 允许动态调整线程数(如添加空闲线程) |
List<Runnable> shutdownNow() |
强制关闭: • 线程池状态变为 STOP,立即中断正在执行的任务 • 返回队列中未执行的任务列表 • 适用于紧急终止场景 |
boolean isShutdown() |
状态检查: • 若线程池非 RUNNING 状态(如 SHUTDOWN/STOP/TERMINATED)则返回 true |
boolean isTerminated() |
终结检查: • 仅当所有任务完成且线程池资源释放后返回 true • 需先调用 shutdown() 或 shutdownNow() 才会触发此状态 |
boolean awaitTermination(long timeout, TimeUnit unit) |
阻塞等待: • 调用后阻塞当前线程,直到所有任务完成或超时 • 返回 true 表示线程池已终止 • 典型用途:关闭后执行清理逻辑 |
处理任务异常
execute 会直接抛出任务执行时的异常,submit 会吞掉异常,有两种处理方法
方法1:主动捉异常
1 | ExecutorService pool = Executors.newFixedThreadPool(1); |
方法2:使用 Future
- lambda表达式内要有返回值,编译器才能将其识别为Callable,否则将识别为Runnable,也就不能用FutureTask
- 方法中如果出异常,
futuretask.get会返回这个异常,否则正常返回。
1 | ExecutorService pool = Executors.newFixedThreadPool(1); |
7.1.5 工作原理
状态信息
ThreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量。这些信息存储在一个原子变量 ctl 中,目的是将线程池状态与线程个数合二为一,这样就可以用一次 CAS 原子操作进行赋值
-
状态表示:
1
2
3
4
5
6// 高3位:表示当前线程池运行状态,除去高3位之后的低位:表示当前线程池中所拥有的线程数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 表示在 ctl 中,低 COUNT_BITS 位,是用于存放当前线程数量的位
private static final int COUNT_BITS = Integer.SIZE - 3;
// 低 COUNT_BITS 位所能表达的最大数值,000 11111111111111111111 => 约5.36亿
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;
-
四种状态:
1
2
3
4
5
6
7
8
9
10// 111 000000000000000000,转换成整数后其实就是一个【负数】 -536870912
private static final int RUNNING = -1 << COUNT_BITS;
// 000 000000000000000000 0
private static final int SHUTDOWN = 0 << COUNT_BITS;
// 001 000000000000000000 536870912
private static final int STOP = 1 << COUNT_BITS;
// 010 000000000000000000 1073741824
private static final int TIDYING = 2 << COUNT_BITS;
// 011 000000000000000000 1610612736
private static final int TERMINATED = 3 << COUNT_BITS;状态 高3位 接收新任务 处理阻塞任务队列 说明 RUNNING 111 Y Y SHUTDOWN 000 N Y 不接收新任务,但处理阻塞队列剩余任务 STOP 001 N N 中断正在执行的任务,并抛弃阻塞队列任务 TIDYING 010 - - 任务全执行完毕,活动线程为 0 即将进入终结 TERMINATED 011 - - 终止状态 -
获取当前线程池运行状态:
1
private static int runStateOf(int c) { return c & ~COUNT_MASK; }
-
获取当前线程池线程数量:
1
private static int workerCountOf(int c) { return c & COUNT_MASK; }
-
重置当前线程池状态 ctl:
1
2// rs 表示线程池状态,wc 表示当前线程池中 worker(线程)数量,相与以后就是合并后的状态
private static int ctlOf(int rs, int wc) { return rs | wc; } -
比较当前线程池 ctl 所表示的状态:
1
2
3
4
5
6
7// 比较当前线程池 ctl 所表示的状态,是否小于某个状态 s
// 状态对比:RUNNING < SHUTDOWN < STOP < TIDYING < TERMINATED
private static boolean runStateLessThan(int c, int s) { return c < s; }
// 比较当前线程池 ctl 所表示的状态,是否大于等于某个状态s
private static boolean runStateAtLeast(int c, int s) { return c >= s; }
// 小于 SHUTDOWN 的一定是 RUNNING,SHUTDOWN == 0
private static boolean isRunning(int c) { return c < SHUTDOWN; } -
设置线程池 ctl:
1
2
3
4
5
6
7
8
9
10
11
12// 使用 CAS 方式 让 ctl 值 +1 ,成功返回 true, 失败返回 false
private boolean compareAndIncrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect + 1);
}
// 使用 CAS 方式 让 ctl 值 -1 ,成功返回 true, 失败返回 false
private boolean compareAndDecrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect - 1);
}
// 减少 ctl 的 workerCount 字段。仅在线程突然终止时调用
private void decrementWorkerCount() {
ctl.addAndGet(-1);
}
成员属性
成员变量
-
线程池中存放 Worker 的容器:线程池没有初始化,直接往池中加线程即可
1
private final HashSet<Worker> workers = new HashSet<>();
-
线程全局锁:
1
2// 增加减少 worker 或者 修改线程池运行状态需要持有 mainLock
private final ReentrantLock mainLock = new ReentrantLock(); -
可重入锁的条件变量:
1
2// 当外部线程调用 awaitTermination() 方法时,会等待当前线程池状态为 Termination 为止
private final Condition termination = mainLock.newCondition() -
线程池相关参数:
1
2
3
4
5private volatile int corePoolSize; // 核心线程数量
private volatile int maximumPoolSize; // 线程池最大线程数量
private volatile long keepAliveTime; // 空闲线程存活时间
private volatile ThreadFactory threadFactory; // 创建线程时使用的线程工厂,默认是 DefaultThreadFactory
private final BlockingQueue<Runnable> workQueue;// 【超过核心线程提交任务就放入 阻塞队列】1
2private volatile RejectedExecutionHandler handler; // 拒绝策略,juc包提供了4中方式
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();// 默认策略 -
记录线程池相关属性的数值:
1
2private int largestPoolSize; // 记录线程池生命周期内线程数最大值
private long completedTaskCount; // 记录线程池所完成任务总数,当某个 worker 退出时将完成的任务累加到该属性 -
控制核心线程数量内的线程是否可以被回收:
1
2
3// false(默认)代表不可以,为 true 时核心线程空闲超过 keepAliveTime 也会被回收
// allowCoreThreadTimeOut(boolean value) 方法可以设置该值
private volatile boolean allowCoreThreadTimeOut;
内部类:
-
Worker 类:每个 Worker 对象会绑定一个初始任务,启动 Worker 时优先执行,这也是造成线程池不公平的原因。Worker 继承自 AQS,本身具有锁的特性,采用独占锁模式,state = 0 表示未被占用,> 0 表示被占用,< 0 表示初始状态不能被抢锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread; // worker 内部封装的工作线程
Runnable firstTask; // worker 第一个执行的任务,普通的 Runnable 实现类或者是 FutureTask
volatile long completedTasks; // 记录当前 worker 所完成任务数量
// 构造方法
Worker(Runnable firstTask) {
// 设置AQS独占模式为初始化中状态,这个状态不能被抢占锁
setState(-1);
// firstTask不为空时,当worker启动后,内部线程会优先执行firstTask,执行完后会到queue中去获取下个任务
this.firstTask = firstTask;
// 使用线程工厂创建一个线程,并且【将当前worker指定为Runnable】,所以thread启动时会调用 worker.run()
this.thread = getThreadFactory().newThread(this);
}
}1
2
3
4
5
6
7
8
9public Thread newThread(Runnable r) {
// 将当前 worker 指定为 thread 的执行方法,线程调用 start 会调用 r.run()
Thread t = new Thread(group, r, namePrefix + threadNumber.getAndIncrement(), 0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
} -
拒绝策略相关的内部类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { }
/**
* Always throws RejectedExecutionException.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
* @throws RejectedExecutionException always
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
/**
* Does nothing, which has the effect of discarding task r.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public static class DiscardOldestPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardOldestPolicy} for the given executor.
*/
public DiscardOldestPolicy() { }
/**
* Obtains and ignores the next task that the executor
* would otherwise execute, if one is immediately available,
* and then retries execution of task r, unless the executor
* is shut down, in which case task r is instead discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public static class CallerRunsPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code CallerRunsPolicy}.
*/
public CallerRunsPolicy() { }
/**
* Executes task r in the caller's thread, unless the executor
* has been shut down, in which case the task is discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
成员方法
提交方法
-
AbstractExecutorService#submit():提交任务,把 Runnable 或 Callable 任务封装成 FutureTask 执行,可以通过方法返回的任务对象,调用 get 阻塞获取任务执行的结果或者异常,源码分析在笔记的 Future 部分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78/**
* 提交一个Runnable任务用于执行,并返回一个Future对象
* 该Future对象代表任务的挂起完成状态
*
* @param task 要执行的任务
* @return 代表任务等待完成的Future对象
* @throws NullPointerException 如果task为null
*/
public Future<?> submit(Runnable task) {
// 检查任务是否为null,如果是则抛出NullPointerException
if (task == null) throw new NullPointerException();
// 将Runnable任务包装成RunnableFuture对象
// newTaskFor方法会创建一个FutureTask实例来包装任务
// FutureTask实现了RunnableFuture接口,既可执行又可获取结果
// 对于Runnable任务,结果为null
RunnableFuture<Void> ftask = newTaskFor(task, null);
// 调用execute方法执行任务
// execute方法会按照线程池的策略将任务交给合适的Worker执行
execute(ftask);
// 返回Future对象,调用者可以通过它检查任务状态和获取结果
return ftask;
}
/**
* 提交一个Runnable任务用于执行,并返回一个Future对象
* Future的get方法在成功完成时会返回给定的结果
*
* @param task 要执行的任务
* @param result 任务成功完成时返回的结果
* @return 代表任务等待完成的Future对象
* @throws NullPointerException 如果task为null
*/
public <T> Future<T> submit(Runnable task, T result) {
// 检查任务是否为null,如果是则抛出NullPointerException
if (task == null) throw new NullPointerException();
// 将Runnable任务包装成RunnableFuture对象
// newTaskFor方法会创建一个FutureTask实例来包装任务
// FutureTask实现了RunnableFuture接口,既可执行又可获取结果
// 对于Runnable任务,当任务完成时返回指定的result值
RunnableFuture<T> ftask = newTaskFor(task, result);
// 调用execute方法执行任务
// execute方法会按照线程池的策略将任务交给合适的Worker执行
execute(ftask);
// 返回Future对象,调用者可以通过它检查任务状态和获取结果
return ftask;
}
/**
* 提交一个Callable任务用于执行,并返回一个Future对象
* Future对象代表任务的挂起完成状态,其get方法在成功完成时会返回任务的结果
*
* @param task 要执行的任务
* @return 代表任务等待完成的Future对象
* @throws NullPointerException 如果task为null
*/
public <T> Future<T> submit(Callable<T> task) {
// 检查任务是否为null,如果是则抛出NullPointerException
if (task == null) throw new NullPointerException();
// 将Callable任务包装成RunnableFuture对象
// newTaskFor方法会创建一个FutureTask实例来包装任务
// FutureTask实现了RunnableFuture接口,既可执行又可获取结果
// 对于Callable任务,FutureTask会执行call方法并保存返回结果
RunnableFuture<T> ftask = newTaskFor(task);
// 调用execute方法执行任务
// execute方法会按照线程池的策略将任务交给合适的Worker执行
execute(ftask);
// 返回Future对象,调用者可以通过它检查任务状态和获取结果
return ftask;
}1
2
3
4
5
6
7
8protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
// Runnable 封装成 FutureTask,【指定返回值】
return new FutureTask<T>(runnable, value);
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
// Callable 直接封装成 FutureTask
return new FutureTask<T>(callable);
}1
2public class FutureTask<V> implements RunnableFuture<V> {...}
public interface RunnableFuture<V> extends Runnable, Future<V> {}
-
execute():执行任务,但是没有返回值,没办法获取任务执行结果,出现异常会直接抛出任务执行时的异常。根据线程池中的线程数,选择添加任务时的处理方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60/**
* 在未来某个时间执行给定的任务。该任务可能在一个新的线程中执行,
* 或者在一个已存在的线程中执行。
*
* @param command 要执行的任务
* @throws RejectedExecutionException 如果任务无法被接受执行
* @throws NullPointerException 如果 command 为 null
*/
public void execute(Runnable command) {
// 检查传入的任务是否为 null,如果为 null 则抛出 NullPointerException 异常
// 这是方法的基本前置条件检查
if (command == null)
throw new NullPointerException();
// 获取当前线程池的控制状态值 ctl,这是一个 AtomicInteger 类型的变量
// ctl 中包含了线程池的运行状态(rs)和工作线程数量(wc)两个信息
// 高3位存储运行状态,低29位存储工作线程数量
int c = ctl.get();
// 第一层判断:检查当前工作线程数量是否小于核心线程数(corePoolSize)
// workerCountOf(c) 是一个辅助方法,用于从 ctl 中提取工作线程数量
// 如果当前工作线程数小于核心线程数,说明还可以创建新的核心线程来处理任务
if (workerCountOf(c) < corePoolSize) {
// 尝试添加一个新的工作线程(worker)来执行这个任务
// addWorker(command, true) 中的 true 表示这是一个核心线程
// 如果添加成功,方法直接返回,任务已交给新创建的线程处理
if (addWorker(command, true))
return;
// 如果添加失败(可能因为并发情况下其他线程已经改变了状态),重新获取 ctl 值
// 这是为了确保后续逻辑基于最新的状态进行判断
c = ctl.get();
}
// 第二层判断:如果当前工作线程数已达到核心线程数,或者添加核心线程失败
// 首先检查线程池是否处于运行状态(isRunning(c))
// 如果线程池正在运行,并且工作队列(workQueue)能够接收新任务(offer成功)
if (isRunning(c) && workQueue.offer(command)) {
// 由于可能在并发环境下执行,需要重新检查线程池状态
// 这是一个重要的二次检查机制,确保线程池状态没有发生变化
int recheck = ctl.get();
// 重新检查线程池是否仍然处于运行状态
// 如果线程池已经关闭,且成功从工作队列中移除刚才添加的任务
// 则执行拒绝策略,因为线程池已不能接受新任务
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果线程池仍在运行,但没有活动的工作线程(可能因为超时等原因都被回收了)
// 则创建一个非核心线程来处理队列中的任务
// 这里传入 null 表示不指定初始任务,让线程自己从队列中获取任务
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 第三层判断:如果线程池不是运行状态,或者工作队列已满无法添加任务
// 尝试创建非核心线程来处理这个任务
// addWorker(command, false) 中的 false 表示这是一个非核心线程
else if (!addWorker(command, false))
// 如果创建非核心线程也失败了(可能因为达到 maximumPoolSize 或线程池已关闭)
// 则执行拒绝策略来处理这个无法执行的任务
reject(command);
}
添加线程
-
prestartAllCoreThreads():提前预热,创建所有的核心线程
1
2
3
4public boolean prestartCoreThread() {
return workerCountOf(ctl.get()) < corePoolSize &&
addWorker(null, true);
} -
addWorker():添加线程到线程池,返回 true 表示创建 Worker 成功,且线程启动。首先判断线程池是否允许添加线程,允许就让线程数量 + 1,然后去创建 Worker 加入线程池
注意:SHUTDOWN 状态也能添加线程,但是要求新加的 Woker 没有 firstTask,而且当前 queue 不为空,所以创建一个线程来帮助线程池执行队列中的任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135/**
* 添加一个新的工作线程来执行任务
*
* @param firstTask 新线程需要首先执行的任务,如果没有则为null
* @param core 如果为true表示按照核心线程数限制创建线程,false表示按照最大线程数限制创建
* @return 如果成功添加工作线程返回true,否则返回false
*/
private boolean addWorker(Runnable firstTask, boolean core) {
// retry标签定义了一个外层循环,用于在特定条件下重新开始整个添加工作线程的过程
retry:
// 外层循环,初始化c为当前ctl值,每次循环都会重新检查条件
for (int c = ctl.get();;) {
// 检查线程池状态是否允许添加新的工作线程
// 首先检查是否至少处于SHUTDOWN状态(rs >= SHUTDOWN)
if (runStateAtLeast(c, SHUTDOWN)
// 如果处于SHUTDOWN状态或更严重状态,则进一步检查以下任一条件是否成立:
// 1. 至少处于STOP状态(线程池已完全停止)
// 2. firstTask不为null(试图添加新任务到已关闭的线程池)
// 3. 工作队列为空(没有等待执行的任务)
// 如果以上任一条件成立,则不允许添加工作线程
&& (runStateAtLeast(c, STOP)
|| firstTask != null
|| workQueue.isEmpty()))
// 不允许添加工作线程,直接返回false
return false;
// 内层无限循环,用于处理CAS操作失败的重试逻辑
for (;;) {
// 检查工作线程数量是否超过限制
// workerCountOf(c)提取当前工作线程数量
// core决定使用corePoolSize还是maximumPoolSize作为限制
// COUNT_MASK用于屏蔽高3位的状态信息,只保留线程数量
if (workerCountOf(c)
>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
// 超过限制,无法添加新的工作线程,返回false
return false;
// 尝试通过CAS操作原子性地增加工作线程计数
if (compareAndIncrementWorkerCount(c))
// CAS操作成功,工作线程计数已增加,跳出外层retry循环继续执行
break retry;
// CAS操作失败,重新读取ctl值
c = ctl.get();
// 检查线程池状态是否发生变化(是否至少处于SHUTDOWN状态)
if (runStateAtLeast(c, SHUTDOWN))
// 状态已变化到SHUTDOWN或更严重状态,重新开始外层循环
continue retry;
// 如果状态未变化,则是因为其他线程修改了工作线程计数导致CAS失败
// 继续内层循环重试CAS操作
}
}
// 执行到此处说明已经成功通过CAS增加了工作线程计数
// 接下来需要实际创建工作线程对象并启动它
// 定义工作线程启动状态标记
boolean workerStarted = false;
// 定义工作线程添加状态标记
boolean workerAdded = false;
// 声明工作线程对象变量
Worker w = null;
try {
// 创建新的Worker对象
w = new Worker(firstTask);
// 从Worker对象中获取实际的线程对象
final Thread t = w.thread;
// 确保线程对象成功创建
if (t != null) {
// 获取线程池的主锁
final ReentrantLock mainLock = this.mainLock;
// 获取主锁,确保对workers集合操作的线程安全
mainLock.lock();
try {
// 在持有锁的情况下再次检查线程池状态
int c = ctl.get();
// 检查是否允许添加工作线程:
// 1. 线程池正在运行(isRunning(c))
// 2. 或者线程池未达到STOP状态且firstTask为null(处理队列中剩余任务)
if (isRunning(c) ||
(runStateLessThan(c, STOP) && firstTask == null)) {
// 检查线程状态是否为NEW(未启动状态)
if (t.getState() != Thread.State.NEW)
// 如果线程不是NEW状态,抛出异常
throw new IllegalThreadStateException();
// 将新创建的工作线程添加到线程池的工作线程集合中
workers.add(w);
// 标记工作线程已成功添加到线程池
workerAdded = true;
// 获取当前工作线程集合的大小
int s = workers.size();
// 更新线程池的历史最大线程数记录
if (s > largestPoolSize)
largestPoolSize = s;
}
} finally {
// 释放主锁
mainLock.unlock();
}
// 如果工作线程成功添加到线程池
if (workerAdded) {
// 启动工作线程
t.start();
// 标记工作线程已成功启动
workerStarted = true;
}
}
} finally {
// 如果工作线程启动失败
if (! workerStarted)
// 执行添加工作线程失败的清理操作
addWorkerFailed(w);
}
// 返回工作线程是否成功启动
return workerStarted;
} -
addWorkerFailed():清理任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35/**
* 处理添加工作线程失败的清理操作
* 当addWorker方法中创建的工作线程启动失败时,需要调用此方法进行清理
*
* @param w 启动失败的Worker对象,可能为null
*/
private void addWorkerFailed(Worker w) {
// 获取线程池的主锁,用于保护对workers集合的访问
final ReentrantLock mainLock = this.mainLock;
// 加锁以确保对共享资源操作的线程安全
mainLock.lock();
try {
// 检查Worker对象是否为null
if (w != null)
// 从workers集合中移除这个启动失败的Worker
// workers是一个HashSet,存储所有活跃的工作线程
workers.remove(w);
// 减少工作线程计数
// 因为在addWorker方法中已经通过CAS操作增加了计数,但线程启动失败
// 所以需要将计数减回去,保持计数的准确性
decrementWorkerCount();
// 尝试终止线程池
// 检查是否满足终止条件,如果满足则将线程池状态转换为TERMINATED
tryTerminate();
} finally {
// 无论操作是否成功,都要释放主锁
// 使用finally块确保锁一定会被释放,避免死锁
mainLock.unlock();
}
}
运行方法
-
Worker#run:Worker 实现了 Runnable 接口,当线程启动时,会调用 Worker 的 run() 方法
1
2
3
4public void run() {
// ThreadPoolExecutor#runWorker()
runWorker(this);
} -
runWorker():线程启动就要执行任务,会一直 while 循环获取任务并执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85/**
* 工作线程的实际执行方法,这是Worker线程的主循环
* 每个工作线程启动后都会执行这个方法,负责从队列中获取任务并执行
*
* @param w 执行此方法的Worker对象
*/
final void runWorker(Worker w) {
// 获取当前正在执行的线程对象
Thread wt = Thread.currentThread();
// 获取Worker的第一个任务(在创建Worker时传入的初始任务)
Runnable task = w.firstTask;
// 清空Worker的firstTask引用,因为这个任务即将被执行
// 这样可以尽早释放对任务对象的引用,便于垃圾回收
w.firstTask = null;
// 释放Worker的锁,允许接收中断信号
//在 Worker 构造函数中,通过 setState(-1) 将状态设置为 -1,这实际上是一种"锁定"状态,防止线程在启动前被中断。
//在 runWorker 方法开始时调用 w.unlock() 是为了释放这个初始的"锁定"状态,允许线程在后续运行过程中可以被中断。
//这种设计保证了线程在准备好执行任务之前不会被中断,提高了线程池的稳定性。
w.unlock();
// 标记工作线程是否因为异常而突然终止
// true表示异常终止,false表示正常退出
boolean completedAbruptly = true;
try {
// 主循环:不断获取并执行任务
// 循环条件:task不为null(有初始任务)或者能从队列中获取到新任务
while (task != null || (task = getTask()) != null) {
// 获取Worker锁,表示开始执行任务
// 这个锁机制用于控制Worker的状态和中断处理
w.lock();
// 检查是否需要中断当前线程
// 条件1:线程池至少处于STOP状态(正在停止)
// 条件2:线程已被中断且线程池至少处于STOP状态
// 如果满足上述条件且当前线程未被中断,则中断当前线程
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 任务执行前的回调方法,可以被子类重写用于扩展
beforeExecute(wt, task);
try {
// 实际执行任务的run方法
// 注意:这里是直接调用run()而不是start(),因为不需要新线程
task.run();
// 任务执行后的回调方法(正常执行完毕),可以被子类重写用于扩展
afterExecute(task, null);
} catch (Throwable ex) {
// 任务执行后的回调方法(执行异常),可以被子类重写用于扩展
afterExecute(task, ex);
// 重新抛出异常
throw ex;
}
} finally {
// 任务执行完成后的清理工作
// 清空task引用,便于垃圾回收
task = null;
// 增加Worker完成的任务计数
w.completedTasks++;
// 释放Worker锁,表示任务执行完成
w.unlock();
}
}
// 执行到这里说明Worker正常退出(没有异常)
// 将completedAbruptly设置为false
completedAbruptly = false;
} finally {
// 无论正常退出还是异常终止,都要执行清理操作
// completedAbruptly为true表示异常终止,false表示正常退出
processWorkerExit(w, completedAbruptly);
}
} -
unlock():重置锁
1
2
3
4
5
6
7public void unlock() { release(1); }
// 外部不会直接调用这个方法 这个方法是 AQS 内调用的,外部调用 unlock 时触发此方法
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null); // 设置持有者为 null
setState(0); // 设置 state = 0
return true;
} -
getTask():获取任务,线程空闲时间超过 keepAliveTime 就会被回收,判断的依据是当前线程阻塞获取任务超过保活时间,方法返回 null 就代表当前线程要被回收了,返回到 runWorker 执行线程退出逻辑。线程池具有担保机制,对于 RUNNING 状态下的超时回收,要保证线程池中最少有一个线程运行,或者任务阻塞队列已经是空
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73/**
* 从工作队列中获取下一个要执行的任务
* 这个方法可能会阻塞等待任务,也可能会根据超时设置返回null
*
* @return 下一个要执行的任务,如果没有任务或线程应该终止则返回null
*/
private Runnable getTask() {
// 标记上一次从队列获取任务是否超时
// 初始值为false
boolean timedOut = false;
// 无限循环,用于处理各种重试和条件检查
for (;;) {
// 获取当前线程池的控制状态
int c = ctl.get();
// 检查线程池状态是否允许继续获取任务
// 如果线程池至少处于SHUTDOWN状态,并且满足以下任一条件:
// 1. 线程池至少处于STOP状态(完全停止)
// 2. 工作队列为空
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP) || workQueue.isEmpty())) {
// 减少工作线程计数,因为当前线程将要退出
decrementWorkerCount();
// 返回null表示没有任务可获取,Worker应该终止
return null;
}
// 获取当前工作线程数量
int wc = workerCountOf(c);
// 判断当前工作线程是否应该被超时控制
// 条件1:allowCoreThreadTimeOut为true(允许核心线程超时)
// 条件2:当前工作线程数大于corePoolSize(非核心线程)
// 如果满足任一条件,则timed为true,表示需要超时控制
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 检查是否应该减少工作线程:
// 条件1:工作线程数超过maximumPoolSize(很少发生)
// 或者:启用了超时控制且上次获取任务超时
// 并且:工作线程数大于1或者工作队列为空
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
// 尝试通过CAS操作减少工作线程计数
if (compareAndDecrementWorkerCount(c))
// 成功减少计数,返回null表示当前Worker应该终止
return null;
// CAS失败,继续下一轮循环重试
continue;
}
try {
// 根据是否启用超时控制选择不同的队列获取方式
Runnable r = timed ?
// 如果启用超时控制,使用poll方法在指定时间内等待任务
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
// 如果不启用超时控制,使用take方法无限期等待任务
workQueue.take();
// 检查是否成功获取到任务
if (r != null)
// 获取到任务,返回该任务
return r;
// 没有获取到任务(超时),设置超时标记为true
timedOut = true;
} catch (InterruptedException retry) {
// 如果在等待任务过程中被中断,清除超时标记
// 继续下一轮循环重试获取任务
timedOut = false;
}
}
} -
processWorkerExit():线程退出线程池,也有担保机制,保证队列中的任务被执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73/**
* 处理Worker线程退出的清理工作
* 这是Worker生命周期的最后阶段,负责资源清理和线程池状态维护
*
* @param w 退出的Worker对象
* @param completedAbruptly true表示Worker异常终止,false表示正常完成
*/
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// 检查Worker是否异常终止
// completedAbruptly为true表示Worker是因为异常而突然终止(如抛出异常)
// 在这种情况下,工作线程计数还没有被正确减少,需要手动减少
if (completedAbruptly)
// 异常终止时减少工作线程计数
// 正常终止的情况在getTask方法中已经处理了计数减少
decrementWorkerCount();
// 获取线程池的主锁,用于保护共享资源的访问
final ReentrantLock mainLock = this.mainLock;
// 加锁以确保对workers集合和completedTaskCount的线程安全访问
mainLock.lock();
try {
// 累加该Worker完成的任务数到线程池的总计数中
// w.completedTasks记录了这个Worker一生中完成的所有任务数量
completedTaskCount += w.completedTasks;
// 从活跃Worker集合中移除该Worker
// workers是一个HashSet,存储所有当前活跃的Worker
workers.remove(w);
} finally {
// 释放主锁,确保锁一定会被释放
mainLock.unlock();
}
// 尝试终止线程池
// 检查是否满足终止条件,如果满足则将线程池状态转换为TERMINATED
// 这个方法会检查是否所有Worker都已退出且任务队列为空
tryTerminate();
// 获取当前线程池控制状态
int c = ctl.get();
// 检查线程池是否未达到STOP状态(即RUNNING或SHUTDOWN状态)
// 只有在线程池还在运行或优雅关闭阶段才需要考虑补充Worker
if (runStateLessThan(c, STOP)) {
// 检查Worker是否正常完成(而非异常终止)
if (!completedAbruptly) {
// 计算线程池应该维持的最小线程数
// 如果允许核心线程超时,则最小线程数可以为0
// 否则最小线程数为核心线程数
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// 特殊情况处理:
// 如果最小线程数为0(允许核心线程超时)但工作队列不为空
// 则至少需要保持1个线程来处理队列中的任务
if (min == 0 && ! workQueue.isEmpty())
min = 1;
// 检查当前工作线程数是否已经满足最小要求
// 如果满足要求,则不需要补充新的Worker
if (workerCountOf(c) >= min)
return; // 不需要补充Worker,直接返回
}
// 补充一个新的Worker
// 两种情况下会执行到这里:
// 1. Worker异常终止,需要补充Worker
// 2. Worker正常终止但当前线程数低于要求的最小值,需要补充Worker
// 传入null表示新Worker没有初始任务,false表示按照非核心线程规则创建
addWorker(null, false);
}
}
停止方法
-
shutdown():停止线程池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45/**
* 启动线程池的有序关闭过程
* 在执行此方法后,线程池不再接受新任务,但会继续执行已提交的任务
* 此方法不会等待已提交的任务执行完毕(如果需要等待,可以使用awaitTermination)
*/
public void shutdown() {
// 获取线程池的主锁,用于保护线程池状态和Worker集合的访问
// 这确保了shutdown操作的原子性和线程安全性
final ReentrantLock mainLock = this.mainLock;
// 加锁以确保对线程池状态修改的独占访问
mainLock.lock();
try {
// 检查关闭线程池的权限
// 这个方法会检查当前线程是否有权限修改线程池状态
// 如果安全管理器存在,会进行相应的安全检查
checkShutdownAccess();
// 将线程池的运行状态推进到SHUTDOWN状态
// advanceRunState方法会确保状态只能向前推进(RUNNING -> SHUTDOWN -> ...)
// 这是一个原子操作,确保状态转换的安全性
advanceRunState(SHUTDOWN);
// 中断所有空闲的Worker线程
// 空闲的Worker是指正在等待任务的线程(在getTask方法中阻塞)
// 这些线程被中断后会退出等待状态并检查线程池状态,然后正常退出
interruptIdleWorkers();
// 钩子方法,供子类扩展shutdown行为
// ThreadPoolExecutor的子类ScheduledThreadPoolExecutor会重写此方法
// 用于处理定时任务等特殊逻辑
onShutdown();
} finally {
// 无论操作是否成功,都要释放主锁
// 使用finally块确保锁一定会被释放,避免死锁风险
mainLock.unlock();
}
// 尝试终止线程池
// 检查是否满足终止条件(所有Worker都已退出且任务队列为空)
// 如果满足条件则将线程池状态转换为TERMINATED
// 如果不满足条件,会在其他地方(如Worker退出时)再次尝试终止
tryTerminate();
} -
interruptIdleWorkers():shutdown 方法会中断所有空闲线程,根据是否可以获取 AQS 独占锁判断是否处于工作状态。线程之所以空闲是因为阻塞队列没有任务,不会中断正在运行的线程,所以 shutdown 方法会让所有的任务执行完毕
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53/**
* 中断空闲的Worker线程
* 这个方法用于中断那些正在等待任务的Worker线程,使它们能够及时响应线程池状态变化
*
* @param onlyOne 是否只中断一个Worker线程,true表示只中断一个,false表示中断所有空闲Worker
*/
private void interruptIdleWorkers(boolean onlyOne) {
// 获取线程池的主锁,用于保护对workers集合的访问
// 确保在遍历workers集合时不会有其他线程修改它
final ReentrantLock mainLock = this.mainLock;
// 加锁以确保对Worker集合操作的线程安全
mainLock.lock();
try {
// 遍历所有活跃的Worker线程
// workers是一个HashSet,包含所有当前活跃的Worker对象
for (Worker w : workers) {
// 获取Worker封装的线程对象
Thread t = w.thread;
// 检查是否应该中断这个Worker线程:
// 条件1:线程当前未被中断(!t.isInterrupted())
// 条件2:能够成功获取Worker的锁(w.tryLock())
// Worker继承自AQS,在执行任务时会持有锁,空闲时会释放锁
// 因此tryLock成功意味着Worker当前空闲(正在等待任务)
if (!t.isInterrupted() && w.tryLock()) {
try {
// 中断该线程
// 被中断的线程会在getTask方法中检测到中断状态并相应处理
// 通常是退出等待状态并检查线程池状态,然后正常退出
t.interrupt();
} catch (SecurityException ignore) {
// 捕获安全异常,如果安全管理器不允许中断该线程
// 在这种情况下忽略异常,继续处理其他Worker
} finally {
// 无论中断是否成功,都要释放Worker的锁
// 这确保了Worker对象的锁状态一致性
w.unlock();
}
}
// 如果onlyOne为true,表示只中断一个Worker就足够了
// 这在某些特定场景下使用,比如只希望唤醒一个Worker来处理特殊任务
if (onlyOne)
break; // 跳出循环,结束方法执行
}
} finally {
// 无论操作是否成功,都要释放主锁
// 使用finally块确保锁一定会被释放,避免死锁风险
mainLock.unlock();
}
} -
shutdownNow():直接关闭线程池,不会等待任务执行完成
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50/**
* 立即关闭线程池
* 此方法会尝试停止所有正在执行的任务,中断所有Worker线程,
* 并返回等待执行的任务列表
*
* @return 等待执行的任务列表(队列中尚未执行的任务)
*/
public List<Runnable> shutdownNow() {
// 声明一个列表用于存储被取消的任务
List<Runnable> tasks;
// 获取线程池的主锁,用于保护线程池状态和Worker集合的访问
final ReentrantLock mainLock = this.mainLock;
// 加锁以确保对线程池状态修改的独占访问
mainLock.lock();
try {
// 检查关闭线程池的权限
// 验证当前线程是否有权限修改线程池状态
// 如果安全管理器存在,会进行相应的安全检查
checkShutdownAccess();
// 将线程池的运行状态推进到STOP状态
// STOP状态比SHUTDOWN更严重,表示线程池应该立即停止所有活动
// advanceRunState方法确保状态只能向前推进
advanceRunState(STOP);
// 中断所有Worker线程(包括正在执行任务的线程)
// 这与shutdown()方法中的interruptIdleWorkers()不同
// interruptWorkers会中断所有线程,而不仅仅是空闲线程
interruptWorkers();
// 清空工作队列,将所有等待执行的任务转移到tasks列表中
// drainQueue方法会将队列中的所有任务移除并返回
tasks = drainQueue();
} finally {
// 无论操作是否成功,都要释放主锁
// 使用finally块确保锁一定会被释放,避免死锁风险
mainLock.unlock();
}
// 尝试终止线程池
// 检查是否满足终止条件,如果满足则将线程池状态转换为TERMINATED
tryTerminate();
// 返回等待执行的任务列表
// 这些任务由于线程池的强制关闭而没有机会被执行
return tasks;
}1
2
3
4
5private void interruptWorkers() {
// assert mainLock.isHeldByCurrentThread();
for (Worker w : workers)
w.interruptIfStarted();
}1
2
3
4
5
6
7
8
9
10
11
12private List<Runnable> drainQueue() {
BlockingQueue<Runnable> q = workQueue;
ArrayList<Runnable> taskList = new ArrayList<>();
q.drainTo(taskList);
if (!q.isEmpty()) {
for (Runnable r : q.toArray(new Runnable[0])) {
if (q.remove(r))
taskList.add(r);
}
}
return taskList;
} -
tryTerminate():设置为 TERMINATED 状态 if either (SHUTDOWN and pool and queue empty) or (STOP and pool empty)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68/**
* 尝试终止线程池
* 这个方法检查线程池是否满足终止条件,如果满足则执行终止过程
* 该方法在多个地方被调用,以确保线程池能够正确终止
*/
final void tryTerminate() {
// 无限循环,用于处理CAS操作失败的重试
for (;;) {
// 获取当前线程池的控制状态
int c = ctl.get();
// 检查是否不满足终止条件,如果满足则直接返回
// 以下任一情况都不应该终止线程池:
if (isRunning(c) || // 1. 线程池正在运行状态
runStateAtLeast(c, TIDYING) || // 2. 线程池已经处于TIDYING或TERMINATED状态
(runStateLessThan(c, STOP) && ! workQueue.isEmpty())) // 3. 线程池未达到STOP状态且工作队列不为空
// 不满足终止条件,直接返回
return;
// 检查工作线程数量是否不为0
if (workerCountOf(c) != 0) { // 有Worker仍在运行,具备终止资格
// 中断一个空闲Worker以加速终止过程
// 这会唤醒一个等待任务的Worker,使其检查线程池状态并退出
interruptIdleWorkers(ONLY_ONE);
// 返回而不进行终止操作,等待Worker退出后再尝试
return;
}
// 执行到这里说明满足终止条件:
// 1. 线程池已关闭(SHUTDOWN或STOP状态)
// 2. 没有活跃的Worker线程
// 3. 工作队列为空(如果是SHUTDOWN状态)
// 获取线程池的主锁,用于保护终止过程
final ReentrantLock mainLock = this.mainLock;
// 加锁以确保终止过程的原子性
mainLock.lock();
try {
// 使用CAS操作将线程池状态从当前状态转换为TIDYING状态
// TIDYING状态表示线程池正在执行清理工作
// 同时将工作线程计数设置为0
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
// 执行终止前的清理工作
// 这是一个钩子方法,可以被子类重写以执行特定的清理操作
terminated();
} finally {
// 无论terminated()是否成功,都要将状态设置为TERMINATED
// TERMINATED状态表示线程池已完全终止
ctl.set(ctlOf(TERMINATED, 0));
// 唤醒所有等待线程池终止的线程
// 这些线程可能在调用awaitTermination()方法等待
termination.signalAll();
}
// 终止过程完成,返回
return;
}
} finally {
// 无论操作是否成功,都要释放主锁
mainLock.unlock();
}
// 如果CAS操作失败(说明有其他线程同时修改了ctl),继续循环重试
// else retry on failed CAS
}
}
7.1.6 FutureTask
FutureTask 的作用
- 异步计算:FutureTask 代表一个异步计算任务。它可以在一个线程中执行计算,而另一个线程可以通过 Future 接口的方法来获取计算结果。
- 可取消的任务:FutureTask 允许取消正在执行的任务,也可以判断任务是否完成或取消。
- 获取计算结果:通过 Future 接口的 get() 方法获取计算结果。如果计算尚未完成,get() 方法会阻塞直到计算完成或超时。
- 任务状态管理:FutureTask 提供了任务状态的管理,比如判断任务是否完成、是否取消等。
适合需要灵活控制任务执行或复用计算结果的场景
类定义与状态常量
1 | /** |
1 | public interface RunnableFuture<V> extends Runnable, Future<V> { |
核心字段与构造方法
1 | /** 实际要执行的任务,执行完成后会被置为null以帮助GC (可以是 Callable 或通过适配器转换的 Runnable)*/ |
1 | /** |
核心方法实现
-
run()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51public void run() {
// 1. 初始状态检查:确保任务处于NEW状态(未开始),并且通过CAS操作将runner字段从null设置为当前线程
// 状态检查:只有NEW状态的任务才能执行
// CAS操作:确保只有一个线程能成功设置runner字段,防止并发执行
if (state != NEW ||
!RUNNER.compareAndSet(this, null, Thread.currentThread()))
return; // 如果状态不是NEW或者设置runner失败,直接返回(说明任务已被其他线程执行)
try {
// 2. 获取要执行的任务对象
Callable<V> c = callable;
// 3. 双重检查:确保任务不为null且状态仍为NEW(防止在检查期间状态被改变)
if (c != null && state == NEW) {
V result; // 存储任务执行结果
boolean ran; // 标记任务是否正常执行完成
try {
// 4. 执行实际的任务逻辑
result = c.call();
ran = true; // 标记为成功执行
} catch (Throwable ex) {
// 5. 任务执行过程中发生异常
result = null;
ran = false; // 标记为执行失败
setException(ex); // 将异常结果设置到Future中
}
// 6. 如果任务正常执行完成,设置执行结果
if (ran)
set(result); // 将正常结果设置到Future中
}
} finally {
// 7. 清理阶段:无论任务执行成功还是失败,都需要执行的清理操作
// 将runner设置为null,表示当前线程已不再执行此任务
// 这可以防止并发调用run()方法,因为其他线程看到runner为null时可能会尝试执行
runner = null;
// 8. 在设置runner为null后重新读取state状态
// 这是因为在设置runner=null和读取state之间,状态可能被其他线程修改
// 这种重读可以防止"中断泄露"(防止错过中断状态)
int s = state;
// 9. 处理可能的中断取消情况
// 如果状态是INTERRUPTING(正在中断)或INTERRUPTED(已中断)
// 需要处理可能的中断逻辑
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
-
get()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44/**
* 等待计算完成,然后获取结果。
*
* @return 计算结果
* @throws InterruptedException 如果当前线程在等待过程中被中断
* @throws ExecutionException 如果计算过程中抛出异常
*/
public V get() throws InterruptedException, ExecutionException {
// 获取当前任务状态
int s = state;
// 如果任务尚未完成(包括未开始和正在执行)
if (s <= COMPLETING)
// 阻塞等待任务完成,返回最终状态
s = awaitDone(false, 0L);
// 根据最终状态返回结果或抛出异常
return report(s);
}
/**
* 在指定时间内等待计算完成,然后获取结果。
*
* @param timeout 等待的最大时间
* @param unit 时间单位
* @return 计算结果
* @throws InterruptedException 如果当前线程在等待过程中被中断
* @throws ExecutionException 如果计算过程中抛出异常
* @throws TimeoutException 如果等待超时
* @throws CancellationException 如果计算被取消
*/
public V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException {
// 检查时间单位参数是否为空
if (unit == null)
throw new NullPointerException();
// 获取当前任务状态
int s = state;
// 如果任务尚未完成,并且在指定时间内仍未完成
if (s <= COMPLETING &&
(s = awaitDone(true, unit.toNanos(timeout))) <= COMPLETING)
// 抛出超时异常
throw new TimeoutException();
// 根据最终状态返回结果或抛出异常
return report(s);
}
等待机制实现
-
awaitDone()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92/**
* 等待任务完成的核心方法
*
* @param timed 是否启用超时机制
* @param nanos 超时时间(纳秒)
* @return 任务的最终状态
* @throws InterruptedException 如果线程在等待过程中被中断
*/
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
// 下面的代码非常精细,旨在实现以下目标:
// - 每次调用 park 时只调用一次 nanoTime
// - 如果 nanos <= 0L,不进行分配或调用 nanoTime 直接返回
// - 如果 nanos == Long.MIN_VALUE,避免下溢出
// - 如果 nanos == Long.MAX_VALUE,且 nanoTime 非单调递增,
// 当我们遇到虚假唤醒时,最坏情况也只是 park-spin 一段时间
long startTime = 0L; // 特殊值 0L 表示尚未 park
WaitNode q = null; // 等待节点
boolean queued = false; // 是否已入队
// 无限循环等待任务完成
for (;;) {
// 检查当前任务状态
int s = state;
// 如果任务已完成(状态大于 COMPLETING)
if (s > COMPLETING) {
// 清理等待节点中的线程引用
if (q != null)
q.thread = null;
// 返回最终状态
return s;
}
// 如果任务正在完成过程中(COMPLETING 状态)
else if (s == COMPLETING)
// 我们可能已经通过 isDone 承诺任务已完成
// 所以永远不要空手而归或抛出 InterruptedException
Thread.yield(); // 让出 CPU 时间片
// 如果当前线程被中断
else if (Thread.interrupted()) {
// 移除等待节点
removeWaiter(q);
// 抛出中断异常
throw new InterruptedException();
}
// 如果等待节点尚未创建
else if (q == null) {
// 如果启用了超时且超时时间已到或已过期
if (timed && nanos <= 0L)
return s; // 直接返回当前状态
// 创建新的等待节点
q = new WaitNode();
}
// 如果节点未入队
else if (!queued)
// 使用 CAS 操作将节点加入等待队列
queued = WAITERS.weakCompareAndSet(this, q.next = waiters, q);
// 如果启用了超时机制
else if (timed) {
final long parkNanos; // 计算需要 park 的纳秒数
// 如果是第一次 park
if (startTime == 0L) {
startTime = System.nanoTime(); // 记录开始时间
if (startTime == 0L)
startTime = 1L; // 避免 startTime 为 0
parkNanos = nanos; // 初始 park 时间为指定的超时时间
} else {
// 计算已用时间
long elapsed = System.nanoTime() - startTime;
// 如果已超时
if (elapsed >= nanos) {
removeWaiter(q); // 移除等待节点
return state; // 返回当前状态
}
// 计算剩余需要 park 的时间
parkNanos = nanos - elapsed;
}
// nanoTime 可能较慢,在 park 前重新检查状态
if (state < COMPLETING)
// 按指定时间 park 当前线程
LockSupport.parkNanos(this, parkNanos);
}
// 如果没有启用超时机制
else
// 无限期 park 当前线程,直到被唤醒
LockSupport.park(this);
}
} -
WaitNode 内部类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32/**
* 等待节点类,用于构建等待队列
* 当多个线程等待Future任务完成时,它们会被组织成一个等待链表
* 这个类是FutureTask内部类的典型实现,用于管理等待任务结果的线程
*/
static final class WaitNode {
/**
* 等待线程引用
* volatile修饰确保多线程环境下的可见性:
* - 当任务完成时,可以正确通知到所有等待线程
* - 防止指令重排序带来的线程可见性问题
*/
volatile Thread thread;
/**
* 指向下一个等待节点的引用
* volatile修饰确保链表操作的可见性:
* - 新节点添加到链表时,其他线程能立即看到更新
* - 节点被移除时,能正确传递信号
*/
volatile WaitNode next;
/**
* 构造函数
* 创建等待节点时,自动将当前线程引用赋给thread字段
* 这样每个WaitNode都与一个特定的等待线程关联
*/
WaitNode() {
thread = Thread.currentThread();
}
}
取消与完成处理
-
cancel()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43/**
* 尝试取消任务的执行
*
* @param mayInterruptIfRunning 如果为true,表示如果任务正在运行,可以中断执行线程;
* 如果为false,表示不中断运行中的任务,只取消未开始的任务
* @return 如果任务无法取消(通常是因为已经完成或已被取消),返回false;否则返回true
*/
public boolean cancel(boolean mayInterruptIfRunning) {
// 1. 尝试将任务状态从NEW转换为取消状态
// 条件1: state == NEW - 只有NEW状态的任务才能被取消
// 条件2: CAS操作 - 原子性地将状态从NEW改为目标状态
// - 如果mayInterruptIfRunning为true,状态改为INTERRUPTING(正在中断)
// - 如果mayInterruptIfRunning为false,状态改为CANCELLED(已取消)
if (!(state == NEW &&
STATE.compareAndSet(this, NEW,
mayInterruptIfRunning ? INTERRUPTING : CANCELLED))) {
// 2. 如果取消失败(任务不是NEW状态或CAS竞争失败),直接返回false
return false;
}
try { // 异常处理:防止interrupt调用抛出异常影响后续逻辑
// 3. 如果允许中断运行中的任务
if (mayInterruptIfRunning) {
try {
// 4. 获取当前执行任务的线程
Thread t = runner;
if (t != null) {
// 5. 中断执行线程(发送中断信号)
t.interrupt();
}
} finally {
// 6. 无论中断是否成功,最终将状态设置为INTERRUPTED(已中断)
// 使用setRelease保证内存可见性:确保之前的写操作对其他线程可见
STATE.setRelease(this, INTERRUPTED);
}
}
// 7. 如果mayInterruptIfRunning为false,状态已经是CANCELLED,无需额外操作
} finally {
// 8. 无论取消是否涉及中断,都需要完成后续清理工作
finishCompletion();
}
return true;
} -
finishCompletion() 方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50/**
* 完成任务的后续清理工作
* 在任务正常完成、异常完成或被取消时调用
* 主要职责:唤醒所有等待线程,执行完成回调,清理资源
*
* 调用前提:state > COMPLETING(任务已进入最终状态)
*/
private void finishCompletion() {
// 断言检查:确保任务已进入最终状态(NORMAL, EXCEPTIONAL, CANCELLED, INTERRUPTED等)
// assert state > COMPLETING;
// 1. 处理等待队列:遍历并唤醒所有等待任务结果的线程
// 使用循环CAS操作来原子性地获取并清空等待队列
for (WaitNode q; (q = waiters) != null;) {
// 使用weakCompareAndSet(可选的CAS操作)尝试清空等待队列
// 如果CAS失败,说明其他线程正在修改等待队列,循环重试
if (WAITERS.weakCompareAndSet(this, q, null)) {
// 2. 成功获取到等待队列,开始遍历唤醒所有等待线程
for (;;) {
// 获取当前节点关联的等待线程
Thread t = q.thread;
if (t != null) {
// 清空线程引用,帮助GC回收
q.thread = null;
// 唤醒等待的线程(使调用get()方法的线程继续执行)
LockSupport.unpark(t);
}
// 移动到下一个等待节点
WaitNode next = q.next;
if (next == null)
break; // 到达链表末尾,退出循环
// 断开当前节点的next引用,帮助GC回收
q.next = null; // unlink to help gc
// 继续处理下一个节点
q = next;
}
// 处理完成,退出外层循环
break;
}
// 如果CAS失败,循环继续尝试
}
// 3. 调用完成回调方法(模板方法模式)
done();
// 4. 清理任务引用,减少内存占用
callable = null; // to reduce footprint
}
状态转换辅助方法
-
set()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27/**
* 设置任务的正常执行结果
* 将任务状态从NEW转换为COMPLETING,然后设置结果,最后转换为NORMAL状态
*
* @param v 任务执行的结果对象
*/
protected void set(V v) {
// 1. 尝试将任务状态从NEW原子性地转换为COMPLETING(完成中)
// COMPLETING是一个短暂的中间状态,表示正在设置结果
if (STATE.compareAndSet(this, NEW, COMPLETING)) {
// 2. CAS成功,当前线程获得了设置结果的权限
// 将结果值赋给outcome字段(存储任务结果或异常)
outcome = v;
// 3. 将状态从COMPLETING转换为NORMAL(正常完成)
// 使用setRelease保证内存可见性:确保outcome的写入在状态变更前对其他线程可见
STATE.setRelease(this, NORMAL); // final state(最终状态)
// 4. 执行完成后的清理工作:唤醒所有等待线程,执行回调,清理资源
finishCompletion();
}
// 5. 如果CAS失败,说明:
// - 任务已经被其他线程设置过结果
// - 任务已被取消
// - 任务执行出现异常并被设置
// 在这种情况下,当前设置操作被忽略(保证结果只被设置一次)
} -
setException()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28/**
* 设置任务的异常执行结果
* 当任务执行过程中抛出异常时调用此方法
* 将任务状态从NEW转换为COMPLETING,然后设置异常,最后转换为EXCEPTIONAL状态
*
* @param t 任务执行过程中抛出的异常对象
*/
protected void setException(Throwable t) {
// 1. 尝试将任务状态从NEW原子性地转换为COMPLETING(完成中)
// COMPLETING是一个短暂的中间状态,表示正在设置结果/异常
if (STATE.compareAndSet(this, NEW, COMPLETING)) {
// 2. CAS成功,当前线程获得了设置异常的权限
// 将异常对象赋给outcome字段(存储任务结果或异常)
outcome = t;
// 3. 将状态从COMPLETING转换为EXCEPTIONAL(异常完成)
// 使用setRelease保证内存可见性:确保outcome的写入在状态变更前对其他线程可见
STATE.setRelease(this, EXCEPTIONAL); // final state(最终状态)
// 4. 执行完成后的清理工作:唤醒所有等待线程,执行回调,清理资源
finishCompletion();
}
// 5. 如果CAS失败,说明:
// - 任务已经被其他线程设置过结果或异常
// - 任务已被取消
// - 其他线程已经处理了任务完成逻辑
// 在这种情况下,当前异常设置操作被忽略(保证结果只被设置一次)
} -
handlePossibleCancellationInterrupt()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31/**
* 处理可能的取消中断情况
* 当任务处于INTERRUPTING或INTERRUPTED状态时调用此方法
*
* @param s 当前的任务状态(应该是INTERRUPTING或INTERRUPTED)
*/
private void handlePossibleCancellationInterrupt(int s) {
// 1. 处理中断挂起情况:如果状态是INTERRUPTING(正在中断中)
// 注释说明:中断线程可能在中断我们之前发生延迟,需要自旋等待
if (s == INTERRUPTING) {
// 自旋等待直到中断操作完成(状态从INTERRUPTING变为INTERRUPTED)
while (state == INTERRUPTING)
Thread.yield(); // 等待挂起的中断完成,让出CPU时间片
}
// 2. 此时状态应该是INTERRUPTED(断言检查,实际代码中已注释)
// assert state == INTERRUPTED;
// 3. 关于中断标志处理的说明(实际代码中已注释,未执行清除操作):
//
// 我们原本想要清除可能从cancel(true)接收到的中断标志。
// 但是,允许将中断作为任务与其调用者通信的独立机制,
// 并且没有办法只清除取消相关的中断标志。
//
// 因此决定不调用Thread.interrupted()来清除中断状态:
// - 中断可能被任务本身用作其他通信机制
// - 无法区分"取消中断"和"业务中断"
// - 清除中断标志可能会影响调用者的正常逻辑
// Thread.interrupted(); // 这行代码被注释掉了,说明设计上的考虑
}
7.1.7 任务调度
Timer
Timer 实现定时功能,Timer 的优点在于简单易用,但由于所有任务都是由同一个线程来调度,因此所有任务都是串行执行的,同一时间只能有一个任务在执行,前一个任务的延迟或异常都将会影响到之后的任务
1 | private static void method1() { |
Scheduled
任务调度线程池 ScheduledThreadPoolExecutor 继承 ThreadPoolExecutor:
- 使用内部类 ScheduledFutureTask 封装任务
- 使用内部类 DelayedWorkQueue 作为线程池队列
- 重写 onShutdown 方法去处理 shutdown 后的任务
- 提供 decorateTask 方法作为 ScheduledFutureTask 的修饰方法,以便开发者进行扩展
构造方法:Executors.newScheduledThreadPool(int corePoolSize)
1 | public ScheduledThreadPoolExecutor(int corePoolSize) { |
常用 API:
ScheduledFuture<?> schedule(Runnable/Callable<V>, long delay, TimeUnit u):延迟执行任务ScheduledFuture<?> scheduleAtFixedRate(Runnable/Callable<V>, long initialDelay, long period, TimeUnit unit):定时执行周期任务,不考虑执行的耗时,参数为初始延迟时间、间隔时间、单位ScheduledFuture<?> scheduleWithFixedDelay(Runnable/Callable<V>, long initialDelay, long delay, TimeUnit unit):定时执行周期任务,考虑执行的耗时,参数为初始延迟时间、间隔时间、单位
基本使用:
-
延迟任务,但是出现异常并不会在控制台打印,也不会影响其他线程的执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public static void main(String[] args) {
// 线程池大小为1时也是串行执行
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
// 添加两个任务,都在 1s 后同时执行
executor.schedule(() -> {
System.out.println("任务1,执行时间:" + System.currentTimeMillis());
int i = 1 / 0;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
}, 1000, TimeUnit.MILLISECONDS);
executor.schedule(() -> {
System.out.println("任务2,执行时间:" + System.currentTimeMillis());
}, 1000, TimeUnit.MILLISECONDS);
} -
定时任务 scheduleAtFixedRate:一次任务的启动到下一次任务的启动之间只要大于等于间隔时间,抢占到 CPU 就会立即执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14public static void main(String[] args) {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
System.out.println("start..." + new Date());
pool.scheduleAtFixedRate(() -> {
System.out.println("running..." + new Date());
Thread.sleep(2000);
}, 1, 1, TimeUnit.SECONDS);
}
/*start...Sat Apr 24 18:08:12 CST 2021
running...Sat Apr 24 18:08:13 CST 2021
running...Sat Apr 24 18:08:15 CST 2021
running...Sat Apr 24 18:08:17 CST 2021 -
定时任务 scheduleWithFixedDelay:一次任务的结束到下一次任务的启动之间等于间隔时间,抢占到 CPU 就会立即执行,这个方法才是真正的设置两个任务之间的间隔
1
2
3
4
5
6
7
8
9
10
11
12
13public static void main(String[] args){
ScheduledExecutorService pool = Executors.newScheduledThreadPool(3);
System.out.println("start..." + new Date());
pool.scheduleWithFixedDelay(() -> {
System.out.println("running..." + new Date());
Thread.sleep(2000);
}, 1, 1, TimeUnit.SECONDS);
}
/*start...Sat Apr 24 18:11:41 CST 2021
running...Sat Apr 24 18:11:42 CST 2021
running...Sat Apr 24 18:11:45 CST 2021
running...Sat Apr 24 18:11:48 CST 2021
成员属性
成员变量
-
shutdown 后是否继续执行周期任务:
1
private volatile boolean continueExistingPeriodicTasksAfterShutdown;
-
shutdown 后是否继续执行延迟任务:
1
private volatile boolean executeExistingDelayedTasksAfterShutdown = true;
-
取消方法是否将该任务从队列中移除:
1
2// 默认 false,不移除,等到线程拿到任务之后抛弃
private volatile boolean removeOnCancel = false; -
任务的序列号,可以用来比较优先级:
1
private static final AtomicLong sequencer = new AtomicLong();
延迟任务
ScheduledFutureTask 继承 FutureTask,实现 RunnableScheduledFuture 接口,具有延迟执行的特点,覆盖 FutureTask 的 run 方法来实现对延时执行、周期执行的支持。对于延时任务调用 FutureTask#run,而对于周期性任务则调用 FutureTask#runAndReset 并且在成功之后根据 fixed-delay/fixed-rate 模式来设置下次执行时间并重新将任务塞到工作队列
在调度线程池中无论是 runnable 还是 callable,无论是否需要延迟和定时,所有的任务都会被封装成 ScheduledFutureTask
1 | private class ScheduledFutureTask<V> extends FutureTask<V> implements RunnableScheduledFuture<V> |
成员变量:
-
任务序列号:
1
private final long sequenceNumber;
-
执行时间:
1
2private long time; // 任务可以被执行的时间,交付时间,以纳秒表示
private final long period; // 0 表示非周期任务,正数表示 fixed-rate 模式的周期,负数表示 fixed-delay 模式fixed-rate:两次开始启动的间隔,fixed-delay:一次执行结束到下一次开始启动
-
实际的任务对象:
1
RunnableScheduledFuture<V> outerTask = this;
-
任务在队列数组中的索引下标:
1
2// DelayedWorkQueue 底层使用的数据结构是最小堆,记录当前任务在堆中的索引,-1 代表删除
int heapIndex;
成员方法:
-
构造方法:
1
2
3
4
5
6
7ScheduledFutureTask(Runnable r, V result, long triggerTime,
long sequenceNumber) {
super(r, result);
this.time = triggerTime;
this.period = 0;
this.sequenceNumber = sequenceNumber;
} -
compareTo():ScheduledFutureTask 根据执行时间 time 正序排列,如果执行时间相同,在按照序列号 sequenceNumber 正序排列,任务需要放入 DelayedWorkQueue,延迟队列中使用该方法按照从小到大进行排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public int compareTo(Delayed other) {
if (other == this) // compare zero if same object
return 0;
if (other instanceof ScheduledFutureTask) {
// 类型强转
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
// 比较者 - 被比较者的执行时间
long diff = time - x.time;
// 比较者先执行
if (diff < 0)
return -1;
// 被比较者先执行
else if (diff > 0)
return 1;
// 比较者的序列号小
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
// 不是 ScheduledFutureTask 类型时,根据延迟时间排序
long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
} -
run():执行任务,非周期任务直接完成直接结束,周期任务执行完后会设置下一次的执行时间,重新放入线程池的阻塞队列,如果线程池中的线程数量少于核心线程,就会添加 Worker 开启新线程
1
2
3
4
5
6
7
8
9
10
11
12
13public void run() {
// 检查当前任务是否可以在当前运行状态下执行,如果不可以则取消任务
if (!canRunInCurrentRunState(this))
cancel(false);
// 如果不是周期性任务,则执行普通的任务运行逻辑
else if (!isPeriodic())
super.run();
// 如果是周期性任务且本次执行成功,则设置下一次运行时间并重新安排任务执行
else if (super.runAndReset()) {
setNextRunTime();
reExecutePeriodic(outerTask);
}
}周期任务正常完成后任务的状态不会变化,依旧是 NEW,不会设置 outcome 属性。但是如果本次任务执行出现异常,会进入 setException 方法将任务状态置为异常,把异常保存在 outcome 中,方法返回 false,后续的该任务将不会再周期的执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40protected boolean runAndReset() {
// 检查任务状态是否为NEW(初始状态),并且尝试通过CAS操作将runner设置为当前线程
// 如果状态不是NEW或者CAS操作失败,则返回false
if (state != NEW ||
!RUNNER.compareAndSet(this, null, Thread.currentThread()))
return false;
// 标识任务是否成功执行
boolean ran = false;
// 获取当前任务状态
int s = state;
try {
// 获取任务的Callable对象
Callable<V> c = callable;
// 如果Callable不为空且任务状态仍为NEW,则执行任务
if (c != null && s == NEW) {
try {
c.call(); // 执行任务但不设置结果(与run()方法的区别)
ran = true; // 标记任务执行成功
} catch (Throwable ex) {
// 如果执行过程中出现异常,则设置异常
setException(ex);
}
}
} finally {
// 在任务执行完成后,必须将runner置为null,直到状态确定为止
// 这样可以防止并发调用run()方法
runner = null;
// 在将runner置为null后必须重新读取状态,以防止中断泄漏
s = state;
// 如果状态表明可能有中断,则处理可能的取消中断
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
// 返回任务是否成功执行且状态仍为NEW
// 这对于周期性任务很重要,确保任务完成后可以重新调度
return ran && s == NEW;
}1
2
3
4
5
6
7
8
9
10// 任务下一次的触发时间
private void setNextRunTime() {
long p = period;
if (p > 0)
// fixed-rate 模式,【时间设置为上一次执行任务的时间 + p】,两次任务执行的时间差
time += p;
else
// fixed-delay 模式,下一次执行时间是【当前这次任务结束的时间(就是现在) + delay 值】
time = triggerTime(-p);
} -
reExecutePeriodic():准备任务的下一次执行,重新放入阻塞任务队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void reExecutePeriodic(RunnableScheduledFuture<?> task) {
// 检查任务是否可以在当前运行状态下执行
if (canRunInCurrentRunState(task)) {
// 将任务重新加入队列,准备下一次执行
super.getQueue().add(task);
// 再次检查任务是否可以在当前运行状态下执行,或者从队列中移除任务失败
// 这是为了处理在加入队列后运行状态可能发生变化的情况
if (canRunInCurrentRunState(task) || !remove(task)) {
// 确保线程池已启动(必要时启动新线程)
ensurePrestart();
return;
}
}
// 如果任务不能运行,则取消任务(不中断正在执行的任务)
task.cancel(false);
} -
cancel():取消任务
1
2
3
4
5
6
7
8
9public boolean cancel(boolean mayInterruptIfRunning) {
// 调用父类 FutureTask#cancel 来取消任务
boolean cancelled = super.cancel(mayInterruptIfRunning);
// removeOnCancel 用于控制任务取消后是否应该从阻塞队列中移除
if (cancelled && removeOnCancel && heapIndex >= 0)
// 从等待队列中删除该任务,并调用 tryTerminate() 判断是否需要停止线程池
remove(this);
return cancelled;
}
延迟队列
成员方法
提交任务
-
schedule():延迟执行方法,并指定执行的时间,默认是当前时间
1
2
3
4public void execute(Runnable command) {
// 以零延时任务的形式实现
schedule(command, 0, NANOSECONDS);
}1
2
3
4
5
6
7
8
9
10public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) {
// 判空
if (command == null || unit == null) throw new NullPointerException();
// 没有做任何操作,直接将 task 返回,该方法主要目的是用于子类扩展,并且【根据延迟时间设置任务触发的时间点】
RunnableScheduledFuture<?> t = decorateTask(command, new ScheduledFutureTask<Void>(
command, null, triggerTime(delay, unit)));
// 延迟执行
delayedExecute(t);
return t;
}1
2
3
4
5
6
7
8
9
10// 返回【当前时间 + 延迟时间】,就是触发当前任务执行的时间
private long triggerTime(long delay, TimeUnit unit) {
// 设置触发的时间
return triggerTime(unit.toNanos((delay < 0) ? 0 : delay));
}
long triggerTime(long delay) {
// 如果 delay < Long.Max_VALUE/2,则下次执行时间为当前时间 +delay
// 否则为了避免队列中出现由于溢出导致的排序紊乱,需要调用overflowFree来修正一下delay
return now() + ((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));
}overflowFree 的原因:如果某个任务的 delay 为负数,说明当前可以执行(其实早该执行了)。阻塞队列中维护任务顺序是基于 compareTo 比较的,比较两个任务的顺序会用 time 相减。那么可能出现一个 delay 为正数减去另一个为负数的 delay,结果上溢为负数,则会导致 compareTo 产生错误的结果
1
2
3
4
5
6
7
8
9
10
11
12private long overflowFree(long delay) {
Delayed head = (Delayed) super.getQueue().peek();
if (head != null) {
long headDelay = head.getDelay(NANOSECONDS);
// 判断一下队首的delay是不是负数,如果是正数就不用管,怎么减都不会溢出
// 否则拿当前 delay 减去队首的 delay 来比较看,如果不出现上溢,排序不会乱
// 不然就把当前 delay 值给调整为 Long.MAX_VALUE + 队首 delay
if (headDelay < 0 && (delay - headDelay < 0))
delay = Long.MAX_VALUE + headDelay;
}
return delay;
} -
scheduleAtFixedRate():定时执行,一次任务的启动到下一次任务的启动的间隔
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0)
throw new IllegalArgumentException();
// 任务封装,【指定初始的延迟时间和周期时间】
ScheduledFutureTask<Void> sft =new ScheduledFutureTask<Void>(command, null,
triggerTime(initialDelay, unit), unit.toNanos(period));
// 默认返回本身
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
// 开始执行这个任务
delayedExecute(t);
return t;
} -
scheduleWithFixedDelay():定时执行,一次任务的结束到下一次任务的启动的间隔
1
2
3
4
5
6
7
8
9
10
11
12
13
14public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0)
throw new IllegalArgumentException();
// 任务封装,【指定初始的延迟时间和周期时间】,周期时间为 - 表示是 fixed-delay 模式
ScheduledFutureTask<Void> sft = new ScheduledFutureTask<Void>(command, null,
triggerTime(initialDelay, unit), unit.toNanos(-delay));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
运行任务
-
delayedExecute():校验线程池状态,延迟或周期性任务的主要执行方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15private void delayedExecute(RunnableScheduledFuture<?> task) {
// 线程池是 SHUTDOWN 状态,需要执行拒绝策略
if (isShutdown())
reject(task);
else {
// 把当前任务放入阻塞队列,因为需要【获取执行时间最近的】,当前任务需要比较
super.getQueue().add(task);
// 线程池状态为 SHUTDOWN 并且不允许执行任务了,就从队列删除该任务,并设置任务的状态为取消状态
if (isShutdown() && !canRunInCurrentRunState(task.isPeriodic()) && remove(task))
task.cancel(false);
else
// 可以执行
ensurePrestart();
}
} -
ensurePrestart():开启线程执行任务
1
2
3
4
5
6
7
8
9
10
11// ThreadPoolExecutor#ensurePrestart
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
// worker数目小于corePoolSize,则添加一个worker。
if (wc < corePoolSize)
// 第二个参数 true 表示采用核心线程数量限制,false 表示采用 maximumPoolSize
addWorker(null, true);
// corePoolSize = 0的情况,至少开启一个线程,【担保机制】
else if (wc == 0)
addWorker(null, false);
} -
canRunInCurrentRunState():任务运行时都会被调用以校验当前状态是否可以运行任务
1
2
3
4
5boolean canRunInCurrentRunState(boolean periodic) {
// 根据是否是周期任务判断,在线程池 shutdown 后是否继续执行该任务,默认非周期任务是继续执行的
return isRunningOrShutdown(periodic ? continueExistingPeriodicTasksAfterShutdown :
executeExistingDelayedTasksAfterShutdown);
} -
onShutdown():删除并取消工作队列中的不需要再执行的任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29void onShutdown() {
BlockingQueue<Runnable> q = super.getQueue();
// shutdown 后是否仍然执行延时任务
boolean keepDelayed = getExecuteExistingDelayedTasksAfterShutdownPolicy();
// shutdown 后是否仍然执行周期任务
boolean keepPeriodic = getContinueExistingPeriodicTasksAfterShutdownPolicy();
// 如果两者皆不可,则对队列中【所有任务】调用 cancel 取消并清空队列
if (!keepDelayed && !keepPeriodic) {
for (Object e : q.toArray())
if (e instanceof RunnableScheduledFuture<?>)
((RunnableScheduledFuture<?>) e).cancel(false);
q.clear();
}
else {
for (Object e : q.toArray()) {
if (e instanceof RunnableScheduledFuture) {
RunnableScheduledFuture<?> t = (RunnableScheduledFuture<?>)e;
// 不需要执行的任务删除并取消,已经取消的任务也需要从队列中删除
if ((t.isPeriodic() ? !keepPeriodic : !keepDelayed) ||
t.isCancelled()) {
if (q.remove(t))
t.cancel(false);
}
}
}
}
// 因为任务被从队列中清理掉,所以需要调用 tryTerminate 尝试【改变线程池的状态】
tryTerminate();
}
*模式之Worker Thread
定义
让有限的工作线程(Worker Thread)来轮流异步处理无限多的任务。也可以将其归类为分工模式,它的典型实现 就是线程池,也体现了经典设计模式中的享元模式。
例如,海底捞的服务员(线程),轮流处理每位客人的点餐(任务),如果为每位客人都配一名专属的服务员,那么成本就太高了(对比另一种多线程设计模式:Thread-Per-Message)
注意,不同任务类型应该使用不同的线程池,这样能够避免饥饿,并能提升效率
例如,如果一个餐馆的工人既要招呼客人(任务类型A),又要到后厨做菜(任务类型B)显然效率不咋地,分成 服务员(线程池A)与厨师(线程池B)更为合理,当然你能想到更细致的分工
饥饿
固定大小线程池会有饥饿现象
- 两个工人是同一个线程池中的两个线程
- 他们要做的事情是:为客人点餐和到后厨做菜,这是两个阶段的工作
- 客人点餐:必须先点完餐,等菜做好,上菜,在此期间处理点餐的工人必须等待
- 后厨做菜:没啥说的,做就是了
- 比如工人A 处理了点餐任务,接下来它要等着 工人B 把菜做好,然后上菜,他俩也配合的蛮好
- 但现在同时来了两个客人,这个时候工人A 和工人B 都去处理点餐了,这时没人做饭了,饥饿
1 | public class TestDeadLock { |
输出
17:21:27.883 c.TestDeadLock [pool-1-thread-1] - 处理点餐... 17:21:27.891 c.TestDeadLock [pool-1-thread-2] - 做菜 17:21:27.891 c.TestDeadLock [pool-1-thread-1] - 上菜: 烤鸡翅
当注释取消后,可能的输出
17:08:41.339 c.TestDeadLock [pool-1-thread-2] - 处理点餐... 17:08:41.339 c.TestDeadLock [pool-1-thread-1] - 处理点餐...
解决方法可以增加线程池的大小,不过不是根本解决方案,还是前面提到的,不同的任务类型,采用不同的线程池,例如:
1 | public class TestDeadLock { |
输出
17:25:14.626 c.TestDeadLock [pool-1-thread-1] - 处理点餐... 17:25:14.630 c.TestDeadLock [pool-2-thread-1] - 做菜 17:25:14.631 c.TestDeadLock [pool-1-thread-1] - 上菜: 地三鲜 17:25:14.632 c.TestDeadLock [pool-1-thread-1] - 处理点餐... 17:25:14.632 c.TestDeadLock [pool-2-thread-1] - 做菜 17:25:14.632 c.TestDeadLock [pool-1-thread-1] - 上菜: 辣子鸡丁
*应用之定时任务
如何让每周四 18:00:00 定时执行任务?
1 | // 获得当前时间 |
7.1.8 Tomcat线程池
Tomcat 在哪里用到了线程池呢

- LimitLatch 用来限流,可以控制最大连接个数,类似 J.U.C 中的 Semaphore
- Acceptor 只负责【接收新的 socket 连接】
- Poller 只负责监听 socket channel 是否有【可读的 I/O 事件】
- 一旦可读,封装一个任务对象(socketProcessor),提交给 Executor 线程池处理
- Executor 线程池中的工作线程最终负责【处理请求】
Tomcat 线程池扩展了 ThreadPoolExecutor,行为稍有不同
- 如果总线程数达到 maximumPoolSize
- 这时不会立刻抛 RejectedExecutionException 异常
- 而是再次尝试将任务放入队列,如果还失败,才抛出 RejectedExecutionException 异常
源码 tomcat-7.0.42
1 | public void execute(Runnable command, long timeout, TimeUnit unit) { |
TaskQueue.java
1 | public boolean force(Runnable o, long timeout, TimeUnit unit) throws InterruptedException { |
Connector 配置
| 配置项 | 默认值 | 说明 |
|---|---|---|
acceptorThreadCount |
1 | acceptor 线程数量 |
pollerThreadCount |
1 | poller 线程数量 |
minSpareThreads |
10 | 核心线程数,即 corePoolSize |
maxThreads |
200 | 最大线程数,即 maximumPoolSize |
executor |
- | Executor 名称,用来引用下面的 Executor |
Executor 线程配置
| 配置项 | 默认值 | 说明 |
|---|---|---|
threadPriority |
5 | 线程优先级 |
deamon |
true | 是否守护线程 |
minSpareThreads |
25 | 核心线程数,即corePoolSize |
maxThreads |
200 | 最大线程数,即 maximumPoolSize |
maxIdleTime |
60000 | 线程生存时间,单位是毫秒,默认值即 1 分钟 |
maxQueueSize |
Integer.MAX_VALUE | 队列长度 |
prestartminSpareThreads |
false | 核心线程是否在服务器启动时启动 |

7.1.9 Fork/Join
概念
Fork/Join 是 JDK 1.7 加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型 运算
所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解
- Fork/Join 在分治的基础上加入了多线程,把每个任务的分解和合并交给不同的线程来完成,提升了运算效率
- ForkJoin 使用 ForkJoinPool 来启动,是一个特殊的线程池,默认会创建与 CPU 核心数大小相同的线程池
- 任务有返回值继承 RecursiveTask,没有返回值继承 RecursiveAction
ForkJoinPool 实现了工作窃取算法来提高 CPU 的利用率:
- 每个线程都维护了一个双端队列,用来存储需要执行的任务
- 工作窃取算法允许空闲的线程从其它线程的双端队列中窃取一个任务来执行
- 窃取的必须是最晚的任务,避免和队列所属线程发生竞争,但是队列中只有一个任务时还是会发生竞争
应用之求和
提交给 Fork/Join 线程池的任务需要继承 RecursiveTask(有返回值)或 RecursiveAction(没有返回值),例如下面定义了一个对 1~n 之间的整数求和的任务
1 |
|
然后提交给 ForkJoinPool 来执行
1 | public static void main(String[] args) { |
结果
[ForkJoinPool-1-worker-0] - fork() 2 + {1}
[ForkJoinPool-1-worker-1] - fork() 5 + {4}
[ForkJoinPool-1-worker-0] - join() 1
[ForkJoinPool-1-worker-0] - join() 2 + {1} = 3
[ForkJoinPool-1-worker-2] - fork() 4 + {3}
[ForkJoinPool-1-worker-3] - fork() 3 + {2}
[ForkJoinPool-1-worker-3] - join() 3 + {2} = 6
[ForkJoinPool-1-worker-2] - join() 4 + {3} = 10
[ForkJoinPool-1-worker-1] - join() 5 + {4} = 15
15
用图来表示

改进
1 | class AddTask3 extends RecursiveTask<Integer> { |
然后提交给 ForkJoinPool 来执行
1 | public static void main(String[] args) { |
结果
[ForkJoinPool-1-worker-0] - join() 1 + 2 = 3
[ForkJoinPool-1-worker-3] - join() 4 + 5 = 9
[ForkJoinPool-1-worker-0] - join() 3
[ForkJoinPool-1-worker-1] - fork() {1,3} + {4,5} = ?
[ForkJoinPool-1-worker-2] - fork() {1,2} + {3,3} = ?
[ForkJoinPool-1-worker-2] - join() {1,2} + {3,3} = 6
[ForkJoinPool-1-worker-1] - join() {1,3} + {4,5} = 15
15
用图来表示

7.2 ThreadLocal
7.2.1 基本介绍
ThreadLocal 类用来提供线程内部的局部变量,这种变量在多线程环境下访问(通过 get 和 set 方法访问)时能保证各个线程的变量相对独立于其他线程内的变量,分配在堆内的 TLAB 中
ThreadLocal 实例通常来说都是 private static 类型的,属于一个线程的本地变量,用于关联线程和线程上下文。每个线程都会在 ThreadLocal 中保存一份该线程独有的数据,所以是线程安全的
ThreadLocal 作用:
-
线程并发:应用在多线程并发的场景下
-
传递数据:通过 ThreadLocal 实现在同一线程不同函数或组件中传递公共变量,减少传递复杂度
-
线程隔离:每个线程的变量都是独立的,不会互相影响
对比 synchronized:
| synchronized | ThreadLocal | |
|---|---|---|
| 原理 | 同步机制采用以时间换空间的方式,只提供了一份变量,让不同的线程排队访问 | ThreadLocal 采用以空间换时间的方式,为每个线程都提供了一份变量的副本,从而实现同时访问而相不干扰 |
| 侧重点 | 多个线程之间访问资源的同步 | 多线程中让每个线程之间的数据相互隔离 |
7.2.2 基本使用
常用方法
| 方法 | 描述 |
|---|---|
| ThreadLocal<>() | 创建 ThreadLocal 对象 |
| protected T initialValue() | 返回当前线程局部变量的初始值 |
| public void set( T value) | 设置当前线程绑定的局部变量 |
| public T get() | 获取当前线程绑定的局部变量 |
| public void remove() | 移除当前线程绑定的局部变量 |
1 | public class MyDemo { |
应用场景
-
用户身份信息存储
- 登录鉴权通过后,把用户信息存储在ThreadLocal中,这样在后续的所有流程中,可直接从ThreadLocal中获取用户信息。
-
线程安全
- ThreadLocal可以用来定义一些需要并发安全处理的成员变量,比如可以使用ThreadLocal为每个线程创建一个独立的SimpleDateFormat实例,从而避免线程安全问题。
-
数据库Session
- 很多ORM框架,如Hibernate、Mybatis,都是使用ThreadLocal来存储和管理数据库会话的。这样可以确保每个线程都有自己的会话实例,避免了在多线程环境中出现线程安全问题。
-
日志上下文存储
- 在Log4j等日志框架中,经常使用ThreadLocal来存储与当前线程相关的日志上下文。这允许开发者在日志消息中包含特定于线程的信息,如用户ID或事务ID,这对于调试和监控是非常有用的。
-
traceld存储
- 和上面存储日志上下文类似,在分布式链路追踪中,需要存储本次请求的traceld,通常也都是基于ThreadLocal存储的。
-
PageHelper分页
- PageHelper是MyBatis中提供的分页插件,主要是用来做物理分页的。我们在代码中设置的分页参数信息,页码和页大小等信息都会存储在ThreadLocal中,方便在执行分页时读取这些数据。
ThreadLocal 方案有两个突出的优势:
- 传递数据:保存每个线程绑定的数据,在需要的地方可以直接获取,避免参数直接传递带来的代码耦合问题
- 线程隔离:各线程之间的数据相互隔离却又具备并发性,避免同步方式带来的性能损失
ThreadLocal 用于数据连接的事务管理:
1 | public class JdbcUtils { |
用 ThreadLocal 使 SimpleDateFormat 从独享变量变成单个线程变量:
1 | public class ThreadLocalDateUtil { |
7.2.3 实现原理
底层结构
JDK8 以前:每个 ThreadLocal 都创建一个 Map,然后用线程作为 Map 的 key,要存储的局部变量作为 Map 的 value,达到各个线程的局部变量隔离的效果。这种结构会造成 Map 结构过大和内存泄露,因为 Thread 停止后无法通过 key 删除对应的数据

JDK8 以后:每个 Thread 维护一个 ThreadLocalMap,这个 Map 的 key 是 ThreadLocal 实例本身,value 是真正要存储的值
- 每个 Thread 线程内部都有一个 Map (ThreadLocalMap)
- Map 里面存储 ThreadLocal 对象(key)和线程的私有变量(value)
- Thread 内部的 Map 是由 ThreadLocal 维护的,由 ThreadLocal 负责向 map 获取和设置线程的变量值
- 对于不同的线程,每次获取副本值时,别的线程并不能获取到当前线程的副本值,形成副本的隔离,互不干扰

JDK8 前后对比:
- 每个 Map 存储的 Entry 数量会变少,因为之前的存储数量由 Thread 的数量决定,现在由 ThreadLocal 的数量决定,在实际编程当中,往往 ThreadLocal 的数量要少于 Thread 的数量
- 当 Thread 销毁之后,对应的 ThreadLocalMap 也会随之销毁,能减少内存的使用,防止内存泄露
成员变量
-
Thread 类的相关属性:每一个线程持有一个 ThreadLocalMap 对象,存放由 ThreadLocal 和数据组成的 Entry 键值对
1
ThreadLocal.ThreadLocalMap threadLocals = null
-
计算 ThreadLocal 对象的哈希值:
1
private final int threadLocalHashCode = nextHashCode()
-
每创建一个 ThreadLocal 对象就会使用 nextHashCode 分配一个 hash 值给这个对象:
1
private static AtomicInteger nextHashCode = new AtomicInteger()
-
斐波那契数也叫黄金分割数,hash 的增量就是这个数字,带来的好处是 hash 分布非常均匀:
1
private static final int HASH_INCREMENT = 0x61c88647
成员方法
方法都是线程安全的,因为 ThreadLocal 属于一个线程的,ThreadLocal 中的方法,逻辑都是获取当前线程维护的ThreadLocalMap 对象,然后进行数据的增删改查,没有指定初始值的 threadlcoal 对象默认赋值为 null
-
initialValue():返回该线程局部变量的初始值
- 延迟调用的方法,在执行 get 方法时才执行
- 该方法缺省(默认)实现直接返回一个 null
- 如果想要一个初始值,可以重写此方法, 该方法是一个
protected的方法,为了让子类覆盖而设计的
1
2
3protected T initialValue() {
return null;
} -
nextHashCode():计算哈希值,ThreadLocal 的散列方式称之为斐波那契散列,每次获取哈希值都会加上 HASH_INCREMENT,这样做可以尽量避免 hash 冲突,让哈希值能均匀的分布在 2 的 n 次方的数组中
1
2
3
4private static int nextHashCode() {
// 哈希值自增一个 HASH_INCREMENT 数值
return nextHashCode.getAndAdd(HASH_INCREMENT);
} -
set():修改当前线程与当前 threadlocal 对象相关联的线程局部变量
1
2
3
4
5
6
7
8
9
10
11
12
13public void set(T value) {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 获取此线程对象中维护的 ThreadLocalMap 对象
ThreadLocalMap map = getMap(t);
// 判断 map 是否存在
if (map != null)
// 调用 threadLocalMap.set 方法进行重写或者添加
map.set(this, value);
else
// map 为空,调用 createMap 进行 ThreadLocalMap 对象的初始化。参数1是当前线程,参数2是局部变量
createMap(t, value);
}1
2
3
4
5
6
7
8
9// 获取当前线程 Thread 对应维护的 ThreadLocalMap
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
// 创建当前线程Thread对应维护的ThreadLocalMap
void createMap(Thread t, T firstValue) {
// 【这里的 this 是调用此方法的 threadLocal】,创建一个新的 Map 并设置第一个数据
t.threadLocals = new ThreadLocalMap(this, firstValue);
} -
get():获取当前线程与当前 ThreadLocal 对象相关联的线程局部变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
// 如果此map存在
if (map != null) {
// 以当前的 ThreadLocal 为 key,调用 getEntry 获取对应的存储实体 e
ThreadLocalMap.Entry e = map.getEntry(this);
// 对 e 进行判空
if (e != null) {
// 获取存储实体 e 对应的 value值
T result = (T)e.value;
return result;
}
}
/*有两种情况有执行当前代码
第一种情况: map 不存在,表示此线程没有维护的 ThreadLocalMap 对象
第二种情况: map 存在, 但是【没有与当前 ThreadLocal 关联的 entry】,就会设置为默认值
*/
// 初始化当前线程与当前 threadLocal 对象相关联的 value
return setInitialValue();
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15private T setInitialValue() {
// 调用initialValue获取初始化的值,此方法可以被子类重写, 如果不重写默认返回 null
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
// 判断 map 是否初始化过
if (map != null)
// 存在则调用 map.set 设置此实体 entry,value 是默认的值
map.set(this, value);
else
// 调用 createMap 进行 ThreadLocalMap 对象的初始化中
createMap(t, value);
// 返回线程与当前 threadLocal 关联的局部变量
return value;
} -
remove():移除当前线程与当前 threadLocal 对象相关联的线程局部变量
1
2
3
4
5
6
7public void remove() {
// 获取当前线程对象中维护的 ThreadLocalMap 对象
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
// map 存在则调用 map.remove,this时当前ThreadLocal,以this为key删除对应的实体
m.remove(this);
}
7.2.4 ThreadLocalMap
成员属性
ThreadLocalMap 是 ThreadLocal 的内部类,它没有实现任何 Map 接口,使用独立实现的Entry 类数组。
1 | // 初始化当前 map 内部散列表数组的初始长度 16 |
存储结构 Entry:
- Entry 继承 WeakReference,key 是弱引用,目的是将 ThreadLocal 对象的生命周期和线程生命周期解绑
- Entry 限制只能用 ThreadLocal 作为 key,key 为 null 意味着 key 不再被引用,entry 也可以从 table 中清除
1 | static class Entry extends WeakReference<ThreadLocal<?>> { |
构造方法:延迟初始化的,线程第一次存储 threadLocal - value 时才会创建 threadLocalMap 对象
1 | ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { |
成员方法
-
set():添加数据,ThreadLocalMap 使用线性探测法来解决哈希冲突
-
该方法会一直探测下一个地址,直到有空的地址后插入,若插入后 Map 数量超过阈值,数组会扩容为原来的 2 倍
假设当前 table 长度为16,计算出来 key 的 hash 值为 14,如果 table[14] 上已经有值,并且其 key 与当前 key 不一致,那么就发生了 hash 冲突,这个时候将 14 加 1 得到 15,取 table[15] 进行判断,如果还是冲突会回到 0,取 table[0],以此类推,直到可以插入,可以把 Entry[] table 看成一个环形数组
-
线性探测法会出现堆积问题,可以采取平方探测法解决
-
在探测过程中 ThreadLocal 会复用 key 为 null 的脏 Entry 对象,并进行垃圾清理,防止出现内存泄漏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35private void set(ThreadLocal<?> key, Object value) {
// 获取散列表和长度
Entry[] tab = table;
int len = tab.length;
// 哈希寻址
int i = key.threadLocalHashCode & (len-1);
// 从计算出的索引位置开始,使用线性探测法处理哈希冲突
for (Entry e = tab[i];
e != null; // 继续循环直到找到空位置
e = tab[i = nextIndex(i, len)]) { // 移动到下一个位置
// 情况1:ThreadLocal 对应的 key 存在,【直接覆盖之前的值】
if (e.refersTo(key)) {
e.value = value;
return;
}
// 情况2:key 为 null,但是值不为 null,说明之前的 ThreadLocal 对象已经被回收了,当前是【过期数据】
if (e.refersTo(null)) {
// 【碰到一个过期的 slot,当前数据复用该槽位,替换过期数据】
// 这个方法还进行了垃圾清理动作,防止内存泄漏
replaceStaleEntry(key, value, i);
return;
}
}
// 逻辑到这说明碰到 slot == null 的位置,则在空元素的位置创建一个新的 Entry
tab[i] = new Entry(key, value);
// 数量 + 1
int sz = ++size;
// 【做一次启发式清理】,如果没有清除任何 entry 并且【当前使用量达到了负载因子所定义】,那么进行 rehash
if (!cleanSomeSlots(i, sz) && sz >= threshold)
// 扩容
rehash();
}1
2
3
4
5// 获取【环形数组】的下一个索引
private static int nextIndex(int i, int len) {
// 索引越界后从 0 开始继续获取
return ((i + 1 < len) ? i + 1 : 0);
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48// 在指定位置插入指定的数据
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) {
// 获取散列表
Entry[] tab = table;
int len = tab.length;
Entry e;
// 探测式清理的开始下标,默认从当前 staleSlot 开始
int slotToExpunge = staleSlot;
// 以当前 staleSlot 开始【向前迭代查找】,找到索引靠前过期数据,找到以后替换 slotToExpunge 值
// 【保证在一个区间段内,从最前面的过期数据开始清理】
for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len))
if (e.refersTo(null))
slotToExpunge = i;
// 以 staleSlot 【向后去查找】,直到碰到 null 为止,还是线性探测
for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
// 条件成立说明是【替换逻辑】
if (e.refersTo(key)) {
e.value = value;
// 因为本来要在 staleSlot 索引处插入该数据,现在找到了i索引处的key与数据一致
// 但是 i 位置距离正确的位置更远,因为是向后查找,所以还是要在 staleSlot 位置插入当前 entry
// 然后将 table[staleSlot] 这个过期数据放到当前循环到的 table[i] 这个位置,
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// 条件成立说明向前查找过期数据并未找到过期的 entry,但 staleSlot 位置已经不是过期数据,i 位置才是
if (slotToExpunge == staleSlot)
slotToExpunge = i;
// 【清理过期数据,expungeStaleEntry 探测式清理,cleanSomeSlots 启发式清理】
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// 条件成立说明当前遍历的 entry 是一个过期数据,并且该位置前面也没有过期数据
if (e.refersTo(null) && slotToExpunge == staleSlot)
// 探测式清理过期数据的开始下标修改为当前循环的 index,因为 staleSlot 会放入要添加的数据
slotToExpunge = i;
}
// 向后查找过程中并未发现 k == key 的 entry,说明当前是一个【取代过期数据逻辑】
// 删除原有的数据引用,防止内存泄露
tab[staleSlot].value = null;
// staleSlot 位置添加数据,【上面的所有逻辑都不会更改 staleSlot 的值】
tab[staleSlot] = new Entry(key, value);
// 条件成立说明除了 staleSlot 以外,还发现其它的过期 slot,所以要【开启清理数据的逻辑】
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
1
2
3
4private static int prevIndex(int i, int len) {
// 形成一个环绕式的访问,头索引越界后置为尾索引
return ((i - 1 >= 0) ? i - 1 : len - 1);
}1
2
3private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
} -
-
getEntry():ThreadLocal 的 get 方法以当前的 ThreadLocal 为 key,调用 getEntry 获取对应的存储实体 e
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36private Entry getEntry(ThreadLocal<?> key) {
// 哈希寻址
int i = key.threadLocalHashCode & (table.length - 1);
// 访问散列表中指定指定位置的 slot
Entry e = table[i];
// 条件成立,说明 slot 有值并且 key 就是要寻找的 key,直接返回
if (e != null && e.get() == key)
return e;
else
// 进行线性探测
return getEntryAfterMiss(key, i, e);
}
// 线性探测寻址
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
// 获取散列表
Entry[] tab = table;
int len = tab.length;
// 开始遍历,碰到 slot == null 的情况,搜索结束
while (e != null) {
// 条件成立说明找到了,直接返回
if (e.refersTo(key))
return e;
if (e.refersTo(null))
// 过期数据,【探测式过期数据回收】
expungeStaleEntry(i);
else
// 更新 index 继续向后走
i = nextIndex(i, len);
// 获取下一个槽位中的 entry
e = tab[i];
}
// 说明当前区段没有找到相应数据
// 【因为存放数据是线性的向后寻找槽位,都是紧挨着的,不可能越过一个 空槽位 在后面放】,可以减少遍历的次数
return null;
} -
rehash():触发一次全量清理,如果数组长度大于等于长度的
2/3 * 3/4 = 1/2,则进行 resize1
2
3
4
5
6
7
8private void rehash() {
// 清楚当前散列表内的【所有】过期的数据
expungeStaleEntries();
// threshold = len * 2 / 3,就是 2/3 * (1 - 1/4)
if (size >= threshold - threshold / 4)
resize();
}1
2
3
4
5
6
7
8
9
10private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
// 【遍历所有的槽位,清理过期数据】
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.refersTo(null))
expungeStaleEntry(j);
}
}Entry 数组为扩容为原来的 2 倍 ,重新计算 key 的散列值,如果遇到 key 为 null 的情况,会将其 value 也置为 null,帮助 GC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
// 新数组的长度是老数组的二倍
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
// 统计新table中的entry数量
int count = 0;
// 遍历老表,进行【数据迁移】
for (Entry e : oldTab) {
// 条件成立说明老表中该位置有数据,可能是过期数据也可能不是
if (e != null) {
ThreadLocal<?> k = e.get();
// 过期数据
if (k == null) {
e.value = null; // Help the GC
} else {
// 非过期数据,在新表中进行哈希寻址
int h = k.threadLocalHashCode & (newLen - 1);
// 【线程探测】
while (newTab[h] != null)
h = nextIndex(h, newLen);
// 将数据存放到新表合适的 slot 中
newTab[h] = e;
count++;
}
}
}
// 设置下一次触发扩容的指标:threshold = len * 2 / 3;
setThreshold(newLen);
size = count;
// 将扩容后的新表赋值给 threadLocalMap 内部散列表数组引用
table = newTab;
} -
remove():删除 Entry
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
// 哈希寻址
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
// 找到了对应的 key
if (e.refersTo(key)) {
// 设置 key 为 null
e.clear();
// 探测式清理
expungeStaleEntry(i);
return;
}
}
}
清理方法
-
探测式清理:沿着开始位置向后探测清理过期数据,沿途中碰到未过期数据则将此数据 rehash 在 table 数组中的定位,重定位后的元素理论上更接近
i = entry.key & (table.length - 1),让数据的排列更紧凑,会优化整个散列表查询性能1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42// table[staleSlot] 是一个过期数据,以这个位置开始继续向后查找过期数据
private int expungeStaleEntry(int staleSlot) {
// 获取散列表和数组长度
Entry[] tab = table;
int len = tab.length;
// help gc,先把当前过期的 entry 置空,在取消对 entry 的引用
tab[staleSlot].value = null;
tab[staleSlot] = null;
// 数量-1
size--;
Entry e;
int i;
// 从 staleSlot 开始向后遍历,直到碰到 slot == null 结束,【区间内清理过期数据】
for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 当前 entry 是过期数据
if (k == null) {
// help gc
e.value = null;
tab[i] = null;
size--;
} else {
// 当前 entry 不是过期数据的逻辑,【rehash】
// 重新计算当前 entry 对应的 index
int h = k.threadLocalHashCode & (len - 1);
// 条件成立说明当前 entry 存储时发生过 hash 冲突,向后偏移过了
if (h != i) {
// 当前位置置空
tab[i] = null;
// 以正确位置 h 开始,向后查找第一个可以存放 entry 的位置
while (tab[h] != null)
h = nextIndex(h, len);
// 将当前元素放入到【距离正确位置更近的位置,有可能就是正确位置】
tab[h] = e;
}
}
}
// 返回 slot = null 的槽位索引,图例是 7,这个索引代表【索引前面的区间已经清理完成垃圾了】
return i;
}

-
启发式清理:向后循环扫描过期数据,发现过期数据调用探测式清理方法,如果连续几次的循环都没有发现过期数据,就停止扫描
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// i 表示启发式清理工作开始位置,一般是空 slot,n 一般传递的是 table.length
private boolean cleanSomeSlots(int i, int n) {
// 表示启发式清理工作是否清除了过期数据
boolean removed = false;
// 获取当前 map 的散列表引用
Entry[] tab = table;
int len = tab.length;
do {
// 获取下一个索引,因为探测式返回的 slot 为 null
i = nextIndex(i, len);
Entry e = tab[i];
// 条件成立说明是过期的数据,key 被 gc 了
if (e != null && e.refersTo(null)) {
// 【发现过期数据重置 n 为数组的长度】
n = len;
// 表示清理过过期数据
removed = true;
// 以当前过期的 slot 为开始节点 做一次探测式清理工作
i = expungeStaleEntry(i);
}
// 假设 table 长度为 16
// 16 >>> 1 ==> 8,8 >>> 1 ==> 4,4 >>> 1 ==> 2,2 >>> 1 ==> 1,1 >>> 1 ==> 0
// 连续经过这么多次循环【没有扫描到过期数据】,就停止循环,扫描到空 slot 不算,因为不是过期数据
} while ((n >>>= 1) != 0);
// 返回清除标记
return removed;
}
7.2.5 内存泄漏
Memory leak:内存泄漏是指程序中动态分配的堆内存由于某种原因未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果,内存泄漏的堆积终将导致内存溢出
-
如果 key 使用强引用:使用完 ThreadLocal ,threadLocal Ref 被回收,但是 threadLocalMap 的 Entry 强引用了 threadLocal,造成 threadLocal 无法被回收,无法完全避免内存泄漏

-
如果 key 使用弱引用:使用完 ThreadLocal ,threadLocal Ref 被回收,ThreadLocalMap 只持有 ThreadLocal 的弱引用,所以threadlocal 也可以被回收,此时 Entry 中的 key = null。但没有手动删除这个 Entry 或者 CurrentThread 依然运行,依然存在强引用链,value 不会被回收,而这块 value 永远不会被访问到,也会导致 value 内存泄漏

-
两个主要原因:
- 没有手动删除这个 Entry
- CurrentThread 依然运行
根本原因:ThreadLocalMap 是 Thread的一个属性,生命周期跟 Thread 一样长,如果没有手动删除对应 Entry 就会导致内存泄漏
解决方法:使用完 ThreadLocal 中存储的内容后将它 remove 掉就可以
ThreadLocal 内部解决方法:在 ThreadLocalMap 中的 set/getEntry 方法中,通过线性探测法对 key 进行判断,如果 key 为 null(ThreadLocal 为 null)会对 Entry 进行垃圾回收。所以使用弱引用比强引用多一层保障,就算不调用 remove,也有机会进行 GC
7.2.6 变量传递
基本使用
父子线程:创建子线程的线程是父线程,比如实例中的 main 线程就是父线程
ThreadLocal 中存储的是线程的局部变量,如果想实现线程间局部变量传递可以使用 InheritableThreadLocal 类
1 | public static void main(String[] args) { |
实现原理
1 | public class InheritableThreadLocal<T> extends ThreadLocal<T> { |
实现父子线程间的局部变量共享需要追溯到 Thread 对象的构造方法:
1 | private Thread(ThreadGroup g, Runnable target, String name, |
1 | private ThreadLocalMap(ThreadLocalMap parentMap) { |
参考文章:https://blog.csdn.net/feichitianxia/article/details/110495764
7.2.7 TTL
TransmittableThreadLocal 是 ThreadLocal 的增强版,专门为了解决在异步执行(尤其是使用线程池)场景下,线程上下文信息传递的问题。
| 特性 | ThreadLocal | InheritableThreadLocal | TransmittableThreadLocal (TTL) |
|---|---|---|---|
| 数据隔离级别 | 线程级别 | 线程级别 | 线程级别 |
| 数据传递性 | 不可传递 | 仅在新创建线程时传递 | 支持任意传递(线程池、定时任务等) |
| 核心应用场景 | 同一线程内共享数据(如用户会话) | 父线程创建新子线程时传递数据 | 异步执行,尤其是线程池场景下的上下文传递 |
| 实现原理 | 线程的threadLocals变量 |
线程的inheritableThreadLocals变量 |
通过包装Runnable/Callable,在执行前“快照”数据,执行时“恢复”数据 |
| 与线程池的兼容性 | 不兼容 | 不兼容(因线程复用,而非新建) | 完美兼容 |
核心源码分析
- TransmittableThreadLocal 类
1 | public class TransmittableThreadLocal<T> extends InheritableThreadLocal<T> { |
- TtlRunnable 包装器
1 | public class TtlRunnable implements Runnable { |
工作原理详解
- 注册机制
- 每个
TransmittableThreadLocal实例在调用set()方法时,会自动注册到当前线程的全局holder中 holder是一个WeakHashMap,key 是弱引用,防止内存泄漏- 这样系统可以跟踪所有需要传递的 TTL 变量
- 捕获阶段(Capture)
当创建 TtlRunnable 时:
1 | // 捕获当前线程所有 TTL 的值 |
这个过程:
-
遍历
holder中注册的所有 TTL 实例 -
调用每个 TTL 的
copyValue()方法获取当前值 -
生成一个包含所有 TTL 键值对的快照
- 回放阶段(Replay)
当任务在工作线程执行时:
1 | Map<TransmittableThreadLocal<?>, Object> backup = TransmittableThreadLocal.replay(captured); |
这个过程:
-
备份:先备份工作线程当前的 TTL 值
-
清理:清除工作线程的所有 TTL 值
-
设置:将捕获的快照设置到工作线程的 TTL 中
-
恢复阶段(Restore)
任务执行完成后:
1 | TransmittableThreadLocal.restore(backup); |
这个过程:
- 清除任务执行期间设置的 TTL 值
- 恢复工作线程执行任务前的原始 TTL 值
- 保证不会污染后续任务
内存管理机制
- 弱引用使用
1 | private static final InheritableThreadLocal<Map<TransmittableThreadLocal<?>, ?>> holder = |
WeakHashMap的 key 是弱引用,当 TTL 实例没有强引用时会被 GC 回收- 防止因为全局注册导致的内存泄漏
- 值拷贝策略
TTL 提供了三种值拷贝策略:
1 | public class TransmittableThreadLocal<T> { |
与 Agent 方式的集成
TTL 还提供了 Java Agent 方式,通过字节码增强自动包装:
1 | // 通过 Agent,以下代码会自动被增强 |
Agent 的工作原理:
- 在类加载时,通过字节码增强技术修改
Runnable/Callable的实例化代码 - 自动将其包装为
TtlRunnable/TtlCallable - 实现代码无侵入的上下文传递
总结
TTL 的核心原理可以概括为:
- 注册跟踪:通过全局
holder跟踪所有 TTL 实例 - 快照捕获:在任务提交时捕获父线程的 TTL 值快照
- 上下文切换:通过 replay/restore 机制在工作线程中切换上下文
- 内存安全:使用弱引用和清理机制防止内存泄漏
- 无缝集成:通过包装器或 Agent 实现与现有代码的无缝集成
这种设计既保证了线程池环境下上下文传递的正确性,又避免了线程污染,是现代异步编程中上下文传递的优雅解决方案。
7.3 JUC
7.3.1 AQS原理
概述
全称是 AbstractQueuedSynchronizer,是阻塞式锁和相关的同步器工具的框架,许多同步类实现都依赖于该同步器
特点:
- 用 state 属性来表示资源的状态(分独占模式和共享模式),子类需要定义如何维护这个状态,控制如何获取锁和释放锁
- getState - 获取 state 状态
- setState - 设置 state 状态
- compareAndSetState - cas 机制设置 state 状态
- 独占模式是只有一个线程能够访问资源,而共享模式可以允许多个线程访问资源
- 提供了基于 FIFO 的等待队列,类似于 Monitor 的 EntryList
- 条件变量来实现等待、唤醒机制,支持多个条件变量,类似于 Monitor 的 WaitSet
官方文档说明
To use this class as the basis of a synchronizer, redefine the following methods, as applicable, by inspecting and/or modifying the synchronization state using getState, setState and/or compareAndSetState:
- tryAcquire
- tryRelease
- tryAcquireShared
- tryReleaseShared
- isHeldExclusively
意思是我们只需要重写AQS的这几个方法,并且通过AQS提供的getState, setState and/or compareAndSetState这几个方法对状态变量进行修改,就能达到想要的各种效果。总而言之,资源数(状态变量)是由子类来维护的。
看一下官方文档给出的使用AQS实现不可重入互斥锁的例子就明白了,这里定义状态为1表示锁被占用,0表示锁空闲:
1 | public class Mutex implements Lock, Serializable { |
首先AQS的子类通常作为 基于AQS的同步/互斥工具类 的私有静态内部类,这里是Sync类,然后再声明一个Sync类型的变量供Mutex使用,而不是直接继承AQS。
然后看到Sync重写AQS的几个方法:
- tryAcquire:通过CAS将状态设为1(占有锁),成功的话设置当前线程为持有锁的线程,否则返回false表示失败
- tryRelease:检查当前线程不是占有锁的线程的话,直接抛异常。否则将状态设为0(释放锁)
- isHeldExclusively:检查当前线程是否持有当前锁的线程
另外因为这里Mutex是独占锁而不是共享锁,因此不用实现
- tryAcquireShared
- tryReleaseShared
然后Mutex就可以用Sync(AQS)提供的方法来实现lock、unlock等操作了,整个Mutex的代码十分简单,大部分活AQS都帮我们干了。而且那么多同步工具类都依赖于AQS,足以说明了AQS提供了很多的功能,十分强大,下面将进行分析。
CLH锁
上网一搜AQS解析,必定离不开CLH锁。CLH作为AQS阻塞队列的节点,一个线程绑定一个节点。注意只有发生竞争锁时才会有节点入队。比如只有单线程获取锁的话,根本不会阻塞,更没有竞争锁。
下面的梳理是基于AQS源码中CLH Nodes的Overview注释进行
CLH单个节点的成员变量很好理解
1 | abstract static class Node { |
节点状态
1 | // Node status bits, also used as argument and return values |
下面看一下CLH队列的结构。
首先CLH队列永远会有一个dummy node作为头节点并用变量head保存,当然,dummy node是懒初始化的,也就是在入队第一个节点的时候才会被初始化。下图是初始化了dummy node后的状态,tail变量指向队尾节点。
+-------+ +------+ | | | | | head | <---- | tail | |(dummy)| | | +-------+ +------+
当第一个节点first入队后的状态图如下:
+-------+ prev +-------+ +------+ | | <---- | | | | | head | | first | <---- | tail | |(dummy)| ----> | | | | +-------+ next +-------+ +------+
这部分对应的代码如下,第一次循环懒初始化dummy(如果还没初始化的话),第二次才入队:
1 | private void tryInitializeHead() { |
接下来是唤醒操作(signalling),AQS采取一种像Dekker算法那样的策略:尝试获取资源的线程不断尝试获取锁,自旋结束还获取不到的话,就park睡眠,直到被释放锁的线程清除WAITING状态并用unpark唤醒,然后重复上述步骤。
AQS内部节点

1 | /** |
独占节点
1 | static final class ExclusiveNode extends Node { } |
共享节点
1 | static final class SharedNode extends Node { } |
条件变量节点
1 | static final class ConditionNode extends Node |
从大段注释到代码一路读下来,第一个遇到的核心函数是
acquire
这个函数的功能是,尝试通过tryAcquire获取锁,自旋数次获取不到之后,就主动调用park进入阻塞状态。如果某次tryAcquire成功则返回正数,被中断则返回负数,超时返回0。
先看下函数签名以及对应参数含义:
1 | final int acquire(Node node, int arg, boolean shared, boolean interruptible, boolean timed, long time) |
- node:只有在条件变量中acquire才会传入
- arg:用户自定义参数,最终会传给tryAquire/tryAcquireShared
- shared:是否共享模式的acquire
- interruptible:如果为true,那么在中断后返回负数
- timed:是否有限等待
- time:有限等待时长,单位是纳秒
为了简单起见但是又不失根据地分析代码,我们注意到在之前Mutex例子中的lock方法中直接调用的是acquire(1),因此从这个调用入手去分析理解,并且Mutex对应的是独占模式,因此下面先暂时忽略共享模式的代码。
我们分析最简单的情况:只有一个线程尝试去获取已经被其他线程占用的锁,即对tryAcquire的调用通通返回false
1 | public final void acquire(int arg) { |
这个acquire的重载首先调用了tryAcquire(这个函数在Mutex示例中有,是由子类自定义的尝试获取锁的方法),如果尝试获取失败的话,再调用acquire。实际上acquire里也会数次调用tryAcquire
然后进入acquire(null, arg, false, false, false, 0L)
1 | Thread current = Thread.currentThread(); |
- current:当前线程
- spins:下次唤醒后的最大自旋次数
- postSpins:暂存最大自旋次数
- interrupted:记录线程是否被中断
- first:node是否为第一个有效节点(即是否为head.next指向的节点)
- node:当前线程所绑定的节点
最外边是一个无限for循环,这个写法在之前enqueue方法里也见过,其实非常常见:循环里写了很多 if 分支根据当前的运行状态选择不同的处理逻辑。比如在enqueue方法中,首次循环时tail还没初始化(状态1)先去初始化tail,第二次循环时tail已经初始化(状态2),此时将节点入队。明白了这个写法之后,就不会被下面一堆的 if 弄乱了。
首先看第一块 if:
分支1:
1 | if (!first && (pred = (node == null) ? null : node.prev) != null && !(first = (head == pred))) { |
这个代码块主要用于清理已经被取消的前驱节点,目的是让node尽量往队头靠,最好变成第一个有效节点,这样就有机会去获取锁了。这个if语句包含三个条件,使用逻辑与(&&)连接:
!first:检查当前节点是否不是队列的第一个节点(即不是head节点)(pred = (node == null) ? null : node.prev) != null
- 如果node为null,则pred赋值为null
- 如果node不为null,则pred赋值为node的前驱节点
- 然后检查pred是否不为null
!(first = (head == pred))
- 检查pred是否等于head节点
- 将比较结果赋值给first变量
- 然后对first取反
整体来说,这个if语句判断的是:
- 当前节点不是第一个节点,并且
- 当前节点有前驱节点,并且
- 前驱节点不是head节点
换句话说,这个条件成立时,表示当前节点既不是队列的第一个有效节点,其前驱也不是head节点。这种情况下,代码会进一步检查前驱节点的状态:
- 如果前驱节点已取消(
pred.status < 0),则调用cleanQueue()清除被取消的节点,然后重新循环。 - 如果前驱节点没有前驱,节点是第一个有效节点(
pred.prev == null),则调用Thread.onSpinWait()进行短暂等待,确保操作的串行化,而后重新开始循环。如果走到这一步的话,说明在它之前的节点在别的线程中被清理了,当前节点变成了第一个有效节点。
下面看第二块 if:
分支2:
1 | if (first || pred == null) { |
这个if语句包含两个条件,使用逻辑或(||)连接:
first:检查当前节点是否是队列的第一个节点(即head节点)pred == null:检查前驱节点是否为null
整体来说,这个if语句判断的是:
- 当前节点是队列的第一个节点,或者
- 当前节点没有前驱节点(pred为null)
这种情况通常出现在以下场景:
- 当前线程已经是队列的第一个有效节点
- 当前线程是第一个尝试获取锁的线程,还没有前驱节点
当这个条件成立时,代码会尝试直接获取锁(而不需要排队等待):
- 如果是共享模式,调用
tryAcquireShared(arg) >= 0尝试获取 - 如果是独占模式,调用
tryAcquire(arg)尝试获取
如果获取成功,且当前节点确实是第一个节点,还会更新队列头部并进行清理工作,并返回一个正数表示获取成功。
否则,如果上一步tryAcquire不成功,那么继续往下走。
下面是一个大的if-else if-else体,每个分支对应不同的处理逻辑:
分支3:
if (node == null):如果当前节点为 null,说明这是线程第一次尝试获取资源,需要根据是共享模式还是独占模式创建相应的节点(SharedNode 或 ExclusiveNode)。
分支4:
else if (pred == null):如果当前节点不为 null 但前驱节点为 null,说明节点尚未入队,需要尝试将节点加入等待队列。具体步骤包括:
- 设置节点的
waiter字段为当前线程。 - 获取当前尾节点
t。 - 使用
setPrevRelaxed方法设置当前节点的前驱节点。 - 如果尾节点为
null,说明队列尚未初始化,调用tryInitializeHead初始化队列头。 - 否则尝试通过 CAS 操作将当前节点设置为新的尾节点,如果失败则清除前驱节点引用。
分支5:
else if (first && spins != 0):如果当前节点是队列中的第一个节点且还有自旋次数,则减少自旋次数并调用 Thread.onSpinWait() 让线程短暂等待,以减少在重新尝试获取资源时的不公平性。
分支6:
else if (node.status == 0):如果节点的状态为 0(初始状态),则将其状态设置为 WAITING,表示节点正在等待被唤醒,并重新检查条件。到这一步的话,说明自旋次数用完了还没获取到锁,需要准备阻塞了,不然浪费CPU资源,很明显在设置完这个状态之后还会去挣扎一次tryAcquire。
分支7:
else:如果以上条件都不满足,说明节点已经在队列中且处于等待状态,线程需要被阻塞。真正开始阻塞节点对应的线程,阻塞之前增加节点下次唤醒后的最大自旋次数。被唤醒之后,清除阻塞ing的状态,如果被中断的话则退出循环,具体操作包括:
- 设置自旋和后续自旋次数。
- 根据是否设置了超时时间选择调用
LockSupport.park或LockSupport.parkNanos阻塞线程。 - 清除节点状态。
- 检查线程是否被中断,如果中断且可中断则跳出循环。
循环结束后只有一句:
1 | return cancelAcquire(node, interrupted, interruptible); |
cancelAcquire用于清理acquire失败的节点,只有两种情况会被调用:
- tryAcquire抛出异常(对应分支2中的异常处理)
- 超时或者被中断(对应分支7的两个break)
1 | private int cancelAcquire(Node node, boolean interrupted, boolean interruptible) { |
acquire总结
acquire完成的功能其实就是不断自旋获取锁,获取不到就阻塞,醒来后继续自旋,然后阻塞,如此往复。为了实现公平的特性(FIFO),队列中只有第一个有效节点才会去tryAcquire,并且是多次tryAcquire,比如在还没生成节点前会tryAcquire一次,阻塞前tryAcquire至少一次,唤醒后会tryAcquire一次。
一些疑问点:
-
为什么第一个有效节点被正常唤醒后(非超时/中断)却还有可能获取不到锁,不是FIFO的吗?
因为唤醒之后到重新获取锁这段时间内,可能有其它根本不在队列中的线程这个时候tryAcquire抢先拿到了锁。从这个角度看,AQS的FIFO公平性只是针对在队列中的线程来说的。因此AQS采取了线程唤醒后增加最大自旋次数来提高公平性(对应的分支5也有一句源代码注释
reduce unfairness on rewaits)。并且我个人定义了三种公平性:- 不公平:只要锁不被占用,任何线程都有机会获得锁
- 弱公平:等待队列中的线程是公平的,符合FIFO。而不在等候队列中的可能会直接获得锁而不用进队列
- 强公平:只要等待队列中有正在排队的线程,新来的线程必会加锁失败,消除了弱公平中“插队”的情况
很明显AQS实现的是弱公平,而基于AQS的ReentrantLock进一步实现了强公平。
cleanQueue
根据doc可知,cleanQueue有两个作用;
- 从tail开始遍历队列,清除已取消的节点
- 唤醒那些新成为队头的节点去获得锁(与dummy节点区分开来,这里指的是head.next)
1 | private void cleanQueue() { |
代码用了两层循环,外部那层用于当队列结构改变的时候,重新开始遍历,因此重点在于内层循环。先来看内循环第一行:
1 | for (Node q = tail, s = null, p, n;;) { // (p, q, s) triples |
一上来先定义四个让人直呼acm高手的变量名,分别是q s p n,并且后面注释(p, q, s) triples 三元组,再联系下面的代码大概可以猜到这四个变量分别代表:
- q:当前节点
- s:q的后继节点successor
- p:q的前驱节点predecessor
- n:临时的后继节点next
明白变量的含义之后,接着看下去:
1 | if (q == null || (p = q.prev) == null) |
如果队列没有节点了,或者当前节点是第一个节点(dummy节点)则已处理完毕。这是唯一的函数出口。在这之后的代码都保证了q和p不为
1 | if (s == null ? tail != q : (s.prev != q || s.status < 0)) |
- 后继为空:tail != q的话,说明有其他线程修改了tail,队列结构改变,因此直接break然后重新开始遍历。
- 后继不为空:后继的前驱不是q(也就是q的后继的前驱不是q的话,说明s已经不再是q的后继)或者后继已经被取消(s是已经被处理过的节点,这个函数就是要清除已取消的节点,因此得重新开始遍历,去处理这个s)的话,也说明队列结构改变了,直接break。
1 | if (q.status < 0) { // cancelled |
到此终于来到了处理节点的代码,根据常量的定义,status<0 代表节点已被取消(最高位为1的int类型必然是负数):
1 | // Node status bits, also used as argument and return values |
首先还是根据后继是否为空分情况讨论:
- 后继为空:直接将tail指向前驱节点
- 后继不为空:将后继的前驱指向q的前驱
上述两种情况用的都是CAS操作,在赋值的同时检测了队列结构是否改变(这里称CAS为testAndSet更合理),如果队列结构改变的话返回false,这样就可以直接break重新开始遍历了。
设置成功后将p.next设成s,至此从结构上已经完成了将节点q从队列删除(学过双链表就不难脑补出来)。
然后最后一个if判断,如果p是第一个节点的话,说明p是dummy节点,而原先的第一个有效节点(dummy.next)已经被删除,下一个节点成为了第一个有效节点,此时它可以去获取锁,所以调用signalNext唤醒它。
由于删除q是否成功都意味着队列结构的改变,因此最后break重新开始遍历。
1 | if ((n = p.next) != q) { // help finish |
这里检测p.next是否指向q(q的前驱的后继是否是q),如果是的话,说明队列结构没被改变继续处理,否则进入下一步判断:
如果n(p当前的后继)不是null,并且当前q的前驱为p,说明当前为这样的状态:

会出现这样的状态是因为并发导致p.next被其他线程所修改,后面将p.next强行恢复为指向q即可。然后检测如果第一个有效节点发生改变(检测到p是dummy),那么则唤醒这个节点去获得锁。最后也是由于队列结构改变直接break。
1 | s = q; |
这是最后两行代码,走到这里也就说明本次循环没有找到已取消的节点,队列结构也没发生改变,因此往head方向继续遍历。
总之cleanQueue核心功能就是用来清理一些已取消的节点,**期间可能会出现这样的情况:已经被遍历过的节点被取消了,但是没有被发现(q已经差不多前进到head了),因此本次cleanQueue不会被清除。**这种情况是正常的,可以类比GC,节点的清除是批量的,不是一被取消就会被清除的,可以提高性能,没删除的节点可以等下一批删除。
cancelAcquire
1 | private int cancelAcquire(Node node, boolean interrupted, boolean interruptible) { |
release
1 | //独占锁 |
尝试释放锁,释放成功后再唤醒队列第一个等待的节点去获得锁。
hasQueuedPredecessors
1 | //是否有前驱节点在同步队列里,有说明等待队列里有其他线程正在获取锁,或者队列里就只有当前线程或者队列为空均返回false |
内部类ConditionObject
到此,AQS还剩共享模式以及ConditionObject没分析。至于AQS其他的方法,经过前面的分析理解阻塞队列的结构以及行为之后就不难读懂了。下面直接看ConditionObject。
AQS还提供了内部类ConditionObject,实现了Condition接口,作为基于AQS的锁的条件变量,使得线程可以阻塞在不同的队列中。

条件变量无非就是await和signal
- await:释放锁并阻塞在等待队列上,等待被signal,唤醒后会自动再次获取锁
- signal:唤醒被阻塞在等待队列上的线程
signal比较简单,先看signal:
1 | public final void signal() { |
可以看到不是随便一个线程都能调用signal的,必须要拥有独占锁的线程才能用signal唤醒其他线程。signal通过doSignal这个方法实现:
1 | /** |
doSignal很简单,只干了一件事,或者说signal只干了一件事:将节点从条件变量队列摘下来,重新入队到AQS队列。
接下来再看看await方法,另外里面有一个enableWait方法比较重要,先看这个enableWait:
1 | /** |
setStatusRelaxed 方法的作用是设置当前节点的状态值。它通过 U.putInt(this, STATUS, s) 直接修改节点的状态字段,而不使用任何内存屏障(memory barrier),这通常用于节点尚未入队时的状态设置,以避免不必要的内存同步开销。
结合注释可以知道,enableWait的功能是将该线程对应的节点加入条件变量的等待队列,并释放其对应的锁。注意这句:
1 | int savedState = getState(); |
最直观的理解就是当前线程占有的资源数是state,因此当释放资源(释放锁)时,要全部释放,当其被唤醒时,要恢复其所拥有的资源,因此将savedState返回给await方法,让其在acquire时作为参数传进去。
下面再来看await方法:
1 | public final void await() throws InterruptedException { |
await流程如下:
- 生成线程对应的节点
- 将节点加入条件变量的等待队列,并释放其对应的锁
- 不断调用canReacquire,通过节点在不在AQS队列中获知线程有没有被signal,如果不在的话就继续阻塞线程
- 当线程被signal或者被中断后退出循环,并重新尝试获得锁
- 最后处理中断
await需要注意的地方也不少:
- 阻塞线程有两种方式,node.block()和ForkJoinPool.managedBlock(node)。后者使用ForkPoolManager管理。
- 无论是被signal还是被中断,await返回之前都会再次调用acquire获取锁,并且注意到参数interruptable=false,说明即使await是可中断的,但前提是得获取到锁才能返回。Condition.await方法的接口文档也说明了这一点:When the thread returns it is guaranteed to hold this lock
- while循环里的else分支啥也没干,因此相当于自旋,之前说过这种情况下调用Thread.onSpinWait有利于优化运行。
共享模式
上面的分析全都忽略了共享模式,在这里简单补充一下:
可以不严谨地说,共享与否还是与资源数(状态变量)有关,资源数大于1就相当于是共享的,比如资源数=2并且每个线程每次只获取一个资源时,那么最多就会同时有两个线程成功获取到资源,相当于共享资源。由于在共享模式下,“获取资源”这个叫法更加符合语意,下面我不会称tryAcquireShared为“获取锁”,而是“获取资源”
首先从acquireShared方法开始:
1 | public final void acquireShared(int arg) { |
首先用tryAcquireShared尝试获取资源,返回资源数如果是负数说明资源不够本次获取,那么就调用acquire,并且shared参数传入true(acquire函数上面已经详细分析过)。看一下acquire里跟shared有关的代码。
第一个跟shared有关的地方是分支2中的:
1 | if (shared) |
这块就是类似独占模式下的用tryAcquire获取锁,使用tryAcquireShared再次尝试获取资源,没什么好说的。
第二个跟shared有关的地方依然在分支2中,当获取资源成功后需要唤醒一个后继节点(即唤醒队列中,移除当前节点后,新成为队头的节点)
1 | if (shared) |
为什么这里要唤醒后继节点,而独占模式下却不用唤醒?例:当前线程(队头节点)需要2个资源,后继节点需要3个资源,并且都阻塞在队列中(当前资源数为-1),这时某个线程释放了10个资源,那么当前线程会被唤醒并且获取资源成功,由于资源足够,下一个线程也得被唤醒并去获取资源。
反之,如果是独占模式,当前线程获取到锁后,都说了是独占的,肯定就没后面的线程什么事了,因此不用唤醒。
第三个跟shared有关地方是分支3中的生成节点:
1 | if (shared) |
注意到ShareNode和ExclusiveNode都只是简单继承于Node,没有重写或添加任何的额外成员,目的是通过判断节点类型来判断节点是否共享模式。
唤醒所有被Condition阻塞的线程
1 | public final void signalAll() { |
可中断的等待
1 | public final void awaitUninterruptibly() { |
总之,AQS的核心思想就是使用了FIFO等待队列来记录被阻塞的线程,每次只有队头线程有机会被唤醒,处于唤醒状态的线程会数次自旋尝试获取锁,获取不到再继续阻塞。以上对线程的阻塞和唤醒借助了LockSupport工具类提供的park和unpark原语实现对线程进行精准阻塞和唤醒。
阅读AQS的源码不是一蹴而就就能完全读懂的,阅读源码大致分为三步:
- 读懂大概思路以及一些重要方法之间的调用关系
- 逐行看代码的具体实现,知道每一段代码是干什么的
- 琢磨参悟某一段代码为什么是这么写的,能否换一种写法,能否前后几行代码调换顺序,作者是怎么想的
读AQS最难的地方不在于明白套路和思路,而在于代码中点点滴滴的细节。从一行行的代码角度来说,比如改一个值,是否需要CAS,是否一定要CAS成功;读一个值,在多线程环境下含义是什么,有哪些种情况。从一个个方法角度来说,这些方法的调用关系是如何保证框架的正确性、鲁棒性、伸缩性等。
如果能把这些细节都想清楚,明白作者的思路与考虑,才可以源码理解入木三分了。
主要用到 AQS 的并发工具类

参考链接
「CSDN」Jdk17 AQS cleanQueue方法源码分析
「博客园」AbstractQueuedSynchronizer源码解读
AbstractQueuedSynchronizer源码阅读
7.3.2 ReentrantLock

ReentrantLock 的底层实现是高度依赖 AQS 的,这一点从源码中就可以看得出来:
1 | public class ReentrantLock implements Lock, java.io.Serializable { |
ReentrantLock 内部有一个 Sync 类型的对象,Sync 这个类则是继承自 AbstractQueuedSynchronizer,也就是抽象队列同步器,这个锁的同步控制基础就是这个 Sync 提供的,可以注意到这里的 Sync 仍然是抽象类,其实它还有两个子类,分别是 FairSync 和 NonFairSync ,分别对应于公平锁的实现和非公平锁的实现,因此先介绍Sync这个类的核心方法。
Sync.tryLock
1 | final boolean tryLock() { |
Sync.initialTryLock
1 | abstract boolean initialTryLock(); |
Sync.lock
1 | final void lock() { |
Sync.tryRelease
1 | protected final boolean tryRelease(int releases) { |
ReentrantLock 加锁流程
首先是实例化一个 ReentrantLock 锁对象,这里构造函数可带参数,如果参数为 true ,则会实例化一个公平锁,默认为非公平锁,其实区别就在于是实例化了一个 FairSync 对象还是一个 NonFairSync 对象。
1 | // 实例化一个锁 |
之后调用 lock() 方法加锁,其实底层是调用了 sync 对象的 lock() 方法来加锁
1 | public void lock() { |
sync.lock() 的实现如下:
1 | final void lock() { |
这里 initialTryLock() 方法是一个抽象方法,实际上调用的是 Sync 这个类的两个子类 FairSync 和 NonFairSync 重写的 initialTryLock() 方法。
我们先看非公平锁 NonFairSync 的实现:
1 | /** |
非公平锁的 initialTryLock() 方法通过 CAS 尝试加锁(即 compareAndSetState(0, 1)),如果 AQS 的 state 字段为 0 ,则把这个字段变为 1 ,并使用setExclusiveOwnerThread(current); 将独占锁的线程设置为当前线程即自己,否则加锁失败,失败之后会判断当前独占锁的线程是不是当前线程。如果是的话将 state 加一,同样加锁成功,这里就体现了可重入锁的实现,即同一个线程可以多次获取锁而不阻塞,state 字段其实就是这个线程获取锁的次数。如果这两种情况都没有加锁成功,则认为锁被另一个线程独占,加锁失败,返回 false 。
在第一次 CAS 加锁未成功时,会调用 acquire(1) 这个方法,这个方法是 AbstractQueuedSynchronizer 抽象类提供给我们的
1 | public final void acquire(int arg) { |
首先调用 tryAcquire(arg)方法,这里会去调用具体实现类的 tryAcquire() 方法,同样,我们先看非公平锁的实现
1 | protected final boolean tryAcquire(int acquires) { |
这里是尝试了第二次 CAS 加锁,与 initialTryLock() 方法中的逻辑差不多,同样也是做 CAS 尝试,如果成功,将独占这个锁的线程设置为自己,如果不成功则返回 false
如果第二次 CAS 加锁不成功,则调用 acquire(null, arg, false, false, false, 0L) 方法,这个方法极其重要,它的内部定义了线程如何排队来获取锁的逻辑。前面的文章我们已经详细分析过,这里就不再赘述。
解锁也是调用了 sync 对象的 release() 方法,下面是解锁部分的源码:
1 | public void unlock() { |
tryRelease() 方法尝试解锁,如果成功解锁,则调用 signalNext() 方法,唤醒队列中的第一个线程,于是队列中的第一个线程就加入到了获取锁的行列中来。
其实公平锁的实现与非公平锁及其类似,只有一处不同,具体可以看公平锁的源码:
1 | /** |
可以看到,与非公平锁不同的是,在公平锁在决定是否要去抢锁之前会有一个额外的判断,也就是会调用 hasQueuedPredecessors() 方法,这个方法的作用在于判断队列中是否有等待处理的线程,如果没有,当前线程才会去抢锁,如果队列中有线程则无法抢锁,这样就保证了,线程可以按照自己在队列中的顺序公平地获得锁
这个函数在以下两种情况下返回true:
- 当前线程没进入阻塞队列,且队列不为空
- 当前线程已经在阻塞队列中,但前面有更靠近队头(等待时间更长)的线程
这两种情况下都得获取锁失败,以实现强公平。
7.3.3 ReentrantReadWriteLock
ReentrantReadWriteLock是可重入读写锁,所谓可重入锁指的是占有锁的线程继续在这个锁上调用lock直接加锁成功,当然,lock与unlock的调用次数最终数量要相等,否则不会释放锁。而不可重入锁则是lock成功后再lock就会被阻塞。而读写锁分为读锁和写锁,读锁是共享的,写锁是互斥的,可以用一张表来表示:
| 第二个线程此时要获取读锁 | 第二个线程此时要获取写锁 | |
|---|---|---|
| 第一个线程先占有读锁 | 成功 | 失败 |
| 第一个线程先占有写锁 | 失败 | 失败 |
在读多写少的场景下,ReentrantReadWriteLock相比普通的ReentrantLock具有更高的并发量。
使用规则:
-
读-读能共存、读-写不能共存、写-写不能共存
-
读锁不支持条件变量
-
重入时升级不支持:持有读锁的情况下去获取写锁,会导致获取写锁永久等待,需要先释放读锁,再去获得写锁
-
重入时降级支持:持有写锁的情况下去获取读锁,造成只有当前线程会持有读锁,因为写锁会互斥其他的锁
与ReentrantLock类似,ReentrantReadWriteLock也是基于AQS实现的,里面很多方法都是直接写一行sync.XXX,源码主要集中在它的内部类,因此我们直接分析它的内部类即可。
首先ReentrantReadWriteLock继承了ReadWriteLock接口,这个接口只有两个方法:
1 | public interface ReadWriteLock { |
这个接口返回读锁和写锁,ReentrantReadWriteLock本身并不是一个Lock,而是负责将两种Lock封装起来协同工作。然后最重要的就是AQS了,作为实现锁的同步器工具,在这里是继承于AQS的Sync类。两个锁依赖于同步器进行协同工作:
1 | private final ReentrantReadWriteLock.ReadLock readerLock; |
其实想想AQS的原理,就知道这两个Lock必定是依赖于同一个Sync,相当于依赖同一个等待队列。基于这点,我们接下来就先分析私有静态内部类Sync,以及分别对应公平同步器和非公平同步器的两个子类NonFairSync和FairSync。
Sync
state定义
Sync同步器类继承于AQS,并且最核心的是state状态变量的含义,state的含义是由子类Sync来定义的,ReentrantReadWriteLock也为state定义了一套规则:
- state的高16位:所有读锁的重入次数总和
- state的低16位:写锁的重入次数
state是int类型,在Java中int类型已经明确是32位的。由于读锁和写锁是互斥的,所以两者不能共用一个计数器。综上可知,分别用state的高16和低16位作为两个计数器。另外,读锁之间并不互斥,因此高16位统计的是 所有读锁 的重入次数总和。综上,读写重入数的时候需要用到位运算,相关的位运算如下:
1 | static final int SHARED_SHIFT = 16; |
lock count和hold count
lock count指的是所有线程重入次数总和,hold count指的是当前线程的重入次数。由于写锁是独占锁,因此其lock count等于hold count。而读锁之间是共享锁,因此其lock count等于所有读锁的hold count总和。综上:
- writeLockCount = writeHoldCount = state低16位
- readLockCount = 所有线程的readHoldCount = state高16位
Sync.HoldCounter类
HoldCounter是Sync的静态内部类,用于记录单个线程对应的重入数:
1 | static final class HoldCounter { |
这个类很简单,只是用来记录单个线程的重入次数,保存在count成员变量中,用于在释放读锁时检查该线程是否拥有读锁。tid代表对应的线程id。至于为什么不直接引用线程而是记录tid,在注释里已经解释了。
因为可能有多个线程获得了读锁,而state只能记录所有线程的总重入数,因此额外设置这个HoldCounter用来记录单个线程对应的重入数。当谈及“每个线程对应的xxx计数”时,自然就会想到用ThreadLocal来实现这个功能。ThreadLocal用于为每个线程维护独立的对象,实现线程之间的资源隔离,这里所谓的对象就是HoldCount。
1 | static final class ThreadLocalHoldCounter extends ThreadLocal<HoldCounter> { |
Sync.readHolds保存了该ThreadLocal。
1 | private transient ThreadLocalHoldCounter readHolds; |
Sync类其他成员变量
1 | // 保存最后一个获取到读锁的线程的HoldCounter。因为从ThreadLocal获取有一定开销,而释放锁的线程往往是最近获取到锁的那个线程(命中cachedHoldCounter的可能性大),因此缓存下这个HoldCounter以提高性能 |
需要注意这是唯一存了firstReader的重入数的地方,firstReader没有对应的HoldCounter保存在ThreadLocal中。
成员变量都已经说完了,接下来就开始分析Sync类的方法。由于要同时支持读共享锁以及写独占锁,因此Sync要实现AQS的全部五个方法:tryAcquire, tryRelease, trySharedAcquire, trySharedRelease, isHeldExclusively。另外还提供了其他的一些方法比如tryWriteLock, tryReadLock等,提供给外部实现相应功能。
除了以上方法,还有两个抽象方法:
1 | abstract boolean readerShouldBlock(); |
由于ReentrantReadWriteLock支持公平和非公平锁,在尝试加锁之前,公平与否会使得加锁的行为不一样,比如在公平锁的情况下,如果当前等待队列存在等待的线程,那么新来的线程就不能直接尝试加锁,而是让他进入等待队列排队。因此这两个方法返回的结果就是:是否应该进入等待队列等候,而不是直接尝试加读/写锁。
下面开始逐个分析Sync的核心方法。
tryAcquire
1 | protected final boolean tryAcquire(int acquires) { |
tryAcquire功能是尝试获取独占锁(写锁)。有了前面的说明铺垫,这里可以发现整个流程其实十分自然:
- 如果写锁已经被其他线程占有,或者目前处于读锁被占有的状态,那么当前线程获取写锁失败。
- 如果写重入数已经大于最大写重入数,直接抛错误。
- 如果当前线程已经占有了写锁,增加写锁重入数即可。
- 如果锁处于空闲状态,那么通过writerShouldBlock检查是否可以直接尝试加锁,可以的话就CAS尝试加锁。
- 加锁成功后,设置独占线程为当前线程。
tryRelease
1 | protected final boolean tryRelease(int releases) { |
tryRelease功能是尝试释放独占锁(写锁), 流程如下:
- 如果当前线程不持有该独占锁,直接抛异常。
- 如果是当前线程持有锁,则减去重入数。
- 如果减去写锁重入数之后的重入数为0,说明释放了写锁。
- 返回是否已经释放了锁。
tryAcquireShared
1 | protected final int tryAcquireShared(int unused) { |
tryAcquireShared的功能是尝试获取共享锁(读锁)。可以看到共享相关的操作比独占的稍微复杂了些,因为涉及到之前说的HolderCount、ThreadLocal等,还调用了一个名为fullTryAcquireShared的函数,其实也没多复杂。先看一下流程:
-
如果其他线程占有写锁,则失败。
-
检查是否能尝试加锁、读重入数是否达到限制,尝试加锁。
-
如果加锁成功:
- 如果首次加上读锁的线程是当前线程,那么单独维护其重入数
- 如果当前线程不是首次加上读锁的线程,那么通过ThreadLocal维护其可重入数
-
否则如果加锁不成功,进入fullTryAcquireShared
fullTryAcquireShared
1 | final int fullTryAcquireShared(Thread current) { |
所以为什么需要这个函数呢,看着跟tryAcquire很多重合的地方啊。首先在以下两种情况下都应该能成功获得读锁:
- 当前线程已经获得写锁,由于锁降级机制,必定能成功获得读锁
- 当前线程已经获得读锁,由于可重入机制,必定能成功获得读锁
而在tryAcquire函数中,当readerShouldBlock返回true或者CAS失败时不会进入尝试获取锁的步骤,因此tryAcquire是不完整的,只能代表多数的情况(即
并发量小的情况下,readerShouldBlock大多情况会返回false,并且CAS几乎不会失败),因此tryAcquire属于fast-path,而fullTryAcquireShared则
属于slow-path(比如它还得查询HoldCount),实现了在上面两种规则下一定能获得锁的功能。
tryReleaseShared
1 | protected final boolean tryReleaseShared(int unused) { |
tryReleaseShared的功能是释放共享锁。这部分比较简单,直接看注释就行。
还有一个有意思的点就是tryAcquireShared和tryReleaseShared的参数都是unused的,代码中确实也没有使用它,而独占模式的tryAcquire和tryRelease却使用了。其实加读锁和加写锁传入的参数都只会是1,什么时候会传入不是1呢?使用条件变量的时候。比如当前重入数为n,并且在条件变量上await的话,release要传入n,表明线程完全释放锁,重入数直接减到0,并且在唤醒尝试获得锁时要恢复重入数,acquire也需要传入n。而共享锁不支持条件变量,因此共享锁acquire和release传入的一定就是1,可以不用这个参数。
tryWriteLock
1 | final boolean tryWriteLock() { |
tryWriteLock的功能是尝试加写锁,功能上来说与tryAcquire一样,但不考虑writerShouldBlock,即直接是非公平的。整体比较简单,看注释就行。
tryReadLock
1 | final boolean tryReadLock() { |
tryReadLock的功能是尝试加读锁,功能上来说与tryAcquireShared一样,但不考虑readerShouldBlock,即直接是非公平的。类似fullTryAcquireShared,由于CAS可能失败,因此需要for循环自旋
为了实现读写锁的功能,Sync定义了state的高低16位分别作为读锁和写锁重入数,并且整个加锁和解锁过程都是围绕state来进行的。复杂点在于共享锁的实现,因为涉及到CAS可能加锁失败、ThreadLocal分别保存每个线程的重入数、firstReader和cachedHoldCounter的维护以加速重入数的获取。不过复杂之处也就止步于此,原理上还是比较简单的。至于锁降级机制,实现起来也没什么特别的技巧,只需要判断如果是当前线程获取了写锁,继续去执行正常的获取读锁流程就行了。
NonFairSync和FairSync
公平与否的区别是尝试加锁之前是否检查等待队列中有比当前线程等待时间更久的线程,并且Sync类通过模板模式(先在抽象类定义抽象方法,以供抽象类的其他方法调用,抽象方法的实现下放给子类来做)定义了抽象方法xxxShouldBlock交给子类实现,以区分公平与非公平。
NonFairSync
1 | static final class NonfairSync extends Sync { |
非公平同步器很简单,无论如何都直接尝试获得锁,因此两个shouldBlock都应该返回false表示可以直接去尝试获得锁。但可以发现readerShouldBlock没有直接返false,而是返回apparentlyFirstQueuedIsExclusive(),这个函数是AQS提供的,来看看这个函数做了什么:
1 | final boolean apparentlyFirstQueuedIsExclusive() { |
apparentlyFirstQueuedIsExclusive用于检查队列中第一个等待节点是否是独占模式(写锁)的节点。
FairSync
1 | static final class FairSync extends Sync { |
公平锁就不用说了,hasQueuedPredecessors是AQS提供的方法:这个函数在以下两种情况下返回true:
- 当前线程没进入阻塞队列,且队列不为空
- 当前线程已经在阻塞队列中,但前面有更靠近队头(等待时间更长)的线程
这两种情况下都说明有比当前线程等待时间更久的线程,因此获取锁失败,以实现强公平。
ReadLock
1 | public static class ReadLock implements Lock, java.io.Serializable { |
WriteLock
1 | public static class WriteLock implements Lock, java.io.Serializable { |
7.3.4 Semaphore
semaphore翻译过来即信号量,对semaphore最直观的解释就是,信号量是一个令牌桶,如果桶里的令牌数>=线程想要获取的令牌数,那么线程就能获取到令牌,然后继续执行,否则就要阻塞等待其他线程将令牌放入桶里,直到桶里令牌数足够。
不像JUC里的Lock,线程只能释放自己获得的锁,即Lock有owner的概念,不能随便释放其他人的锁。而semaphore中令牌没有owner的概念,任何线程都能随意往桶里放令牌。
成员变量
1 | public class Semaphore implements java.io.Serializable { |
成员变量非常简单只有一个,看到Sync就该知道这个是AQS了。信号量还支持fairness,因此Sync作为抽象基类,实现了NonFairSync和FairSync。
方法
Sync继承自AQS,state定义为桶中令牌数量。由于可能同时有多个线程获得令牌,自然需要重写AQS的两个方法:
- tryAcquireShared
- tryReleaseShared
在tryAcquire这里需要区分公平与否,在之前的文章说过,公平的tryAcquire通过检查是否有前驱等待者,即下面两个条件满足一个都属于有前驱等待者,那么就直接tryAcquire失败:
- 当前线程没进入阻塞队列,且队列不为空
- 当前线程已经在阻塞队列中,但前面有更靠近队头(等待时间更长)的线程
否则如果是非公平的,就直接尝试更改state即可。
1 | abstract static class Sync extends AbstractQueuedSynchronizer { |
NonFairSync
1 | static final class NonfairSync extends Sync { |
FairSync
1 | static final class FairSync extends Sync { |
7.3.5 StampedLock
StampedLock:读写锁,该类自 JDK 8 加入,是为了进一步优化读性能
特点:
-
在使用读锁、写锁时都必须配合戳使用
-
StampedLock 不支持条件变量
-
StampedLock 不支持重入
基本用法
-
加解读锁:
1
2long stamp = lock.readLock();
lock.unlockRead(stamp); // 类似于 unpark,解指定的锁 -
加解写锁:
1
2long stamp = lock.writeLock();
lock.unlockWrite(stamp); -
乐观读,StampedLock 支持
tryOptimisticRead()方法,读取完毕后做一次戳校验,如果校验通过,表示这期间没有其他线程的写操作,数据可以安全使用,如果校验没通过,需要重新获取读锁,保证数据一致性1
2
3
4
5long stamp = lock.tryOptimisticRead();
// 验戳
if(!lock.validate(stamp)){
// 锁升级
}
提供一个数据容器类内部分别使用读锁保护数据的 read() 方法,写锁保护数据的 write() 方法:
- 读-读可以优化
- 读-写优化读,补加读锁
1 | public static void main(String[] args) throws InterruptedException { |
7.3.6 CountDownLatch
CountDownLatch:计数器,用来进行线程同步协作,等待所有线程完成
构造器:
public CountDownLatch(int count):初始化唤醒需要的 down 几步
常用API:
public void await():让当前线程等待,必须 down 完初始化的数字才可以被唤醒,否则进入无限等待public void countDown():计数器进行减 1(down 1)
应用:同步等待多个 Rest 远程调用结束
1 | // LOL 10人进入游戏倒计时 |
阻塞等待:
-
线程调用 await() 等待其他线程完成任务:支持打断
1
2
3public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}1
2
3
4
5
6
7
8// AbstractQueuedSynchronizer#acquireSharedInterruptibly
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted() ||
(tryAcquireShared(arg) < 0 &&
acquire(null, arg, true, true, false, 0L) < 0))
throw new InterruptedException();
}1
2
3
4// CountDownLatch.Sync#tryAcquireShared
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
计数减一:
-
线程进入 countDown() 完成计数器减一(释放锁)的操作
1
2
3public void countDown() {
sync.releaseShared(1);
}1
2
3
4
5
6
7public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
signalNext(head);
return true;
}
return false;
} -
更新 state 值,每调用一次,state 值减一,当 state -1 正好为 0 时,返回 true
1
2
3
4
5
6
7
8
9
10
11
12
13protected boolean tryReleaseShared(int releases) {
for (;;) {
int c = getState();
// 条件成立说明前面【已经有线程触发唤醒操作】了,这里返回 false
if (c == 0)
return false;
// 计数器减一
int nextc = c-1;
if (compareAndSetState(c, nextc))
// 计数器为 0 时返回 true
return nextc == 0;
}
} -
state = 0 时,当前线程需要执行唤醒阻塞节点的任务
7.3.7 CyclicBarrier
CyclicBarrier:循环屏障,用来进行线程协作,等待线程满足某个计数,才能触发自己执行
常用方法:
public CyclicBarrier(int parties, Runnable barrierAction):用于在线程到达屏障 parties 时,执行 barrierAction- parties:代表多少个线程到达屏障开始触发线程任务
- barrierAction:线程任务
public int await():线程调用 await 方法通知 CyclicBarrier 本线程已经到达屏障
说起CyclicBarrier不得不提一下CountDownLatch,他们最明显的区别就是:
- CountDownLatch:将线程分为执行者和等待者
- CyclicBarrier:执行者和等待者都是同一批线程
如何理解呢,CountDownLatch大家都知道,设置一批工作线程,各自执行完任务就调用CountDownLatch.countDown,表示自己已经执行完任务,该工作线程就可以继续干别的
事情了。而CyclicBarrier相当于在CountDownLatch.countDown之后设置了一道屏障,自己完成了任务后,还要等别的工作线程也完成了之后才能继续干别的事情。
实际上CountDownLatch就能简单实现一个CyclicBarrier的核心功能:
1 | // 这两句由同一个线程执行 |
就是这么简单,在countDown后加个await就行,相当于执行者和等待者都是同一个线程罢了。在我看来CyclicBarrier只是将两条语句合成了一句:barrier.await()。
当然,CyclicBarrier还支持了其他的更加完善的机制:
- 复用:不同于CountDownLatch只能用一次,每次count减到0后就不能再加回来了。CyclicBarrier可以复用,支持多轮等待
- barrierAction:创建CyclicBarrier时可以传入一个Runnable作为barrierAction,在最后一个线程到达(await)时,由该线程执行该barrierAction,执行完毕之后,所有线程才能被唤醒继续执行
- breakage:如果在最后一个线程到达之前,正在await的线程因为中断、超时等原因退出了(相当于await提前返回了),那么其他所有正在await的线程都将收到BrokenBarrierException异常。注意barrierAction抛异常的话也会造成BrokenBarrierException。如果BrokenBarrierException一旦抛出,除非reset,否则该轮一直处于未完成状态,并且处于breakage状态无法使用。
注意barrierAction在最后一个到达的线程await时才执行,执行完毕后所有线程的await才会返回。假如不需要“执行完毕后所有线程的await才会返回”,你只希望在最后一个到达的线程await后所有线程马上得到释放(并且希望action依然由最后一个到达的线程执行),可以这么做:
1 | if (barrier.await() == 0) { |
await返回当前线程是第几个到达的线程,0代表最后一个到达(n-1代表第一个, n-2代表第2个…)。
最后,对于breakage发生后的reset,文档建议最好重新new一个CyclicBarrier,而不是reset。首先肯定只能由其中一个线程来reset,既然大家都收到了BrokenBarrierException,谁来reset合适?假如选出了负责reset的那个线程,在其reset之前,其他线程都不能await,这里又存在一个线程间同步问题需要解决。综上,发生breakage后,如果还想继续使用CyclicBarrier,重新new一个是比较好的选择。
成员属性
-
全局锁:利用可重入锁实现的工具类
1
2
3
4// barrier 实现是依赖于Condition条件队列,condition 条件队列必须依赖lock才能使用
private final ReentrantLock lock = new ReentrantLock();
// 线程挂起时使用的 condition 队列,当前代所有线程到位,这个条件队列内的线程才会被唤醒
private final Condition trip = lock.newCondition(); -
线程数量:
1
2private final int parties; // 代表多少个线程到达屏障开始触发线程任务
private int count; // 表示当前“代”还有多少个线程未到位,初始值为 parties -
当前代中最后一个线程到位后要执行的事件:
1
private final Runnable barrierCommand;
-
代:
1
2
3
4
5
6
7
8
9// 表示 barrier 对象当前 代
private Generation generation = new Generation();
private static class Generation {
// 表示当前“代”是否被打破,如果被打破再来到这一代的线程 就会直接抛出 BrokenException 异常
// 且在这一代挂起的线程都会被唤醒,然后抛出 BrokerException 异常。
Generation() {} // prevent access constructor creation
boolean broken; // initially false
} -
构造方法:
1
2
3
4
5
6
7
8
9public CyclicBarrie(int parties, Runnable barrierAction) {
// 因为小于等于 0 的 barrier 没有任何意义
if (parties <= 0) throw new IllegalArgumentException();
this.parties = parties;
this.count = parties;
// 可以为 null
this.barrierCommand = barrierAction;
}
成员方法
-
breakBarrier():打破 Barrier 屏障
1
2
3
4
5
6
7
8private void breakBarrier() {
// 将代中的 broken 设置为 true,表示这一代是被打破了,再来到这一代的线程,直接抛出异常
generation.broken = true;
// 重置 count 为 parties
count = parties;
// 将在trip条件队列内挂起的线程全部唤醒,唤醒后的线程会检查当前是否是打破的,然后抛出异常
trip.signalAll();
} -
nextGeneration():开启新的下一代
1
2
3
4
5
6
7
8
9private void nextGeneration() {
// 将在 trip 条件队列内挂起的线程全部唤醒
trip.signalAll();
// 重置 count 为 parties
count = parties;
// 开启新的一代,使用一个新的generation对象,表示新的一代,新的一代和上一代【没有任何关系】
generation = new Generation();
}
-
reset():重置
1
2
3
4
5
6
7
8
9
10public void reset() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
breakBarrier(); // break the current generation
nextGeneration(); // start a new generation
} finally {
lock.unlock();
}
}
-
await():阻塞等待所有线程到位
1
2
3
4
5
6
7public int await() throws InterruptedException, BrokenBarrierException {
try {
return dowait(false, 0L);
} catch (TimeoutException toe) {
throw new Error(toe); // cannot happen
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88// 以下几种情况会使得dowait返回
// 1. 最后一个线程到达,本轮正常结束,以下其他情况都是本轮broken并抛异常
// 2. 本轮已是broken
// 3. 超时
// 4. 中断
// 5. barrierAction抛异常
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
// 加锁
lock.lock();
try {
// 获取当前代
final Generation g = generation;
// 情况2:如果当前代是已经被打破状态,则当前调用await方法的线程,直接抛出Broken异常
if (g.broken)
throw new BrokenBarrierException();
//情况4:如果当前线程被中断了,则打破当前代,然后当前线程抛出中断异常
if (Thread.interrupted()) {
// 设置当前代的状态为 broken 状态,唤醒在 trip 条件队列内的线程
breakBarrier();
throw new InterruptedException();
}
// 逻辑到这说明,当前线程中断状态是 false, 当前代的 broken 为 false(未打破状态)
// 还没到达的线程数-1
int index = --count;
// 条件成立说明当前线程是最后一个到达 barrier 的线程,【需要开启新代,唤醒阻塞线程】
if (index == 0) { // tripped
Runnable command = barrierCommand;
// 执行barrierAction
if (command != null) {
try {
command.run();
} catch (Throwable ex) {
breakBarrier(); //情况5
// 注意,当barrierAction抛出异常,本线程抛出的是barrierAction的异常
// 其他线程抛出的是BrokenBarrierException
throw ex;
}
}
// 执行完毕,本代成功,开始下一代
nextGeneration();
return 0;
}
// loop until tripped, broken, interrupted, or timed out
// 不是最后一个到达的线程
for (;;) {
try {
// 在条件变量上等待
if (!timed)
trip.await();
else if (nanos > 0L)
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie)
// 情况4
// 如果本代未结束
if (g == generation && ! g.broken) {
breakBarrier();
throw ie;
} else {
// We're about to finish waiting even if we had not
// been interrupted, so this interrupt is deemed to
// "belong" to subsequent execution.
// 本代已经结束(已经下一代或者已经broken),那么这个中断应该留给下一代用
Thread.currentThread().interrupt();
}
}
if (g.broken)// 情况2
throw new BrokenBarrierException();
if (g != generation)// 情况1,本轮成功
return index;
if (timed && nanos <= 0L) {
breakBarrier();// 情况3
throw new TimeoutException();
}
}
} finally {
lock.unlock();// 解锁,退出
}
}
8. 并发包
这一章可以视为前面知识的综合应用区域,通常会把前面提到的并发机制落实到 JUC 相关包结构与常见组件上。阅读时建议带着“这个组件解决什么问题、底层依赖什么机制”这两个问题去看。
8.1 线程安全集合类概述

线程安全集合类可以分为三大类:
-
遗留的线程安全集合如
Hashtable,Vector -
使用
Collections装饰的线程安全集合,如:Collections.synchronizedCollectionCollections.synchronizedListCollections.synchronizedMapCollections.synchronizedSetCollections.synchronizedNavigableMapCollections.synchronizedNavigableSetCollections.synchronizedSortedMapCollections.synchronizedSortedSet
说明:以上集合均采用修饰模式设计,将非线程安全的集合包装后,在调用方法时包裹了一层synchronized代码块。其并发性并不比遗留的安全集合好。
-
java.util.concurrent.*
重点介绍java.util.concurrent.* 下的线程安全集合类
-
阻塞队列 (BlockingQueue 接口及其实现)
类名 特点 描述 ArrayBlockingQueue有界阻塞队列 一个由数组支持的有界阻塞队列。需要指定容量,可选择公平性。 LinkedBlockingQueue可选有界/无界队列 基于链表的阻塞队列。默认无界( Integer.MAX_VALUE),也可指定容量。吞吐量通常高于ArrayBlockingQueue。PriorityBlockingQueue无界优先级队列 一个支持优先级排序的无界阻塞队列。元素必须实现 Comparable接口或提供Comparator。DelayQueue无界延迟队列 一个使用优先级队列实现的无界阻塞队列,只有元素的延迟时间到期后,才能从中提取元素。元素必须实现 Delayed接口。SynchronousQueue不存储元素的队列 一个不存储元素的阻塞队列。每个插入操作必须等待另一个线程的对应移除操作,反之亦然。非常适合直接传递场景。 -
写时复制 (Copy-On-Write) 容器
类名 特点 描述 CopyOnWriteArrayList写时复制List 替代同步的 ArrayList。遍历操作很快,且不会抛出ConcurrentModificationException。CopyOnWriteArraySet写时复制Set 基于 CopyOnWriteArrayList的Set实现。 -
非阻塞并发容器 (基于CAS操作)
类名 特点 描述 ConcurrentHashMap高并发HashMap 替代 Hashtable和同步的HashMap。JDK8之前使用锁分段技术,JDK8及之后改为synchronized+ CAS + 红黑树,并发性能极高。不允许null键和null值。ConcurrentSkipListMap高并发有序Map 线程安全的 TreeMap替代品。基于跳表(Skip List)实现,保证键的有序性。ConcurrentSkipListSet高并发有序Set 基于 ConcurrentSkipListMap的线程安全有序Set。ConcurrentLinkedQueue无界非阻塞队列 基于链接节点的无界、线程安全、非阻塞的FIFO队列。使用CAS实现,适合高并发场景。 ConcurrentLinkedDeque无界非阻塞双端队列 与 ConcurrentLinkedQueue类似,但支持从队列两端插入和移除元素。
遍历时如果发生了修改,对于非安全容器来讲,使用 fail-fast 机制也就是让遍历立刻失败,抛出 ConcurrentModificationException,不再继续遍历
集合对比:
- Hashtable 继承 Dictionary 类,HashMap、ConcurrentHashMap 继承 AbstractMap,均实现 Map 接口
- Hashtable 底层是数组 + 链表,JDK8 以后 HashMap 和 ConcurrentHashMap 底层是数组 + 链表 + 红黑树
- HashMap 非线程安全,Hashtable 线程安全,Hashtable 的方法都加了 synchronized 关来确保线程同步
- ConcurrentHashMap、Hashtable 不允许 null 值,HashMap 允许 null 值
- ConcurrentHashMap、HashMap 的初始容量为 16,Hashtable 初始容量为11,填充因子默认都是 0.75,两种 Map 扩容是当前容量翻倍:capacity * 2,Hashtable 扩容时是容量翻倍 + 1:capacity*2 + 1

工作步骤:
-
初始化,使用 cas 来保证并发安全,懒惰初始化 table
-
树化,当 table.length < 64 时,先尝试扩容,超过 64 时,并且 bin.length > 8 时,会将链表树化,树化过程会用 synchronized 锁住链表头
说明:锁住某个槽位的对象头,是一种很好的细粒度的加锁方式,类似 MySQL 中的行锁
-
put,如果该 bin 尚未创建,只需要使用 cas 创建 bin;如果已经有了,锁住链表头进行后续 put 操作,元素添加至 bin 的尾部
-
get,无锁操作仅需要保证可见性,扩容过程中 get 操作拿到的是 ForwardingNode 会让 get 操作在新 table 进行搜索
-
扩容,扩容时以 bin 为单位进行,需要对 bin 进行 synchronized,但这时其它竞争线程也不是无事可做,它们会帮助把其它 bin 进行扩容
-
size,元素个数保存在 baseCount 中,并发时的个数变动保存在 CounterCell[] 当中,最后统计数量时累加
Java7 HashMap

HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。
上图中,每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
loadFactor:负载因子,默认为 0.75。
threshold:扩容的阈值,等于 capacity * loadFactor
put 过程分析
1 | public V put(K key, V value) { |
数组初始化
在第一个元素插入 HashMap 的时候做一次数组的初始化,先确定初始的数组大小,并计算数组扩容的阈值。
1 | private void inflateTable(int toSize) { |
计算具体数组位置
1 | static int indexFor(int hash, int length) { |
添加节点到链表中
找到数组下标后,会先进行 key 判重,如果没有重复,就准备将新值放入到链表的表头。
1 | void addEntry(int hash, K key, V value, int bucketIndex) { |
数组扩容
前面我们看到,在插入新值的时候,如果当前的 size 已经达到了阈值,并且要插入的数组位置上已经有元素,那么就会触发扩容,扩容后,数组大小为原来的 2 倍。
1 | void resize(int newCapacity) { |
扩容就是用一个新的大数组替换原来的小数组,并将原来数组中的值迁移到新的数组中。
由于是双倍扩容,迁移过程中,会将原来 table[i] 中的链表的所有节点,分拆到新的数组的 newTable[i] 和 newTable[i + oldLength] 位置上。如原来数组长度是 16,那么扩容后,原来 table[0] 处的链表中的所有元素会被分配到新数组中 newTable[0] 和 newTable[16] 这两个位置
get 过程分析
相对于 put 过程,get 过程是非常简单的。
- 根据 key 计算 hash 值。
- 找到相应的数组下标:hash & (length - 1)。
- 遍历该数组位置处的链表,直到找到相等(==或equals)的 key。
1 | public V get(Object key) { |
1 | final Entry<K,V> getEntry(Object key) { |
Java8 HashMap
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。
为了降低这部分的开销,在 Java8 中,当链表中的元素达到了 8 个时,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。

Java7 中使用 Entry 来代表每个 HashMap 中的数据节点,Java8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。
我们根据数组元素中,第一个节点数据类型是 Node 还是 TreeNode 来判断该位置下是链表还是红黑树的。
put 过程分析
1 | public V put(K key, V value) { |
和 Java7 稍微有点不一样的地方就是,Java7 是先扩容后插入新值的,Java8 先插值再扩容,不过这个不重要。
数组扩容
resize() 方法用于初始化数组或数组扩容,每次扩容后,容量为原来的 2 倍,并进行数据迁移。
1 | final Node<K,V>[] resize() { |
get 过程分析
相对于 put 来说,get 真的太简单了。
- 计算 key 的 hash 值,根据 hash 值找到对应数组下标: hash & (length-1)
- 判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步
- 判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步
- 遍历链表,直到找到相等(==或equals)的 key
1 | public V get(Object key) { |
1 | final Node<K,V> getNode(int hash, Object key) { |
HashMap的并发死链问题
JDK1.7 的 HashMap 采用的头插法(拉链法)进行节点的添加
resize() 中节点(Entry)转移的源代码:
1 | void transfer(Entry[] newTable, boolean rehash) { |
JDK 8 虽然将扩容算法做了调整,改用了尾插法,但仍不意味着能够在多线程环境下能够安全扩容,还会出现其它问题
-
多线程put的时候,size的个数和真正的个数不一样
-
多线程put的时候,可能会把上一个put的值覆盖掉
-
和其他不支持并发的集合一样,HashMap也采用了fail-fast操作,当多个线程同时put和get的时候,会抛出并发异常
-
当既有get操作,又有扩容操作的时候,有可能数据刚好被扩容换了桶,导致get不到数据
Java7 ConcurrentHashMap
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。
ConcurrentHashMap 对锁粒度进行了优化,分段锁技术,将整张表分成了多个数组(Segment),每个数组又是一个类似 HashMap 数组的结构。允许多个修改操作并发进行,Segment 是一种可重入锁,继承 ReentrantLock,并发时锁住的是每个 Segment,其他 Segment 还是可以操作的,这样不同 Segment 之间就可以实现并发,大大提高效率。
底层结构: Segment 数组 + HashEntry 数组 + 链表(数组 + 链表是 HashMap 的结构)
-
优点:如果多个线程访问不同的 segment,实际是没有冲突的,这与 JDK8 中是类似的
-
缺点:Segments 数组默认大小为16,这个容量初始化指定后就不能改变了,并且不是懒惰初始化

concurrencyLevel:并行级别、并发数、Segment 数,怎么翻译不重要,理解它。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
初始化
initialCapacity:初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。
loadFactor:负载因子,之前我们说了,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的。
1 | public ConcurrentHashMap(int initialCapacity, |
初始化完成,我们得到了一个 Segment 数组。
我们就当是用 new ConcurrentHashMap() 无参构造函数进行初始化的,那么初始化完成后:
- Segment 数组长度为 16,不可以扩容
- Segment[i] 的默认大小为 2,负载因子是 0.75,得出初始阈值为 1.5,也就是以后插入第一个元素不会触发扩容,插入第二个会进行第一次扩容
- 这里初始化了 segment[0],其他位置还是 null,至于为什么要初始化 segment[0],后面的代码会介绍
- 当前 segmentShift 的值为 32 - 4 = 28,segmentMask 为 16 - 1 = 15,姑且把它们简单翻译为移位数和掩码,这两个值马上就会用到
put 过程分析
我们先看 put 的主流程,对于其中的一些关键细节操作,后面会进行详细介绍。
1 | public V put(K key, V value) { |
第一层皮很简单,根据 hash 值很快就能找到相应的 Segment,之后就是 Segment 内部的 put 操作了。
Segment 内部是由 数组+链表 组成的。
1 | final V put(K key, int hash, V value, boolean onlyIfAbsent) { |
整体流程还是比较简单的,由于有独占锁的保护,所以 segment 内部的操作并不复杂。至于这里面的并发问题,我们稍后再进行介绍。
到这里 put 操作就结束了,接下来,我们说一说其中几步关键的操作。
初始化槽:ensureSegment
ConcurrentHashMap 初始化的时候会初始化第一个槽 segment[0],对于其他槽来说,在插入第一个值的时候进行初始化。
这里需要考虑并发,因为很可能会有多个线程同时进来初始化同一个槽 segment[k],不过只要有一个成功了就可以。
1 | private Segment<K,V> ensureSegment(int k) { |
总的来说,ensureSegment(int k) 比较简单,对于并发操作使用 CAS 进行控制。
获取写入锁: scanAndLockForPut
前面我们看到,在往某个 segment 中 put 的时候,首先会调用 node = tryLock() ? null : scanAndLockForPut(key, hash, value),也就是说先进行一次 tryLock() 快速获取该 segment 的独占锁,如果失败,那么进入到 scanAndLockForPut 这个方法来获取锁。
下面我们来具体分析这个方法中是怎么控制加锁的。
1 | private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) { |
这个方法有两个出口,一个是 tryLock() 成功了,循环终止,另一个就是重试次数超过了 MAX_SCAN_RETRIES,进到 lock() 方法,此方法会阻塞等待,直到成功拿到独占锁。
这个方法就是看似复杂,但是其实就是做了一件事,那就是获取该 segment 的独占锁,如果需要的话顺便实例化了一下 node。
扩容:rehash
重复一下,segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry<K,V>[] 进行扩容,扩容后,容量为原来的 2 倍。
首先,我们要回顾一下触发扩容的地方,put 的时候,如果判断该值的插入会导致该 segment 的元素个数超过阈值,那么先进行扩容,再插值,读者这个时候可以回去 put 方法看一眼。
该方法不需要考虑并发,因为到这里的时候,是持有该 segment 的独占锁的。
1 | // 方法参数上的 node 是这次扩容后,需要添加到新的数组中的数据。 |
这里的扩容比之前的 HashMap 要复杂一些,代码难懂一点。上面有两个挨着的 for 循环,第一个 for 有什么用呢?
仔细一看发现,如果没有第一个 for 循环,也是可以工作的,但是,这个 for 循环下来,如果 lastRun 的后面还有比较多的节点,那么这次就是值得的。因为我们只需要克隆 lastRun 前面的节点,后面的一串节点跟着 lastRun 走就是了,不需要做任何操作。
我觉得 Doug Lea 的这个想法也是挺有意思的,不过比较坏的情况就是每次 lastRun 都是链表的最后一个元素或者很靠后的元素,那么这次遍历就有点浪费了。不过 Doug Lea 也说了,根据统计,如果使用默认的阈值,大约只有 1/6 的节点需要克隆。
get 过程分析
相对于 put 来说,get 真的不要太简单。
- 计算 hash 值,找到 segment 数组中的具体位置,或我们前面用的“槽”
- 槽中也是一个数组,根据 hash 找到数组中具体的位置
- 到这里是链表了,顺着链表进行查找即可
1 | public V get(Object key) { |
并发问题分析
现在我们已经说完了 put 过程和 get 过程,我们可以看到 get 过程中是没有加锁的,那自然我们就需要去考虑并发问题。
添加节点的操作 put 和删除节点的操作 remove 都是要加 segment 上的独占锁的,所以它们之间自然不会有问题,我们需要考虑的问题就是 get 的时候在同一个 segment 中发生了 put 或 remove 操作。
-
put 操作的线程安全性。
- 初始化槽,这个我们之前就说过了,使用了 CAS 来初始化 Segment 中的数组。
- 添加节点到链表的操作是插入到表头的,所以,如果这个时候 get 操作在链表遍历的过程已经到了中间,是不会影响的。当然,另一个并发问题就是 get 操作在 put 之后,需要保证刚刚插入表头的节点被读取,这个依赖于 setEntryAt 方法中使用的 UNSAFE.putOrderedObject。
- 扩容。扩容是新创建了数组,然后进行迁移数据,最后面将 newTable 设置给属性 table。所以,如果 get 操作此时也在进行,那么也没关系,如果 get 先行,那么就是在旧的 table 上做查询操作;而 put 先行,那么 put 操作的可见性保证就是 table 使用了 volatile 关键字。
-
remove 操作的线程安全性。
remove 操作我们没有分析源码,所以这里说的读者感兴趣的话还是需要到源码中去求实一下的。
get 操作需要遍历链表,但是 remove 操作会"破坏"链表。
如果 remove 破坏的节点 get 操作已经过去了,那么这里不存在任何问题。
如果 remove 先破坏了一个节点,分两种情况考虑。
- 如果此节点是头结点,那么需要将头结点的 next 设置为数组该位置的元素,table 虽然使用了 volatile 修饰,但是 volatile 并不能提供数组内部操作的可见性保证,所以源码中使用了 UNSAFE 来操作数组,请看方法 setEntryAt。
- 如果要删除的节点不是头结点,它会将要删除节点的后继节点接到前驱节点中,这里的并发保证就是 next 属性是 volatile 的。
8.2 ConcurrentHashMap
8.2.1 内部类
-
Node 节点:
1
2
3
4
5
6
7
8static class Node<K,V> implements Map.Entry<K,V> {
// 节点哈希值
final int hash;
final K key;
volatile V val;
// 单向链表
volatile Node<K,V> next;
} -
TreeBin 节点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16static final class TreeBin<K,V> extends Node<K,V> {
// 红黑树根节点
TreeNode<K,V> root;
// 链表的头节点
volatile TreeNode<K,V> first;
// 等待者线程
volatile Thread waiter;
volatile int lockState;
// 写锁状态 写锁是独占状态,以散列表来看,真正进入到 TreeBin 中的写线程同一时刻只有一个线程
static final int WRITER = 1;
// 等待者状态(写线程在等待),当 TreeBin 中有读线程目前正在读取数据时,写线程无法修改数据
static final int WAITER = 2;
// 读锁状态是共享,同一时刻可以有多个线程 同时进入到 TreeBin 对象中获取数据,每一个线程都给 lockState + 4
static final int READER = 4;
} -
TreeNode 节点:
1
2
3
4
5
6
7static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; //双向链表
boolean red;
} -
ForwardingNode 节点:转移节点
1
2
3
4
5
6
7
8static final class ForwardingNode<K,V> extends Node<K,V> {
// 持有扩容后新的哈希表的引用
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null);
this.nextTable = tab;
}
}
代码块
-
变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20private static final Unsafe U = Unsafe.getUnsafe();
// 表示sizeCtl属性在 ConcurrentHashMap 中内存偏移地址
private static final long SIZECTL
= U.objectFieldOffset(ConcurrentHashMap.class, "sizeCtl");
// 表示transferIndex属性在 ConcurrentHashMap 中内存偏移地址
private static final long TRANSFERINDEX
= U.objectFieldOffset(ConcurrentHashMap.class, "transferIndex");
// 表示baseCount属性在 ConcurrentHashMap 中内存偏移地址
private static final long BASECOUNT
= U.objectFieldOffset(ConcurrentHashMap.class, "baseCount");
// 表示cellsBusy属性在 ConcurrentHashMap 中内存偏移地址
private static final long CELLSBUSY
= U.objectFieldOffset(ConcurrentHashMap.class, "cellsBusy");
// 表示cellValue属性在 CounterCell 中内存偏移地址
private static final long CELLVALUE
= U.objectFieldOffset(CounterCell.class, "value");
// 表示数组第一个元素的偏移地址
private static final long ABASE= U.arrayBaseOffset(Node[].class);
// 用位移运算替代乘法
private static final int ASHIFT; -
赋值方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22static {
// 表示数组单元所占用空间大小,scale 表示 Node[] 数组中每一个单元所占用空间大小,int 是 4 字节
int scale = U.arrayIndexScale(ak);
// 判断一个数是不是 2 的 n 次幂,比如 8:1000 & 0111 = 0000
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
// numberOfLeadingZeros(n):返回当前数值转换为二进制后,从高位到低位开始统计,看有多少个0连续在一起
// 8 → 1000 numberOfLeadingZeros(8) = 28
// 4 → 100 numberOfLeadingZeros(4) = 29 int 值就是占4个字节
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
// ASHIFT = 31 - 29 = 2 ,int 的大小就是 2 的 2 次方,获取次方数
// ABASE + (5 << ASHIFT) 用位移运算替代了乘法,获取 arr[5] 的值
// Reduce the risk of rare disastrous classloading in first call to
// LockSupport.park: https://bugs.openjdk.java.net/browse/JDK-8074773
Class<?> ensureLoaded = LockSupport.class;
// Eager class load observed to help JIT during startup
ensureLoaded = ReservationNode.class;
}
8.2.2 成员属性
-
存储数组:
1
transient volatile Node<K,V>[] table;
-
散列表的长度:
1
2private static final int MAXIMUM_CAPACITY = 1 << 30; // 最大长度
private static final int DEFAULT_CAPACITY = 16; // 默认长度 -
并发级别,JDK7 遗留下来,1.8 中不代表并发级别:
1
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
-
负载因子,JDK1.8 的 ConcurrentHashMap 中是固定值:
1
private static final float LOAD_FACTOR = 0.75f;
-
阈值:
1
2
3static final int TREEIFY_THRESHOLD = 8; // 链表树化的阈值
static final int UNTREEIFY_THRESHOLD = 6; // 红黑树转化为链表的阈值
static final int MIN_TREEIFY_CAPACITY = 64; // 当数组长度达到64且某个桶位中的链表长度超过8,才会真正树化 -
扩容相关:
1
2
3
4private static final int MIN_TRANSFER_STRIDE = 16; // 线程迁移数据【最小步长】,控制线程迁移任务的最小区间
private static int RESIZE_STAMP_BITS = 16; // 用来计算扩容时生成的【标识戳】
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;// 65535-1并发扩容最多线程数
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; // 扩容时使用 -
节点哈希值:
1
2
3
4static final int MOVED = -1; // 表示当前节点是 FWD 节点
static final int TREEBIN = -2; // 表示当前节点已经树化,且当前节点为 TreeBin 对象
static final int RESERVED = -3; // 表示节点是临时节点
static final int HASH_BITS = 0x7fffffff; // 正常节点的哈希值的可用的位数 -
扩容过程:volatile 修饰保证多线程的可见性
1
2
3
4// 扩容过程中,会将扩容中的新 table 赋值给 nextTable 保持引用,扩容结束之后,这里会被设置为 null
private transient volatile Node<K,V>[] nextTable;
// 记录扩容进度,所有线程都要从 0 - transferIndex 中分配区间任务,简单说就是老表转移到哪了,索引从高到低转移
private transient volatile int transferIndex; -
累加统计:
1
2
3
4
5
6// LongAdder 中的 baseCount 未发生竞争时或者当前LongAdder处于加锁状态时,增量累到到 baseCount 中
private transient volatile long baseCount;
// LongAdder 中的 cellsBuzy,0 表示当前 LongAdder 对象无锁状态,1 表示当前 LongAdder 对象加锁状态
private transient volatile int cellsBusy;
// LongAdder 中的 cells 数组,
private transient volatile CounterCell[] counterCells; -
控制变量:
sizeCtl < 0:
-
-1 表示当前 table 正在初始化(有线程在创建 table 数组),当前线程需要自旋等待
-
其他负数表示当前 map 的 table 数组正在进行扩容,高 16 位表示扩容的标识戳;低 16 位表示 (1 + nThread) 当前参与并发扩容的线程数量 + 1
sizeCtl = 0:
- 代表数组未初始化,且数组的初始容量为 DEFAULT_CAPACITY 16
sizeCtl > 0:
- 如果 table 未初始化,表示初始化大小
- 如果 table 已经初始化,表示下次扩容时的触发条件(阈值,元素个数,不是数组的长度)
1
private transient volatile int sizeCtl; // volatile 保持可见性
-
8.2.2 构造方法
-
无参构造, 散列表结构延迟初始化,默认的数组大小是 16:
1
2public ConcurrentHashMap() {
} -
有参构造:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// 初始容量小于并发级别
if (initialCapacity < concurrencyLevel)
// 把并发级别赋值给初始容量
initialCapacity = concurrencyLevel;
// loadFactor 默认是 0.75
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
// sizeCtl > 0,当目前 table 未初始化时,sizeCtl 表示初始化容量
this.sizeCtl = cap;
}1
2
3
4
5//计算大于或等于给定容量 c 的最小2的幂次方数。
private static final int tableSizeFor(int c) {
int n = -1 >>> Integer.numberOfLeadingZeros(c - 1);
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
} -
集合构造方法:
1
2
3
4
5
6
7
8
9
10public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY; // 默认16
putAll(m);
}
public void putAll(Map<? extends K, ? extends V> m) {
// 尝试触发扩容
tryPresize(m.size());
for (Entry<? extends K, ? extends V> e : m.entrySet())
putVal(e.getKey(), e.getValue(), false);
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34private final void tryPresize(int size) {
// 扩容为大于 2 倍的最小的 2 的 n 次幂
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
// 数组还未初始化,【一般是调用集合构造方法才会成立,put 后调用该方法都是不成立的】
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2);// 扩容阈值:n - 1/4 n
}
} finally {
sizeCtl = sc; // 扩容阈值赋值给sizeCtl
}
}
}
// 未达到扩容阈值或者数组长度已经大于最大长度
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
// 与 addCount 逻辑相同
else if (tab == table) {
int rs = resizeStamp(n);
if (U.compareAndSetInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
8.2.3 成员方法
数据访存
-
tabAt():获取数组某个槽位的头节点,类似于数组中的直接寻址 arr[i]
1
2
3
4
5// i 是数组索引
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
// (i << ASHIFT) + ABASE == ABASE + i * 4 (一个 int 占 4 个字节),这就相当于寻址,替代了乘法
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
} -
casTabAt():指定数组索引位置修改原值为指定的值
1
2
3static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
} -
setTabAt():指定数组索引位置设置值
1
2
3static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
添加方法
1 | public V put(K key, V value) { |
-
putVal()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100final V putVal(K key, V value, boolean onlyIfAbsent) {
// 【ConcurrentHashMap 不能存放 null 值】
if (key == null || value == null) throw new NullPointerException();
// 扰动运算,高低位都参与寻址运算(计算结果一定是正数,方便后面添加元素时判断节点类型)
int hash = spread(key.hashCode());
// 表示当前 k-v 封装成 node 后插入到指定桶位后,在桶位中的所属链表的下标位置
int binCount = 0;
// tab 引用当前 map 的数组 table,开始自旋
for (Node<K,V>[] tab = table;;) {
// f 表示桶位的头节点,n 表示哈希表数组的长度
// i 表示 key 通过寻址计算后得到的桶位下标,fh 表示桶位头结点的 hash 值
Node<K,V> f; int n, i, fh;
// 【CASE1】:表示当前 map 中的 table 尚未初始化
if (tab == null || (n = tab.length) == 0)
//【延迟初始化】
tab = initTable();
// 【CASE2】:i 表示 key 使用【寻址算法】得到 key 对应数组的下标位置,tabAt 获取指定桶位的头结点f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 对应的数组为 null 说明没有哈希冲突,直接新建节点添加到表中
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break;
}
// 【CASE3】:逻辑说明数组已经被初始化,并且当前 key 对应的位置不为 null
// 条件成立表示当前桶位的头结点为 FWD 结点,表示目前 map 正处于扩容过程中
else if ((fh = f.hash) == MOVED)
// 当前线程【需要去帮助哈希表完成扩容】
tab = helpTransfer(tab, f);
// 【CASE4】:哈希表没有在扩容,当前桶位可能是链表也可能是红黑树
else {
// 当插入 key 存在时,会将旧值赋值给 oldVal 返回
V oldVal = null;
// 【锁住当前 key 寻址的桶位的头节点】
synchronized (f) {
// 这里重新获取一下桶的头节点判断有没有被修改,因为可能被其他线程修改过,这里是线程安全的获取
if (tabAt(tab, i) == f) {
// 【头节点的哈希值大于 0 说明当前桶位是普通的链表节点】
if (fh >= 0) {
// 当前的插入操作没出现重复的 key,追加到链表的末尾,binCount表示链表长度 -1
// 插入的key与链表中的某个元素的 key 一致,变成替换操作,binCount 表示第几个节点冲突
binCount = 1;
// 迭代循环当前桶位的链表,e 是每次循环处理节点,e 初始是头节点
for (Node<K,V> e = f;; ++binCount) {
// 当前循环节点 key
K ek;
// key 的哈希值与当前节点的哈希一致,并且 key 的值也相同
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
// 把当前节点的 value 赋值给 oldVal
oldVal = e.val;
// 允许覆盖
if (!onlyIfAbsent)
// 新数据覆盖旧数据
e.val = value;
// 跳出循环
break;
}
Node<K,V> pred = e;
// 如果下一个节点为空,把数据封装成节点插入链表尾部,【binCount 代表长度 - 1】
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 当前桶位头节点是红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 条件成立说明当前是链表或者红黑树
if (binCount != 0) {
// 如果 binCount >= 8 表示处理的桶位一定是链表,说明长度是 9
if (binCount >= TREEIFY_THRESHOLD)
// 树化
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 统计当前 table 一共有多少数据,判断是否达到扩容阈值标准,触发扩容
// binCount = 0 表示当前桶位为 null,node 可以直接放入,2 表示当前桶位已经是红黑树
addCount(1L, binCount);
return null;
} -
spread():扰动函数
将 hashCode 无符号右移 16 位,高 16bit 和低 16bit 做异或,最后与 HASH_BITS 相与变成正数,与树化节点和转移节点区分,把高低位都利用起来减少哈希冲突,保证散列的均匀性
1
2
3static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS; // 0111 1111 1111 1111 1111 1111 1111 1111
} -
initTable():初始化数组,延迟初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31private final Node<K,V>[] initTable() {
// tab 引用 map.table,sc 引用 sizeCtl
Node<K,V>[] tab; int sc;
// table 尚未初始化,开始自旋
while ((tab = table) == null || tab.length == 0) {
// sc < 0 说明 table 正在初始化或者正在扩容,当前线程可以释放 CPU 资源
if ((sc = sizeCtl) < 0)
Thread.yield();
// sizeCtl 设置为 -1,相当于加锁,【设置的是 SIZECTL 位置的数据】,
// 因为是 sizeCtl 是基本类型,不是引用类型,所以 sc 保存的是数据的副本
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// 线程安全的逻辑,再进行一次判断
if ((tab = table) == null || tab.length == 0) {
// sc > 0 创建 table 时使用 sc 为指定大小,否则使用 16 默认值
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 创建哈希表数组
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// 扩容阈值,n >>> 2 => 等于 1/4 n ,n - (1/4)n = 3/4 n => 0.75 * n
sc = n - (n >>> 2);
}
} finally {
// 解锁,把下一次扩容的阈值赋值给 sizeCtl
sizeCtl = sc;
}
break;
}
}
return tab;
} -
treeifyBin():树化方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
// 条件成立:【说明当前 table 数组长度未达到 64,此时不进行树化操作,进行扩容操作】
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
// 当前容量的 2 倍
tryPresize(n << 1);
// 条件成立:说明当前桶位有数据,且是普通 node 数据。
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
// 【树化加锁】
synchronized (b) {
// 条件成立:表示加锁没问题。
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
// 遍历链表,将普通节点转换为树节点
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val,null, null);
// 构建双向链表结构
if ((p.prev = tl) == null)
hd = p; // 设置头节点
else
tl.next = p; // 连接前后节点
tl = p; // 更新尾节点
}
// 将链表替换为红黑树结构
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
} -
addCount():添加计数,代表哈希表中的数据总量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66private final void addCount(long x, int check) {
// 【上面这部分的逻辑就是 LongAdder 的累加逻辑】
CounterCell[] as; long b, s;
// 判断累加数组 cells 是否初始化,没有就去累加 base 域,累加失败进入条件内逻辑
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
// true 未竞争,false 发生竞争
boolean uncontended = true;
// 判断 cells 是否被其他线程初始化
if (as == null || (m = as.length - 1) < 0 ||
// 前面的条件为 fasle 说明 cells 被其他线程初始化,通过 hash 寻址对应的槽位
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
// 尝试去对应的槽位累加,累加失败进入 fullAddCount 进行重试或者扩容
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
// 与 Striped64#longAccumulate 方法相同
fullAddCount(x, uncontended);
return;
}
// 表示当前桶位是 null,或者一个链表节点
if (check <= 1)
return;
// 【获取当前散列表元素个数】,这是一个期望值
s = sumCount();
}
// 表示一定 【是一个 put 操作调用的 addCount】
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
// 条件一:true 说明当前 sizeCtl 可能为一个负数表示正在扩容中,或者 sizeCtl 是一个正数,表示扩容阈值
// false 表示哈希表的数据的数量没达到扩容条件
// 然后判断当前 table 数组是否初始化了,当前 table 长度是否小于最大值限制,就可以进行扩容
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
// 16 -> 32 扩容 标识为:1000 0000 0001 1011,【负数,扩容批次唯一标识戳】
int rs = resizeStamp(n);
// 表示当前 table,【正在扩容】,sc 高 16 位是扩容标识戳,低 16 位是线程数 + 1
if (sc < 0) {
// 条件一:判断扩容标识戳是否一样,fasle 代表一样
// 勘误两个条件:
// 条件二是:sc == (rs << 16 ) + 1,true 代表扩容完成,因为低16位是1代表没有线程扩容了
// 条件三是:sc == (rs << 16) + MAX_RESIZERS,判断是否已经超过最大允许的并发扩容线程数
// 条件四:判断新表的引用是否是 null,代表扩容完成
// 条件五:【扩容是从高位到低位转移】,transferIndex < 0 说明没有区间需要扩容了
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 设置当前线程参与到扩容任务中,将 sc 低 16 位值加 1,表示多一个线程参与扩容
// 设置失败其他线程或者 transfer 内部修改了 sizeCtl 值
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
//【协助扩容线程】,持有nextTable参数
transfer(tab, nt);
}
// 逻辑到这说明当前线程是触发扩容的第一个线程,线程数量 + 2
// 1000 0000 0001 1011 0000 0000 0000 0000 +2 => 1000 0000 0001 1011 0000 0000 0000 0010
else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))
//【触发扩容条件的线程】,不持有 nextTable,初始线程会新建 nextTable
transfer(tab, null);
s = sumCount();
}
}
} -
resizeStamp():扩容标识符,每次扩容都会产生一个,不是每个线程都产生,16 扩容到 32 产生一个,32 扩容到 64 产生一个
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/**
* 扩容的标识符
* 16 -> 32 从16扩容到32
* numberOfLeadingZeros(16) => 1 0000 => 32 - 5 = 27 => 0000 0000 0001 1011
* (1 << (RESIZE_STAMP_BITS - 1)) => 1000 0000 0000 0000 => 32768
* ---------------------------------------------------------------
* 0000 0000 0001 1011
* 1000 0000 0000 0000
* 1000 0000 0001 1011
* 永远是负数
*/
static final int resizeStamp(int n) {
// 或运算
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1)); // (16 -1 = 15)
} -
fullAddCount 添加或减少给定值
x到计数器中,根据需要初始化或扩展计数器表(counterCells)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127/**
* @param x 要添加的值
* @param wasUncontended 上一次CAS操作是否成功
*/
private final void fullAddCount(long x, boolean wasUncontended) {
// 线程的哈希码,用于在计数器单元格中分布
int h;
// 确保线程本地哈希已初始化
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit(); // 强制初始化
h = ThreadLocalRandom.getProbe();
wasUncontended = true; // 重新初始化后重置争用标志
}
// 标志位,指示上一次迭代是否发生冲突
boolean collide = false; // 如果最后一个槽位非空则为true
// 主循环:尝试将值添加到适当的单元格
for (;;) {
CounterCell[] cs;
CounterCell c;
int n;
long v;
// 检查 counterCells 数组是否存在且有元素
if ((cs = counterCells) != null && (n = cs.length) > 0) {
// 情况1:目标单元格为空
if ((c = cs[(n - 1) & h]) == null) {
// 尝试初始化并安装新的 CounterCell(如果没有其他线程正忙)
if (cellsBusy == 0) {
CounterCell r = new CounterCell(x);
// 双重检查锁定后再安装新单元格
if (cellsBusy == 0 &&
U.compareAndSetInt(this, CELLSBUSY, 0, 1)) {
boolean created = false;
try {
CounterCell[] rs;
int m, j;
// 重新检查目标单元格是否仍然为空
if ((rs = counterCells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0; // 释放锁
}
if (created)
break; // 成功添加,退出循环
continue; // 槽位被其他线程填充,重试
}
}
collide = false; // 重置冲突标志
}
// 情况2:之前的CAS失败,标记为无争用并再次尝试
else if (!wasUncontended)
wasUncontended = true;
// 情况3:尝试使用CAS更新现有单元格
else if (U.compareAndSetLong(c, CELLVALUE, v = c.value, v + x))
break; // 成功,退出循环
// 情况4:表可能已过期或达到最大容量
else if (counterCells != cs || n >= NCPU)
collide = false;
// 情况5:首次检测到冲突
else if (!collide)
collide = true;
// 情况6:由于冲突而扩展表
else if (cellsBusy == 0 &&
U.compareAndSetInt(this, CELLSBUSY, 0, 1)) {
try {
// 仅当表未更改时才扩展
if (counterCells == cs)
counterCells = Arrays.copyOf(cs, n << 1); // 大小翻倍
} finally {
cellsBusy = 0; // 释放锁
}
collide = false;
continue; // 使用扩展后的表重试
}
// 更新探针值用于下次迭代(重新哈希)
h = ThreadLocalRandom.advanceProbe(h);
}
// 情况7:初始化 counterCells 数组
else if (cellsBusy == 0 && counterCells == cs &&
U.compareAndSetInt(this, CELLSBUSY, 0, 1)) {
boolean init = false;
try {
// 双重检查初始化条件
if (counterCells == cs) {
CounterCell[] rs = new CounterCell[2];
rs[h & 1] = new CounterCell(x);
counterCells = rs;
init = true;
}
} finally {
cellsBusy = 0; // 释放锁
}
if (init)
break; // 初始化成功
}
// 情况8:回退到直接更新 baseCount
else if (U.compareAndSetLong(this, BASECOUNT, v = baseCount, v + x))
break; // 回退到使用基础计数器
}
}
扩容方法
扩容机制:
- 当链表中元素个数超过 8 个,数组的大小还未超过 64 时,此时进行数组的扩容,如果超过则将链表转化成红黑树
- put 数据后调用 addCount() 方法,判断当前哈希表的容量超过阈值 sizeCtl,超过进行扩容
- 增删改线程发现其他线程正在扩容,帮其扩容
常见方法:
-
transfer():数据转移到新表中,完成扩容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
// n 表示扩容之前 table 数组的长度
int n = tab.length, stride;
// stride 表示分配给线程任务的步长,默认就是 16
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE;
// 如果当前线程为触发本次扩容的线程,需要做一些扩容准备工作,【协助线程不做这一步】
if (nextTab == null) {
try {
// 创建一个容量是之前【二倍的 table 数组】
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE;
return;
}
// 把新表赋值给对象属性 nextTable,方便其他线程获取新表
nextTable = nextTab;
// 记录迁移数据整体位置的一个标记,transferIndex 计数从1开始不是 0,所以这里是长度,不是长度-1
transferIndex = n;
}
// 新数组的长度
int nextn = nextTab.length;
// 当某个桶位数据处理完毕后,将此桶位设置为 fwd 节点,其它写线程或读线程看到后,可以从中获取到新表
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// 推进标记
boolean advance = true;
// 完成标记
boolean finishing = false;
// i 表示分配给当前线程任务,执行到的桶位
// bound 表示分配给当前线程任务的下界限制,因为是倒序迁移,16 迁移完 迁移 15,15完成去迁移14
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// 给当前线程【分配任务区间】
while (advance) {
// 分配任务的开始下标,分配任务的结束下标
int nextIndex, nextBound;
// --i 让当前线程处理下一个索引,true说明当前的迁移任务尚未完成,false说明线程已经完成或者还未分配
if (--i >= bound || finishing)
advance = false;
// 迁移的开始下标,小于0说明没有区间需要迁移了,设置当前线程的 i 变量为 -1 跳出循环
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// 逻辑到这说明还有区间需要分配,然后给当前线程分配任务,
else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,
// 判断区间是否还够一个步长,不够就全部分配
nextBound = (nextIndex > stride ? nextIndex - stride : 0))) {
// 当前线程的结束下标
bound = nextBound;
// 当前线程的开始下标,上一个线程结束的下标的下一个索引就是这个线程开始的下标
i = nextIndex - 1;
// 任务分配结束,跳出循环执行迁移操作
advance = false;
}
}
// 【分配完成,开始数据迁移操作】
// 【CASE1】:i < 0 成立表示当前线程未分配到任务,或者任务执行完了
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
// 如果迁移完成
if (finishing) {
nextTable = null; // help GC
table = nextTab; // 新表赋值给当前对象
sizeCtl = (n << 1) - (n >>> 1);// 扩容阈值为 2n - n/2 = 3n/2 = 0.75*(2n)
return;
}
// 当前线程完成了分配的任务区间,可以退出,先把 sizeCtl 赋值给 sc 保留
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// 判断当前线程是不是最后一个线程,不是的话直接 return,
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
// 所以最后一个线程退出的时候,sizeCtl 的低 16 位为 1
finishing = advance = true;
// 【这里表示最后一个线程需要重新检查一遍是否有漏掉的区间】
i = n;
}
}
// 【CASE2】:当前桶位未存放数据,只需要将此处设置为 fwd 节点即可。
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 【CASE3】:说明当前桶位已经迁移过了,当前线程不用再处理了,直接处理下一个桶位即可
else if ((fh = f.hash) == MOVED)
advance = true;
// 【CASE4】:当前桶位有数据,而且 node 节点不是 fwd 节点,说明这些数据需要迁移
else {
// 【锁住头节点】
synchronized (f) {
// 二次检查,防止头节点已经被修改了,因为这里才是线程安全的访问
if (tabAt(tab, i) == f) {
// 【迁移数据的逻辑,和 HashMap 相似】
// ln 表示低位链表引用
// hn 表示高位链表引用
Node<K,V> ln, hn;
// 哈希 > 0 表示当前桶位是链表桶位
if (fh >= 0) {
// 和 HashMap 的处理方式一致,与老数组长度相与,16 是 10000
// 判断对应的 1 的位置上是 0 或 1 分成高低位链表
int runBit = fh & n;
Node<K,V> lastRun = f;
// 遍历链表,寻找【逆序看】最长的对应位相同的链表,看下面的图更好的理解
for (Node<K,V> p = f.next; p != null; p = p.next) {
// 将当前节点的哈希 与 n
int b = p.hash & n;
// 如果当前值与前面节点的值 对应位 不同,则修改 runBit,把 lastRun 指向当前节点
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
// 判断筛选出的链表是低位的还是高位的
if (runBit == 0) {
ln = lastRun; // ln 指向该链表
hn = null; // hn 为 null
}
// 说明 lastRun 引用的链表为高位链表,就让 hn 指向高位链表头节点
else {
hn = lastRun;
ln = null;
}
// 从头开始遍历所有的链表节点,迭代到 p == lastRun 节点跳出循环
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
// 【头插法】,从右往左看,首先 ln 指向的是上一个节点,
// 所以这次新建的节点的 next 指向上一个节点,然后更新 ln 的引用
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// 高低位链设置到新表中的指定位置
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
// 老表中的该桶位设置为 fwd 节点
setTabAt(tab, i, fwd);
advance = true;
}
// 条件成立:表示当前桶位是 红黑树结点
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
// 迭代 TreeBin 中的双向链表,从头结点至尾节点
for (Node<K,V> e = t.first; e != null; e = e.next) {
// 迭代的当前元素的 hash
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
// 条件成立表示当前循环节点属于低位链节点
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
//【尾插法】
loTail.next = p;
// loTail 指向尾节点
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 拆成的高位低位两个链,【判断是否需要需要转化为链表】,反之保持树化
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}链表处理的 LastRun 机制,可以减少节点的创建

-
helpTransfer():帮助扩容机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
// 数组不为空,节点是转发节点,获取转发节点指向的新表开始协助主线程扩容
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
// 扩容标识戳
int rs = resizeStamp(tab.length);
// 判断数据迁移是否完成,迁移完成会把 新表赋值给 nextTable 属性
while (nextTab == nextTable && table == tab && (sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
// 设置扩容线程数量 + 1
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
// 协助扩容
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
获取方法
ConcurrentHashMap 使用 get() 方法获取指定 key 的数据
-
get():获取指定数据的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// 扰动运算,获取 key 的哈希值
int h = spread(key.hashCode());
// 判断当前哈希表的数组是否初始化
if ((tab = table) != null && (n = tab.length) > 0 &&
// 如果 table 已经初始化,进行【哈希寻址】,映射到数组对应索引处,获取该索引处的头节点
(e = tabAt(tab, (n - 1) & h)) != null) {
// 对比头结点 hash 与查询 key 的 hash 是否一致
if ((eh = e.hash) == h) {
// 进行值的判断,如果成功就说明当前节点就是要查询的节点,直接返回
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 当前槽位的【哈希值小于0】说明是红黑树节点或者是正在扩容的 fwd 节点
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 当前桶位是【链表】,循环遍历查找
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
} -
ForwardingNode#find:转移节点的查找方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37Node<K,V> find(int h, Object k) {
// 获取新表的引用
outer: for (Node<K,V>[] tab = nextTable;;) {
// e 表示在扩容而创建新表使用寻址算法得到的桶位头结点,n 表示为扩容而创建的新表的长度
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
// 在新表中重新定位 hash 对应的头结点,表示在 oldTable 中对应的桶位在迁移之前就是 null
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
// 【哈希相同值也相同】,表示新表当前命中桶位中的数据,即为查询想要数据
if ((eh = e.hash) == h && ((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
// eh < 0 说明当前新表中该索引的头节点是 TreeBin 类型,或者是 FWD 类型
if (eh < 0) {
// 在并发很大的情况下新扩容的表还没完成可能【再次扩容】,在此方法处再次拿到 FWD 类型
if (e instanceof ForwardingNode) {
// 继续获取新的 fwd 指向的新数组的地址,递归了
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
// 说明此桶位为 TreeBin 节点,使用TreeBin.find 查找红黑树中相应节点。
return e.find(h, k);
}
// 逻辑到这说明当前桶位是链表,将当前元素指向链表的下一个元素,判断当前元素的下一个位置是否为空
if ((e = e.next) == null)
// 条件成立说明迭代到链表末尾,【未找到对应的数据,返回 null】
return null;
}
}
}
删除方法
-
remove():删除指定元素
1
2
3public V remove(Object key) {
return replaceNode(key, null, null);
} -
replaceNode():替代指定的元素,会协助扩容,增删改(写)都会协助扩容,查询(读)操作不会,因为读操作不涉及加锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90final V replaceNode(Object key, V value, Object cv) {
// 计算 key 扰动运算后的 hash
int hash = spread(key.hashCode());
// 开始自旋
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 【CASE1】:table 还未初始化或者哈希寻址的数组索引处为 null,直接结束自旋,返回 null
if (tab == null || (n = tab.length) == 0 || (f = tabAt(tab, i = (n - 1) & hash)) == null)
break;
// 【CASE2】:条件成立说明当前 table 正在扩容,【当前是个写操作,所以当前线程需要协助 table 完成扩容】
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// 【CASE3】:当前桶位可能是 链表 也可能是 红黑树
else {
// 保留替换之前数据引用
V oldVal = null;
// 校验标记
boolean validated = false;
// 【加锁当前桶位头结点】,加锁成功之后会进入代码块
synchronized (f) {
// 双重检查
if (tabAt(tab, i) == f) {
// 说明当前节点是链表节点
if (fh >= 0) {
validated = true;
//遍历所有的节点
for (Node<K,V> e = f, pred = null;;) {
K ek;
// hash 和值都相同,定位到了具体的节点
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
// 当前节点的value
V ev = e.val;
if (cv == null || cv == ev ||
(ev != null && cv.equals(ev))) {
// 将当前节点的值 赋值给 oldVal 后续返回会用到
oldVal = ev;
if (value != null) // 条件成立说明是替换操作
e.val = value;
else if (pred != null) // 非头节点删除操作,断开链表
pred.next = e.next;
else
// 说明当前节点即为头结点,将桶位头节点设置为以前头节点的下一个节点
setTabAt(tab, i, e.next);
}
break;
}
pred = e;
if ((e = e.next) == null)
break;
}
}
// 说明是红黑树节点
else if (f instanceof TreeBin) {
validated = true;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r, p;
if ((r = t.root) != null &&
(p = r.findTreeNode(hash, key, null)) != null) {
V pv = p.val;
if (cv == null || cv == pv ||
(pv != null && cv.equals(pv))) {
oldVal = pv;
// 条件成立说明替换操作
if (value != null)
p.val = value;
// 删除操作
else if (t.removeTreeNode(p))
setTabAt(tab, i, untreeify(t.first));
}
}
}
}
}
// 其他线程修改过桶位头结点时,当前线程 sync 头结点锁错对象,validated 为 false,会进入下次 for 自旋
if (validated) {
if (oldVal != null) {
// 替换的值为 null,【说明当前是一次删除操作,更新当前元素个数计数器】
if (value == null)
addCount(-1L, -1);
return oldVal;
}
break;
}
}
}
return null;
}
size方法
size 计算实际发生在 put,remove 改变集合元素的操作之中
-
没有竞争发生,向 baseCount 累加计数
-
有竞争发生,新建 counterCells,向其中的一个 cell 累加计数
-
counterCells 初始有两个 cell
-
如果计数竞争比较激烈,会创建新的 cell 来累加计数
-
1 | public int size() { |
1 | final long sumCount() { |
参考视频:https://www.bilibili.com/video/BV17i4y1x71z/
8.3 CopyOnWrite
8.3.1 原理分析
CopyOnWriteArrayList 采用了写入时拷贝的思想,增删改操作会将底层数组拷贝一份,在新数组上执行操作,不影响其它线程的并发读,读写分离
CopyOnWriteArraySet 底层对 CopyOnWriteArrayList 进行了包装,装饰器模式
1 | public CopyOnWriteArraySet() { |
-
存储结构:
1
private transient volatile Object[] array; // volatile 保证了读写线程之间的可见性
-
全局锁:保证线程的执行安全
1
final transient ReentrantLock lock = new ReentrantLock();
-
新增数据:需要加锁,创建新的数组操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public boolean add(E e) {
final ReentrantLock lock = this.lock;
// 加锁,保证线程安全
lock.lock();
try {
// 获取旧的数组
Object[] elements = getArray();
int len = elements.length;
// 【拷贝新的数组(这里是比较耗时的操作,但不影响其它读线程)】
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 添加新元素
newElements[len] = e;
// 替换旧的数组,【这个操作以后,其他线程获取数组就是获取的新数组了】
setArray(newElements);
return true;
} finally {
lock.unlock();
}
} -
读操作:不加锁,在原数组上操作
1
2
3
4
5
6public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}适合读多写少的应用场景
-
迭代器:CopyOnWriteArrayList 在返回迭代器时,创建一个内部数组当前的快照(引用),即使其他线程替换了原始数组,迭代器遍历的快照依然引用的是创建快照时的数组,所以这种实现方式也存在一定的数据延迟性,对其他线程并行添加的数据不可见
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public Iterator<E> iterator() {
// 获取到数组引用,整个遍历的过程该数组都不会变,一直引用的都是老数组,
return new COWIterator<E>(getArray(), 0);
}
// 迭代器会创建一个底层array的快照,故主类的修改不影响该快照
static final class COWIterator<E> implements ListIterator<E> {
// 内部数组快照
private final Object[] snapshot;
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
// 数组的引用在迭代过程不会改变
snapshot = elements;
}
// 【不支持写操作】,因为是在快照上操作,无法同步回去
public void remove() {
throw new UnsupportedOperationException();
}
}
8.3.2 弱一致性
数据一致性就是读到最新更新的数据:
-
强一致性:当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值
-
弱一致性:系统并不保证进程或者线程的访问都会返回最新的更新过的值,也不会承诺多久之后可以读到

Thread-0 读到了脏数据
不一定弱一致性就不好
- 数据库的事务隔离级别就是弱一致性的表现
- 并发高和一致性是矛盾的,需要权衡
8.3.3 安全失败
在 java.util 包的集合类就都是快速失败的,而 java.util.concurrent 包下的类都是安全失败
-
快速失败:在 A 线程使用迭代器对集合进行遍历的过程中,此时 B 线程对集合进行修改(增删改),或者 A 线程在遍历过程中对集合进行修改,都会导致 A 线程抛出 ConcurrentModificationException 异常
- AbstractList 类中的成员变量 modCount,用来记录 List 结构发生变化的次数,结构发生变化是指添加或者删除至少一个元素的操作,或者是调整内部数组的大小,仅仅设置元素的值不算结构发生变化
- 在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果改变了抛出 CME 异常
-
安全失败:采用安全失败机制的集合容器,在迭代器遍历时直接在原集合数组内容上访问,但其他线程的增删改都会新建数组进行修改,就算修改了集合底层的数组容器,迭代器依然引用着以前的数组(快照思想),所以不会出现异常
ConcurrentHashMap 不会出现并发时的迭代异常,因为在迭代过程中 CHM 的迭代器并没有判断结构的变化,迭代器还可以根据迭代的节点状态去寻找并发扩容时的新表进行迭代
1
2
3ConcurrentHashMap map = new ConcurrentHashMap();
// KeyIterator
Iterator iterator = map.keySet().iterator();1
2
3
4
5
6
7
8Traverser(Node<K,V>[] tab, int size, int index, int limit) {
// 引用还是原来集合的 Node 数组,所以其他线程对数据的修改是可见的
this.tab = tab;
this.baseSize = size;
this.baseIndex = this.index = index;
this.baseLimit = limit;
this.next = null;
}1
2
3
4
5
6
7
8
9
10
11public final boolean hasNext() { return next != null; }
public final K next() {
Node<K,V> p;
if ((p = next) == null)
throw new NoSuchElementException();
K k = p.key;
lastReturned = p;
// 在方法中进行下一个节点的获取,会进行槽位头节点的状态判断
advance();
return k;
}
8.4 Collections
Collections类是用来操作集合的工具类,提供了集合转换成线程安全的方法:
1 | public static <T> Collection<T> synchronizedCollection(Collection<T> c) { |
源码:底层也是对方法进行加锁
1 | public boolean add(E e) { |
8.5 SkipListMap
8.5.1 底层结构
跳表 SkipList 是一个有序的链表,默认升序,底层是链表加多级索引的结构。跳表可以对元素进行快速查询,类似于平衡树,是一种利用空间换时间的算法
对于单链表,即使链表是有序的,如果查找数据也只能从头到尾遍历链表,所以采用链表上建索引的方式提高效率,跳表的查询时间复杂度是 O(logn),空间复杂度 O(n)
ConcurrentSkipListMap 提供了一种线程安全的并发访问的排序映射表,内部是跳表结构实现,通过 CAS + volatile 保证线程安全
平衡树和跳表的区别:
- 对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整;而对跳表的插入和删除,只需要对整个结构的局部进行操作
- 在高并发的情况下,保证整个平衡树的线程安全需要一个全局锁;对于跳表则只需要部分锁,拥有更好的性能

BaseHeader 存储数据,headIndex 存储索引,纵向上所有索引都指向链表最下面的节点
8.5.2 成员变量
1 | // Conditionally serializable |
-
Node 节点
1
2
3
4
5
6
7
8
9
10static final class Node<K,V> {
final K key; // currently, never detached
V val;
Node<K,V> next;
Node(K key, V value, Node<K,V> next) {
this.key = key;
this.val = value;
this.next = next;
}
} -
索引节点 Index,只有向下和向右的指针
1
2
3
4
5
6
7
8
9
10static final class Index<K,V> {
final Node<K,V> node; // currently, never detached
final Index<K,V> down;
Index<K,V> right;
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {
this.node = node;
this.down = down;
this.right = right;
}
}
8.5.3 成员方法
-
构造方法:
1
2
3public ConcurrentSkipListMap() {
this.comparator = null;
} -
cpr:排序
1
2
3
4// x 是比较者,y 是被比较者,比较者大于被比较者 返回正数,小于返回负数,相等返回 0
static final int cpr(Comparator c, Object x, Object y) {
return (c != null) ? c.compare(x, y) : ((Comparable)x).compareTo(y);
}
添加方法
-
findPredecessor():寻找前置节点
从最上层的头索引开始向右查找(链表的后续索引),如果后续索引的节点的 key 大于要查找的 key,则头索引移到下层链表,在下层链表查找,以此反复,一直查找到没有下层的分层索引为止,返回该索引的节点。如果后续索引的节点的 key 小于要查找的 key,则在该层链表中向后查找。由于查找的 key 可能永远大于索引节点的 key,所以只能找到目标的前置索引节点。如果遇到空值索引的存在,通过 CAS 来断开索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41/**
* 查找指定键的前驱节点
*
* @param key 目标键值
* @param cmp 用于比较键值的比较器
* @return 返回跳表中指定键值的前驱节点,如果找不到则返回null
*/
private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) {
Index<K,V> q;
// 确保内存可见性,防止并发访问时出现不一致状态
VarHandle.acquireFence();
// 检查头节点或目标键是否为空
if ((q = head) == null || key == null)
return null;
else {
// 无限循环遍历跳表结构
for (Index<K,V> r, d;;) {
// 在当前层级向右遍历,直到找到大于等于目标键的位置
while ((r = q.right) != null) {
Node<K,V> p; K k;
// 检查索引节点指向的节点是否有效
if ((p = r.node) == null || (k = p.key) == null ||
p.val == null) // 解除指向已删除节点的索引
RIGHT.compareAndSet(q, r, r.right);
// 如果目标键大于当前节点键值,继续向右移动
else if (cpr(cmp, key, k) > 0)
q = r;
// 找到了合适位置,跳出内层循环
else
break;
}
// 如果还有下一层,向下移动
if ((d = q.down) != null)
q = d;
// 已经到达最底层,返回对应的节点
else
return q.node;
}
}
}
-
put():添加数据
1
2
3
4
5
6public V put(K key, V value) {
// 非空判断,value不能为空
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143/**
* 插入指定的键值对到映射中
*
* @param key 要插入的键
* @param value 要关联到键的值
* @param onlyIfAbsent 如果为true,则不更改现有值
* @return 与给定键关联的先前值,如果没有则返回null
*/
private V doPut(K key, V value, boolean onlyIfAbsent) {
// 不允许空键
if (key == null)
throw new NullPointerException();
// 获取用于排序元素的比较器
Comparator<? super K> cmp = comparator;
// 主重试循环:直到操作成功为止
for (;;) {
Index<K,V> h; Node<K,V> b;
// 确保跨线程的变更可见性
VarHandle.acquireFence();
int levels = 0; // 跟踪已下降的层数
// 检查跳表是否已初始化
if ((h = head) == null) { // 尝试初始化跳表
// 创建基础节点(哨兵节点)
Node<K,V> base = new Node<K,V>(null, null, null);
// 创建指向基础节点的初始索引
h = new Index<K,V>(base, null, null);
// 使用原子操作尝试设置为头节点
b = (HEAD.compareAndSet(this, null, h)) ? base : null;
}
else {
// 遍历索引层找到插入点
for (Index<K,V> q = h, r, d;;) {
// 在当前层向右移动,当key > 当前节点的key时
while ((r = q.right) != null) {
Node<K,V> p; K k;
// 检查节点是否有效(未标记删除)
if ((p = r.node) == null || (k = p.key) == null ||
p.val == null)
// 移除无效的索引条目
RIGHT.compareAndSet(q, r, r.right);
else if (cpr(cmp, key, k) > 0)
// 继续向右移动
q = r;
else
// 找到位置,key <= 当前节点的key
break;
}
// 如果可能,下降一层
if ((d = q.down) != null) {
++levels;
q = d;
}
else {
// 到达底层,获取底层节点
b = q.node;
break;
}
}
}
// 如果有有效的基础节点可操作
if (b != null) {
Node<K,V> z = null; // 将保存新插入的节点
for (;;) { // 在底层找到确切的插入点
Node<K,V> n, p; K k; V v; int c;
// 如果到达列表末尾
if ((n = b.next) == null) {
// 通过自我比较来类型检查键(如果无效会抛出ClassCastException)
if (b.key == null)
cpr(cmp, key, key);
c = -1;
}
// 下一个节点无效(标记删除),重启
else if ((k = n.key) == null)
break;
// 下一个节点的值为空 => 节点正在被删除,移除它
else if ((v = n.val) == null) {
unlinkNode(b, n);
c = 1;
}
// 比较键来确定位置
else if ((c = cpr(cmp, key, k)) > 0)
b = n; // 继续向前搜索
// 键已存在
else if (c == 0 &&
(onlyIfAbsent || VAL.compareAndSet(n, v, value)))
return v; // 返回旧值(如果!onlyIfAbsent则可能更新)
// 如果key < k,在'n'之前插入新节点
if (c < 0 &&
NEXT.compareAndSet(b, n,
p = new Node<K,V>(key, value, n))) {
z = p; // 成功插入
break;
}
}
// 如果成功插入了新节点
if (z != null) {
// 随机决定是否添加索引层(1/4概率)
int lr = ThreadLocalRandom.nextSecondarySeed();
if ((lr & 0x3) == 0) {
int hr = ThreadLocalRandom.nextSecondarySeed();
long rnd = ((long)hr << 32) | ((long)lr & 0xffffffffL);
int skips = levels;
Index<K,V> x = null;
// 最多创建62个索引节点,概率递减
for (;;) {
x = new Index<K,V>(z, x, null);
if (rnd >= 0L || --skips < 0)
break;
else
rnd <<= 1;
}
// 尝试将所有创建的索引链接到跳表中
if (addIndices(h, skips, x, cmp) && skips < 0 &&
head == h) {
// 如需要,添加新的顶层索引
Index<K,V> hx = new Index<K,V>(z, x, null);
Index<K,V> nh = new Index<K,V>(h.node, h, hx);
HEAD.compareAndSet(this, h, nh);
}
// 如果在创建索引期间节点被删除,进行清理
if (z.val == null)
findPredecessor(key, cmp); // 清理过期引用
}
// 更新大小计数器
addCount(1L);
return null; // 之前没有映射存在
}
}
}
} -
findNode()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45/**
* 在跳表中查找指定键对应的节点
*
* @param key 要查找的键值
* @return 返回与键值对应的节点,如果不存在则返回null
*/
private Node<K,V> findNode(Object key) {
// 键值不能为空
if (key == null)
throw new NullPointerException(); // 不延迟错误报告
// 获取比较器
Comparator<? super K> cmp = comparator;
Node<K,V> b;
// 外层循环:持续查找直到找到节点或确认不存在
outer: while ((b = findPredecessor(key, cmp)) != null) {
// 内层循环:在底层链表中精确查找
for (;;) {
Node<K,V> n; K k; V v; int c;
// 如果到达链表末尾,说明键不存在
if ((n = b.next) == null)
break outer; // 链表为空
// 如果下一个节点的键为空,说明当前节点b已被删除
else if ((k = n.key) == null)
break; // b节点被删除
// 如果下一个节点的值为空,说明节点n正在被删除,需要解除链接
else if ((v = n.val) == null)
unlinkNode(b, n); // n节点被删除
// 比较键值,如果目标键大于当前节点键,继续向后查找
else if ((c = cpr(cmp, key, k)) > 0)
b = n;
// 找到匹配的键,返回对应节点
else if (c == 0)
return n;
// 如果目标键小于当前节点键,说明键不存在于跳表中
else
break outer;
}
}
// 未找到对应节点
return null;
}
获取方法
-
get(key):获取对应的数据
1
2
3public V get(Object key) {
return doGet(key);
} -
doGet():扫描过程会对已 value = null 的元素进行删除处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75/**
* 从跳表中获取指定键对应的值
*
* @param key 要查找的键值
* @return 返回与键对应的值,如果键不存在则返回null
*/
private V doGet(Object key) {
Index<K,V> q;
// 确保内存可见性,防止并发访问时出现不一致状态
VarHandle.acquireFence();
// 键值不能为空
if (key == null)
throw new NullPointerException();
// 获取比较器
Comparator<? super K> cmp = comparator;
V result = null;
// 如果跳表头部不为空
if ((q = head) != null) {
// 外层循环:遍历跳表的索引层
outer: for (Index<K,V> r, d;;) {
// 在当前索引层向右遍历
while ((r = q.right) != null) {
Node<K,V> p; K k; V v; int c;
// 检查索引节点的有效性
if ((p = r.node) == null || (k = p.key) == null ||
(v = p.val) == null)
// 移除指向无效节点的索引
RIGHT.compareAndSet(q, r, r.right);
// 如果目标键大于当前节点键值,继续向右移动
else if ((c = cpr(cmp, key, k)) > 0)
q = r;
// 找到匹配的键值,保存结果并跳出循环
else if (c == 0) {
result = v;
break outer;
}
// 如果目标键小于当前节点键值,停止向右移动
else
break;
}
// 如果还有下一层索引,向下移动
if ((d = q.down) != null)
q = d;
// 已经到达最底层索引
else {
Node<K,V> b, n;
// 获取底层索引指向的节点
if ((b = q.node) != null) {
// 在底层链表中继续查找
while ((n = b.next) != null) {
V v; int c;
K k = n.key;
// 检查节点有效性或继续向后查找
if ((v = n.val) == null || k == null ||
(c = cpr(cmp, key, k)) > 0)
b = n;
else {
// 找到匹配的键值
if (c == 0)
result = v;
break;
}
}
}
break;
}
}
}
// 返回查找结果
return result;
}
删除方法
-
remove()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63/**
* 从跳表中移除指定键值对
*
* @param key 要移除的键
* @param value 要移除的值,如果为null则忽略值的匹配
* @return 返回被移除的值,如果键不存在则返回null
*/
final V doRemove(Object key, Object value) {
// 键值不能为空
if (key == null)
throw new NullPointerException();
// 获取比较器
Comparator<? super K> cmp = comparator;
V result = null;
Node<K,V> b;
// 外层循环:持续查找直到找到节点或确认不存在
outer: while ((b = findPredecessor(key, cmp)) != null &&
result == null) {
// 内层循环:在底层链表中精确查找
for (;;) {
Node<K,V> n; K k; V v; int c;
// 如果到达链表末尾,说明键不存在
if ((n = b.next) == null)
break outer;
// 如果下一个节点的键为空,说明当前节点b已被删除
else if ((k = n.key) == null)
break;
// 如果下一个节点的值为空,说明节点n正在被删除,需要解除链接
else if ((v = n.val) == null)
unlinkNode(b, n);
// 比较键值,如果目标键大于当前节点键,继续向后查找
else if ((c = cpr(cmp, key, k)) > 0)
b = n;
// 如果目标键小于当前节点键,说明键不存在于跳表中
else if (c < 0)
break outer;
// 如果指定了值且值不匹配,不能删除
else if (value != null && !value.equals(v))
break outer;
// 原子性地将节点值设为null,标记为删除
else if (VAL.compareAndSet(n, v, null)) {
result = v;
unlinkNode(b, n);
break; // 循环清理相关结构
}
}
}
// 如果成功删除了节点
if (result != null) {
// 尝试减少跳表层级
tryReduceLevel();
// 更新计数器
addCount(-1L);
}
// 返回被删除的值
return result;
}经过 findPredecessor() 中的 unlink() 后索引已经被删除

-
tryReduceLevel():尝试减少跳表的层级高度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/**
* 尝试减少跳表的层级高度
* 当跳表的上层索引变得稀疏时,通过移除不必要的上层来优化内存使用
*/
private void tryReduceLevel() {
Index<K,V> h, d, e;
// 检查是否可以减少层级:
// 1. 头节点不为空
// 2. 头节点的右侧为空(第一层没有索引节点)
// 3. 头节点的下一层不为空
// 4. 第二层的右侧也为空
// 5. 第三层也不为空且右侧为空
if ((h = head) != null && h.right == null &&
(d = h.down) != null && d.right == null &&
(e = d.down) != null && e.right == null &&
// 原子性地将头节点从h替换为d(降低一层)
HEAD.compareAndSet(this, h, d) &&
// 重新检查h的右侧是否仍然为空(防止并发修改)
h.right != null)
// 如果发现h右侧不为空,说明有其他线程添加了节点,尝试回滚操作
HEAD.compareAndSet(this, d, h); // try to backout
}
参考文章:https://my.oschina.net/u/3768341/blog/3135659
参考视频:https://www.bilibili.com/video/BV1Er4y1P7k1
8.6 NoBlocking
非阻塞队列
并发编程中,需要用到安全的队列,实现安全队列可以使用 2 种方式:
- 加锁,这种实现方式是阻塞队列
- 使用循环 CAS 算法实现,这种方式是非阻塞队列
ConcurrentLinkedQueue 是一个基于链接节点的无界线程安全队列,采用先进先出的规则对节点进行排序,当添加一个元素时,会添加到队列的尾部,当获取一个元素时,会返回队列头部的元素
补充:ConcurrentLinkedDeque 是双向链表结构的无界并发队列
ConcurrentLinkedQueue 使用约定:
- 不允许 null 入列
- 队列中所有未删除的节点的 item 都不能为 null 且都能从 head 节点遍历到
- 删除节点是将 item 设置为 null,队列迭代时跳过 item 为 null 节点
- head 节点跟 tail 不一定指向头节点或尾节点,可能存在滞后性
ConcurrentLinkedQueue 由 head 节点和 tail 节点组成,每个节点由节点元素和指向下一个节点的引用组成,组成一张链表结构的队列
1 | private transient volatile Node<E> head; |
构造方法
-
无参构造方法:
1
2
3
4public ConcurrentLinkedQueue() {
// 默认情况下 head 节点存储的元素为空,dummy 节点,tail 节点等于 head 节点
head = tail = new Node<E>(null);
} -
有参构造方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public ConcurrentLinkedQueue(Collection<? extends E> c) {
Node<E> h = null, t = null;
// 遍历节点
for (E e : c) {
checkNotNull(e);
Node<E> newNode = new Node<E>(e);
if (h == null)
h = t = newNode;
else {
// 单向链表
t.lazySetNext(newNode);
t = newNode;
}
}
if (h == null)
h = t = new Node<E>(null);
head = h;
tail = t;
}
8.6.1 成员方法
入队方法
与传统的链表不同,单线程入队的工作流程:
- 将入队节点设置成当前队列尾节点的下一个节点
- 更新 tail 节点,如果 tail 节点的 next 节点不为空,则将入队节点设置成 tail 节点;如果 tail 节点的 next 节点为空,则将入队节点设置成 tail 的 next 节点,所以 tail 节点不总是尾节点,存在滞后性
1 | public boolean offer(E e) { |
图解入队:



当 tail 节点和尾节点的距离大于等于 1 时(每入队两次)更新 tail,可以减少 CAS 更新 tail 节点的次数,提高入队效率
线程安全问题:
- 线程 1 线程 2 同时入队,无论从哪个位置开始并发入队,都可以循环 CAS,直到入队成功,线程安全
- 线程 1 遍历,线程 2 入队,所以造成 ConcurrentLinkedQueue 的 size 是变化,需要加锁保证安全
- 线程 1 线程 2 同时出列,线程也是安全的
出队方法
出队列的就是从队列里返回一个节点元素,并清空该节点对元素的引用,并不是每次出队都更新 head 节点
- 当 head 节点里有元素时,直接弹出 head 节点里的元素,而不会更新 head 节点
- 当 head 节点里没有元素时,出队操作才会更新 head 节点
批处理方式可以减少使用 CAS 更新 head 节点的消耗,从而提高出队效率
1 | public E poll() { |
在更新完 head 之后,会将旧的头结点 h 的 next 域指向为 h,图中所示的虚线也就表示这个节点的自引用,被移动的节点(item 为 null 的节点)会被 GC 回收



如果这时,有一个线程来添加元素,通过 tail 获取的 next 节点则仍然是它本身,这就出现了p == q 的情况,出现该种情况之后,则会触发执行 head 的更新,将 p 节点重新指向为 head
参考文章:https://www.jianshu.com/p/231caf90f30b
-
peek():会改变 head 指向,执行 peek() 方法后 head 会指向第一个具有非空元素的节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 获取链表的首部元素,只读取而不移除
public E peek() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null || (q = p.next) == null) {
// 更改h的位置为非空元素节点
updateHead(h, p);
return item;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
} -
size():用来获取当前队列的元素个数,因为整个过程都没有加锁,在并发环境中从调用 size 方法到返回结果期间有可能增删元素,导致统计的元素个数不精确
1
2
3
4
5
6
7
8
9
10
11
12public int size() {
int count = 0;
// first() 获取第一个具有非空元素的节点,若不存在,返回 null
// succ(p) 方法获取 p 的后继节点,若 p == p.next,则返回 head
// 类似遍历链表
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
// 最大返回Integer.MAX_VALUE
if (++count == Integer.MAX_VALUE)
break;
return count;
} -
remove():移除元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public boolean remove(Object o) {
// 删除的元素不能为null
if (o != null) {
Node<E> next, pred = null;
for (Node<E> p = first(); p != null; pred = p, p = next) {
boolean removed = false;
E item = p.item;
// 节点元素不为null
if (item != null) {
// 若不匹配,则获取next节点继续匹配
if (!o.equals(item)) {
next = succ(p);
continue;
}
// 若匹配,则通过 CAS 操作将对应节点元素置为 null
removed = p.casItem(item, null);
}
// 获取删除节点的后继节点
next = succ(p);
// 将被删除的节点移除队列
if (pred != null && next != null) // unlink
pred.casNext(p, next);
if (removed)
return true;
}
}
return false;
}